Go Faster or Get Started With AutoML
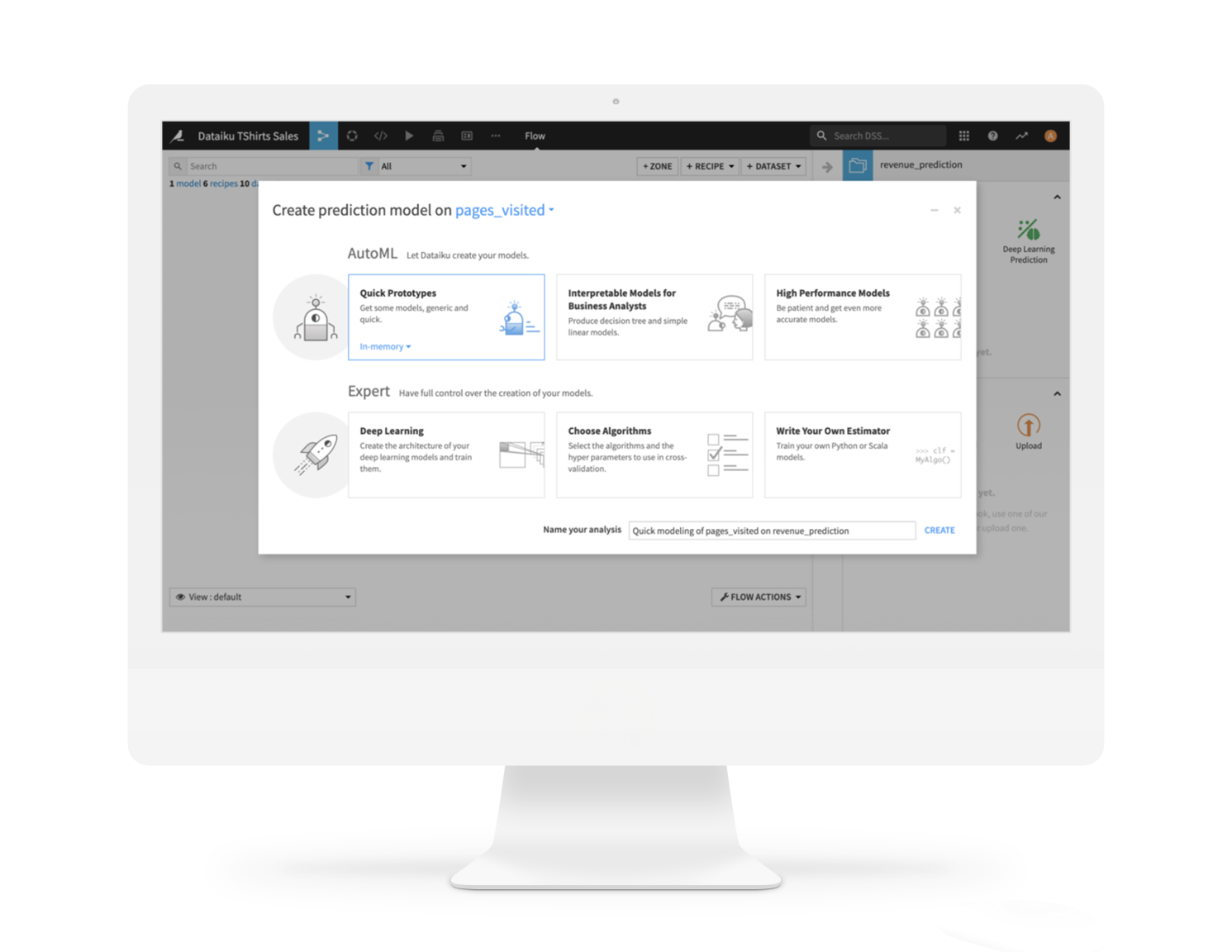
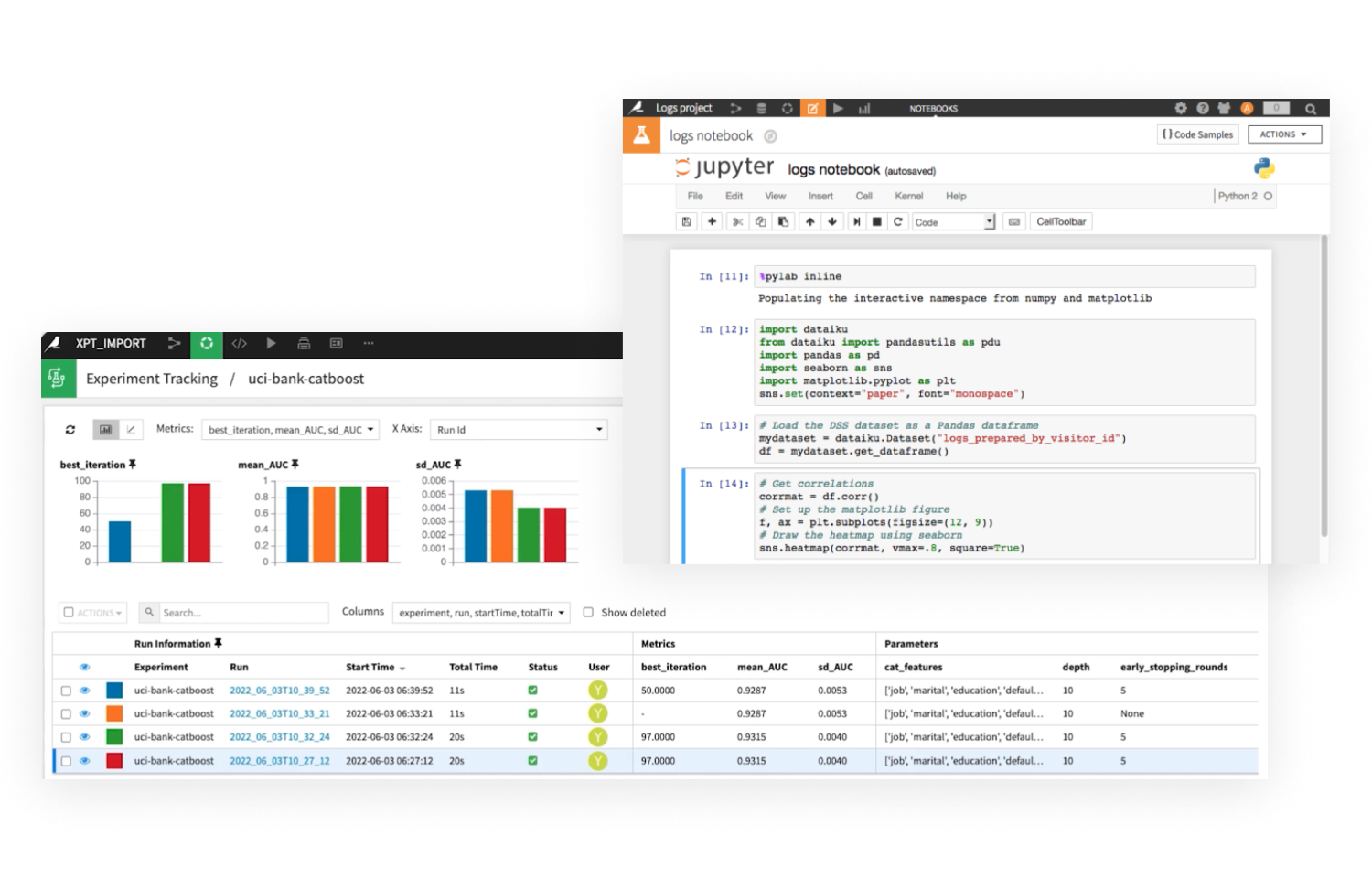
Dataiku combines the simplicity of AutoML for fast prototyping with more advanced visual ML capabilities for creating sophisticated models — fast.
