Run enterprise AI as one system
Operate agents, analytics, and models in a single governed system. Orchestrate teams, reuse intelligence, and scale AI across the enterprise without fragmentation or loss of control.

Orchestrate teams, systems, and intelligence at scale
Scale every AI initiative as part of a single, connected system across your enterprise.
Connect to any source
Access and combine data from cloud platforms, warehouses, storage systems, and business applications securely and with governance enforced by default.
Deploy AI on your terms
Operate AI workloads on premises, in the cloud, or hybrid. Use SaaS for speed or self-managed deployments for control without changing how teams work.
Extend and embed across the enterprise
Integrate AI directly into business systems and workflows using custom extensions and a broad partner ecosystem accelerating adoption and impact.
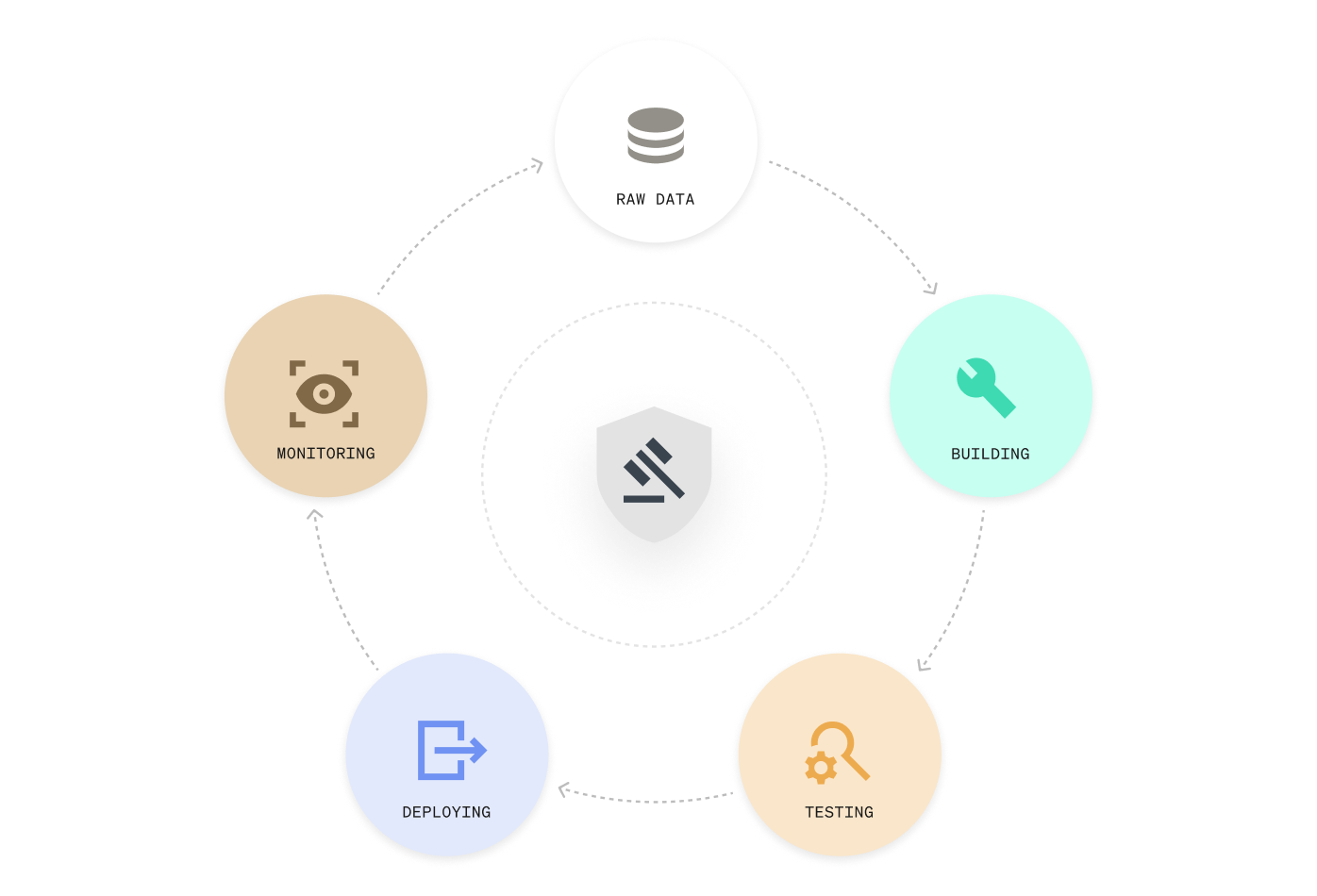
One system for the full AI lifecycle
Build, deploy, monitor, and govern analytics, models, and agents in one environment. No handoffs, blind spots, and control gaps.
