Enterprise MLOps platform by Dataiku
Deploy, monitor, and manage machine learning (ML) models seamlessly throughout the AI lifecycle with Dataiku.

Deploy anywhere
Push models to production across SageMaker, AzureML, Databricks, Snowflake, and more from one place.
Automated compliance
Automatically generate model documentation, run stress tests, and maintain version control for every deployment.
Active monitoring
Track performance metrics, catch drift early, and automate retraining to keep models accurate in production.
Integrate MLOps across your enterprise ML ecosystem
Integrate MLOps in Dataiku seamlessly with leading platforms (including AWS SageMaker, AzureML, Databricks, Google VertexAI, and Snowflake) for full, ecosystem-wide visibility to manage diverse projects without compromising on governance or control.
Dataiku Unified Monitoring provides a centralized view of model health and drift status, ensuring that teams stay informed on all deployments, no matter the infrastructure.
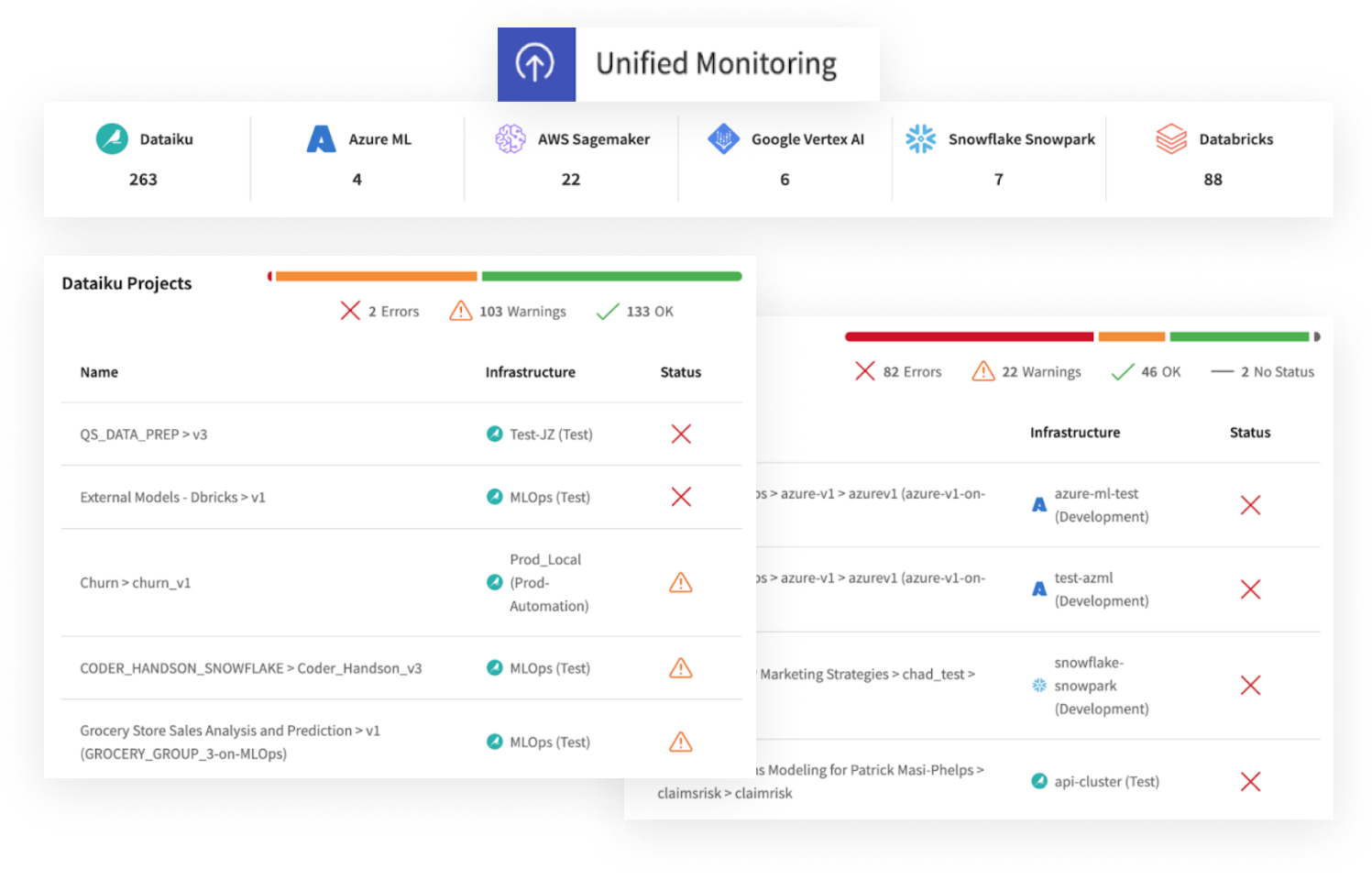
Ensure governed, compliant MLOps with automated documentation and stress testing
Dataiku simplifies model governance by automatically generating documentation, ensuring compliance and making every project reproducible. Dataiku allows users to conduct model stress testing before deployment, helping teams validate performance and identify potential vulnerabilities — ensuring reliable outcomes.