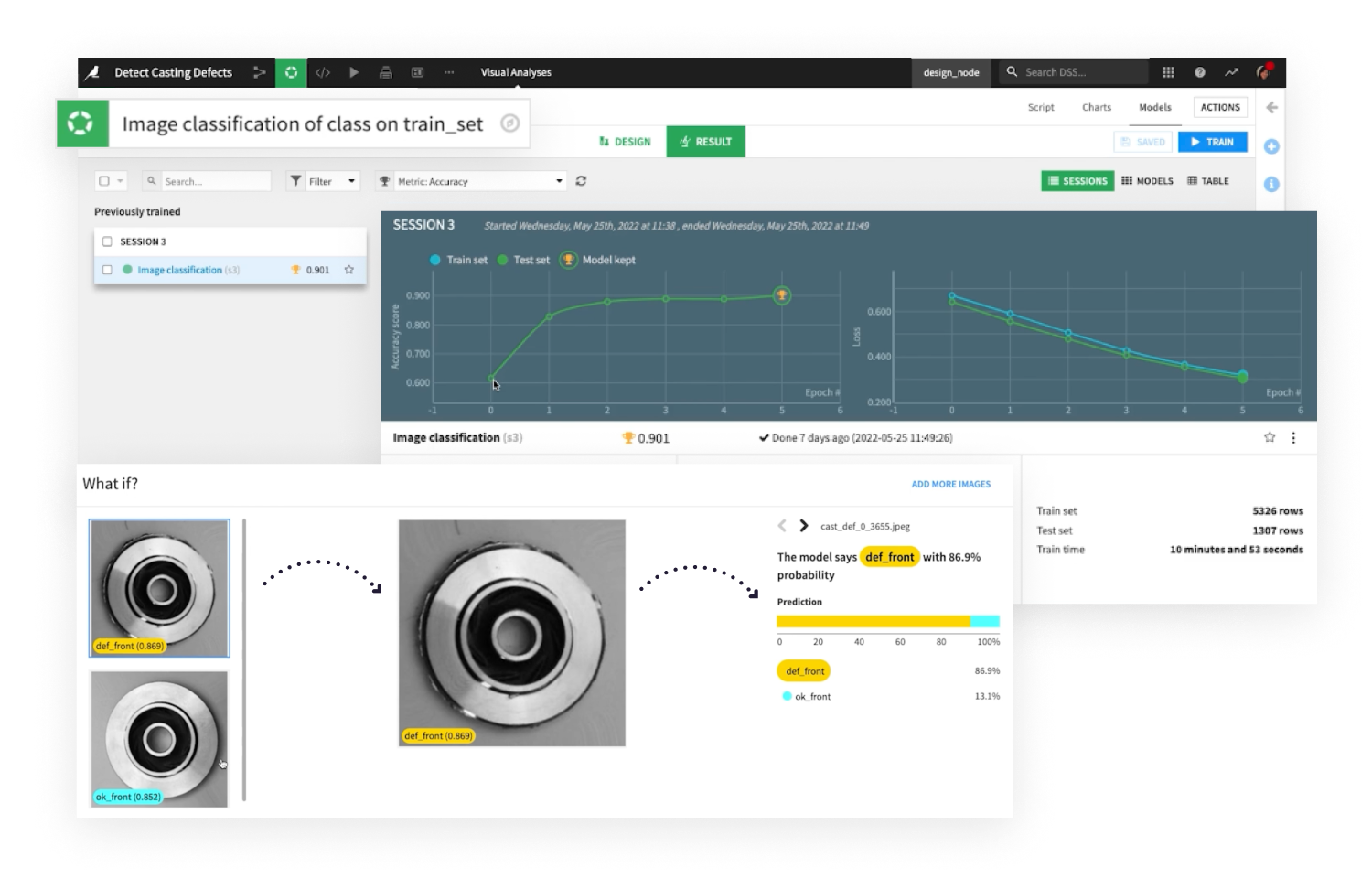
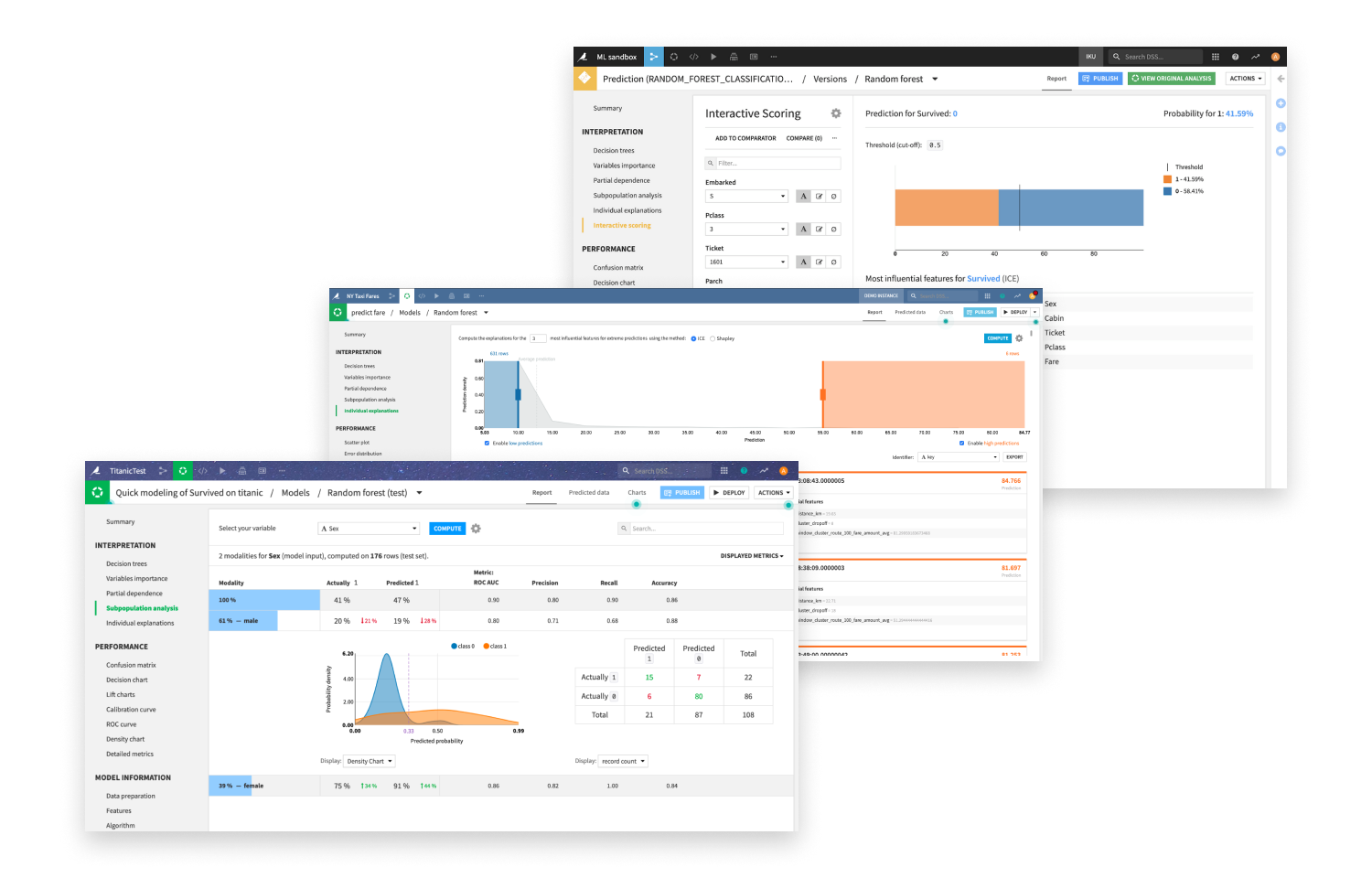
From prediction, clustering, and time series forecasting to causal ML and computer vision, data scientists and analysts alike can build and compare production-ready models quickly and with white-box explainability.
Dive Deeper on Dataiku AutoML Features