




Dataiku Key Capabilities
Generative AI
With Dataiku, teams can move beyond the lab and build real and safe Generative AI applications at enterprise scale. Dataiku brings streamlined development tools, pre-built use cases, and AI-powered assistants to help everyone do more with Generative AI.
ExploreData Preparation
In Dataiku, both coders and non-coders access, explore, and prepare project data in a shared space, using visual recipes, coding interfaces, and Generative AI to clean, join, transform, and enrich datasets of all types.
All steps in a data pipeline are automatically documented as part of the visual flow for transparency and ease of reuse.
EXPLOREVisualization
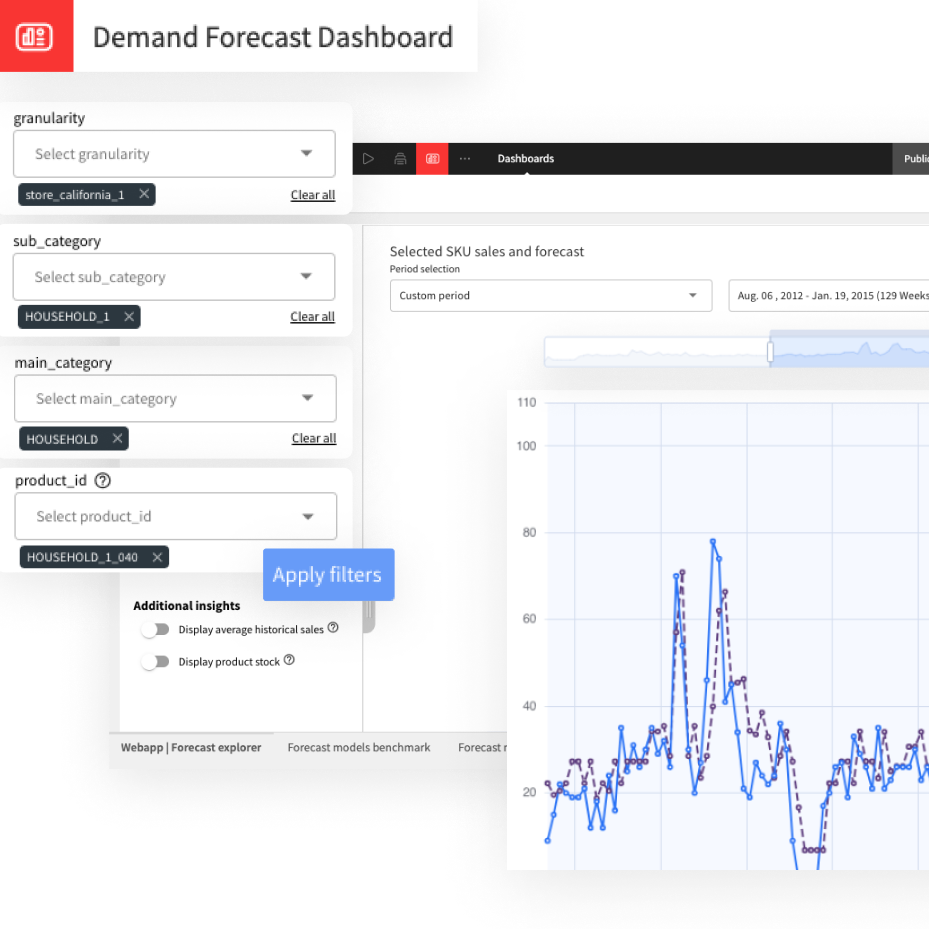
Save time on exploratory data analysis and reporting using Dataiku’s built-in capabilities for data profiling, statistical analysis, and charting. Visualize data with bar, line, and pie charts, box plots, 2D distributions, heat maps, tables, scatter plots, geo maps, custom web apps, and more.
Interactive dashboards and central workspaces make it easy to share data outputs and insights with stakeholders.
EXPLOREAI & Machine Learning
Dataiku AutoML accelerates the model development process with a guided framework for AI and machine learning including prompt engineering, prediction, clustering, time series forecasting, computer vision tasks, causal ML, and more.
The guided visual interface includes built-in guardrails, best-in-class algorithms, and white-box explainability so both novice and advanced data scientists can build and evaluate production-ready models.
EXPLOREDataOps
Each Dataiku project has a visual flow representing the pipeline of data transformations and movement from start to finish. A timeline of recent activity, automatic flow documentation, and project bundles make it easy to track changes and manage project versions in production.
Automate data pipelines and set up monitoring and alerts to ensure teams across the enterprise receive reliable and timely data.
EXPLOREMLOps
Develop, deploy, monitor, and maintain machine learning models, all in a single platform. For both batch and real time scoring, the deployer is the central place where operators can manage versions of Dataiku projects and API deployments across dev, test, and prod environments.
Automatic drift detection and retraining, experiment tracking and model comparisons, and a model evaluation store help teams make informed decisions about the best models to deploy in production.
EXPLOREAnalytic Apps
With Dataiku, it’s easy to create analytic dashboards and data products and share them with business users to support day-to-day decision making. Generative AI applications, what-if analysis with outcome optimization and interactive web apps — developed with or without code — are just a few ways to empower your organization with self-service analytics.
EXPLORECollaboration
The flow in Dataiku provides a unique collaborative environment where coders and non-coders can simultaneously contribute to data projects in a shared space.
Through central hubs like Dataiku’s catalog, feature store, home page, and shared code libraries, teams can easily discover and reuse existing data products to avoid starting from scratch each time.
EXPLOREGovernance
A central control tower tracks the status and progress of multiple data initiatives and ensures the right workflows and governance processes are in place. Standardized project workflows with structured sign-off and approvals, model and project bundle registries, and a risk/value matrix help organizations safely scale AI, including Generative AI projects, with oversight and prioritize the data projects and models that deliver the most value.
EXPLOREExplainability
Dataiku provides critical capabilities for explainable AI, including interactive reports for feature importance, partial dependence plots, subpopulation analysis, and individual prediction explanations.
Together, these techniques can help explain how a model makes decisions and enable data scientists and key stakeholders to understand the factors influencing model predictions.
EXPLOREArchitecture
Dataiku integrates with your existing infrastructure — on-premises or in the cloud — taking advantage of each technology’s native storage and computational layers. With fully managed elastic AI powered by Spark and Kubernetes, you can achieve maximum performance and efficiency on large workloads.
Additionally, Dataiku provides a fully hosted SaaS option built for the modern cloud data stack and integrates with a variety of AI services, including leading Generative AI offerings.
EXPLORESecurity
Manage risk with enterprise-grade security, including authentication with SSO and LDAP, role-based access control, audit trails, and multiple fine-grained permissions that can operate at the user, connection, project, compute, and global levels.
Dataiku’s user isolation framework (UIF) provides a set of mechanisms to isolate user-written code in various contexts, performing advanced identity mapping that guarantees traceability and prevents hostile attacks.
ExploreExtensibility
Expand Dataiku’s native capabilities with public and proprietary plugins and custom applications, which allow you to package your specialized code and subflows as reusable visual components.
Use visual or programmatic tooling to seamlessly incorporate leading AI Services for NLP, Computer Vision, and Generative AI into Dataiku projects.
Explore