Build with the right tools for every role
Support visual workflows for analysts and full-code development for data scientists and engineers.
Operationalize without friction
Deploy pipelines, APIs, and applications to any infrastructure with built-in orchestration. No rewrites, no migrations, no workarounds.
Centralized visibility and oversight
Monitor pipelines, models, agents, performance, and cost from one place maintaining enterprise-wide visibility and control.
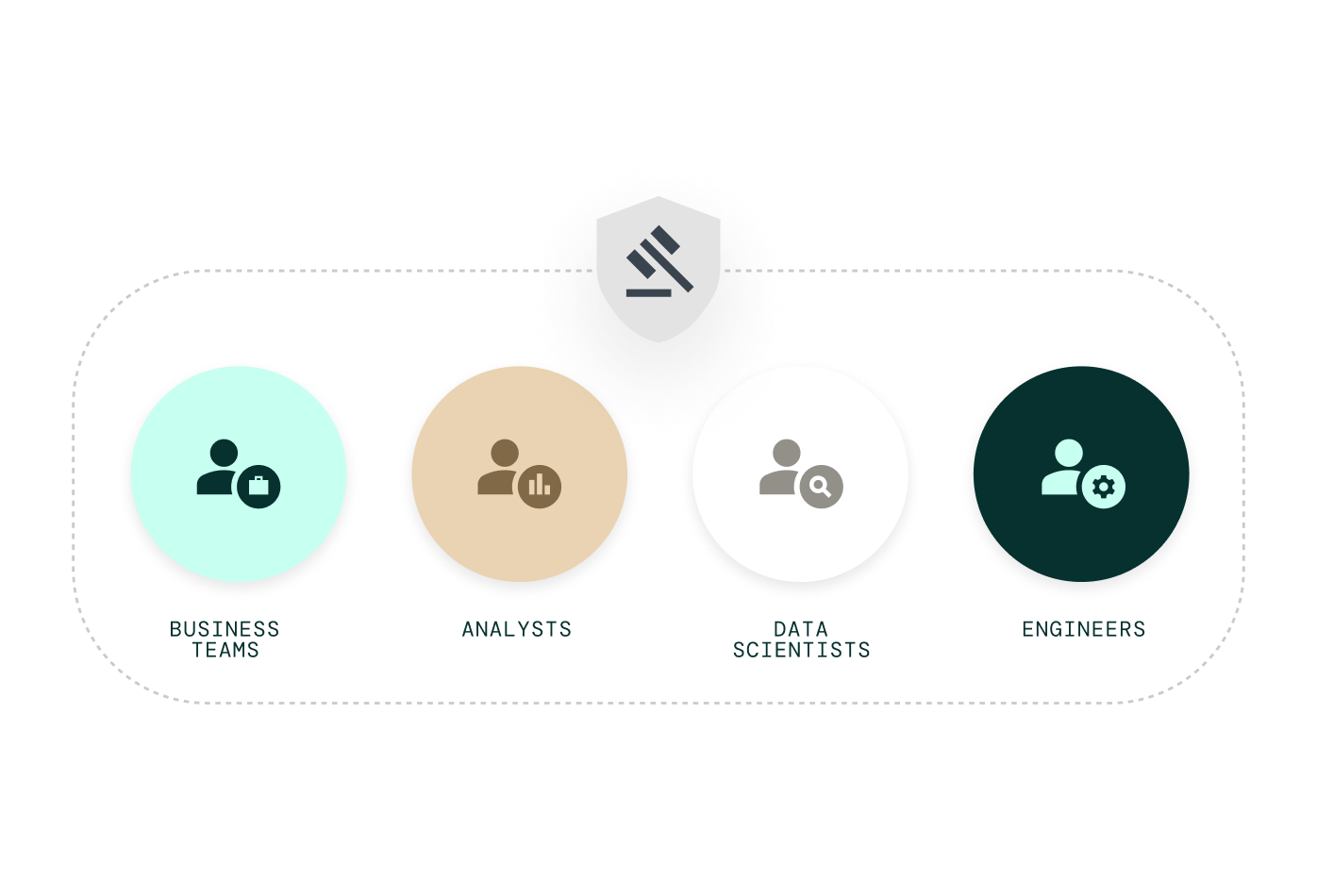
One governed system for every team
Bring business teams, analysts, data scientists, and engineers into one governed system so work flows across roles without translation or rework.
Dataiku E2A (Expert-to-Agent)
Scale expertise with production-ready AI agents grounded in enterprise data, structured reasoning, and human oversight.
Reuse intelligence across the organization
Share datasets, features, prompts, models, and workflows across projects turning individual efforts into enterprise assets.
Support every skill level without fragmentation
Enable business users, analysts, and engineers to contribute in one IT-owned environment with role-appropriate tools and shared standards.