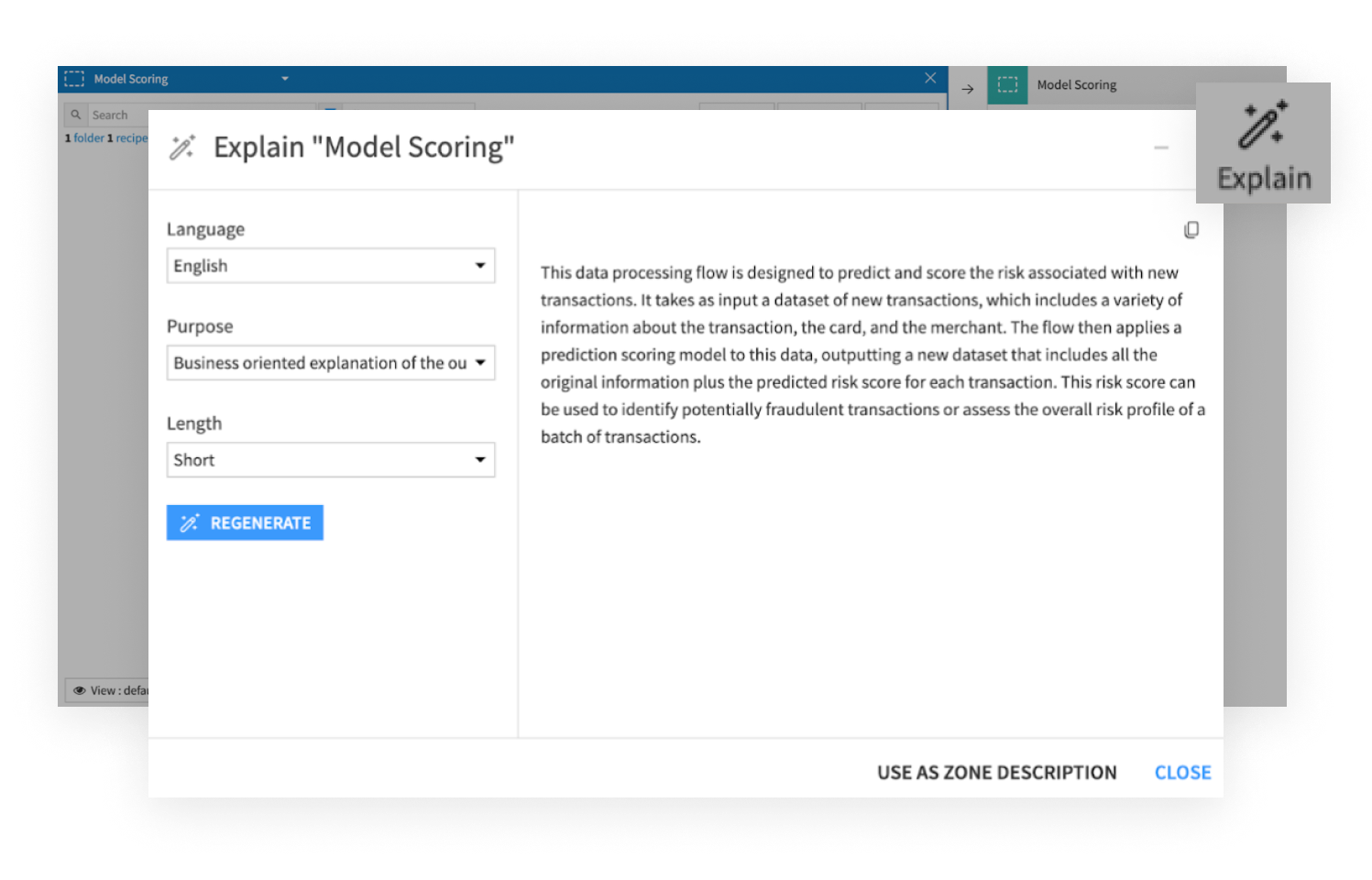
Integrate MLOps pipelines with existing CI/CD workflows
With the Dataiku Python API, IT teams and engineers can execute Dataiku tasks programmatically and integrate them into existing DevOps pipelines using tools like Jenkins, GitLabCI, Travis CI, or Azure DevOps.
Have continuous delivery by enabling model deployment and monitoring workflows to operate alongside established development practices, ensuring that AI projects remain agile and aligned with software engineering processes.
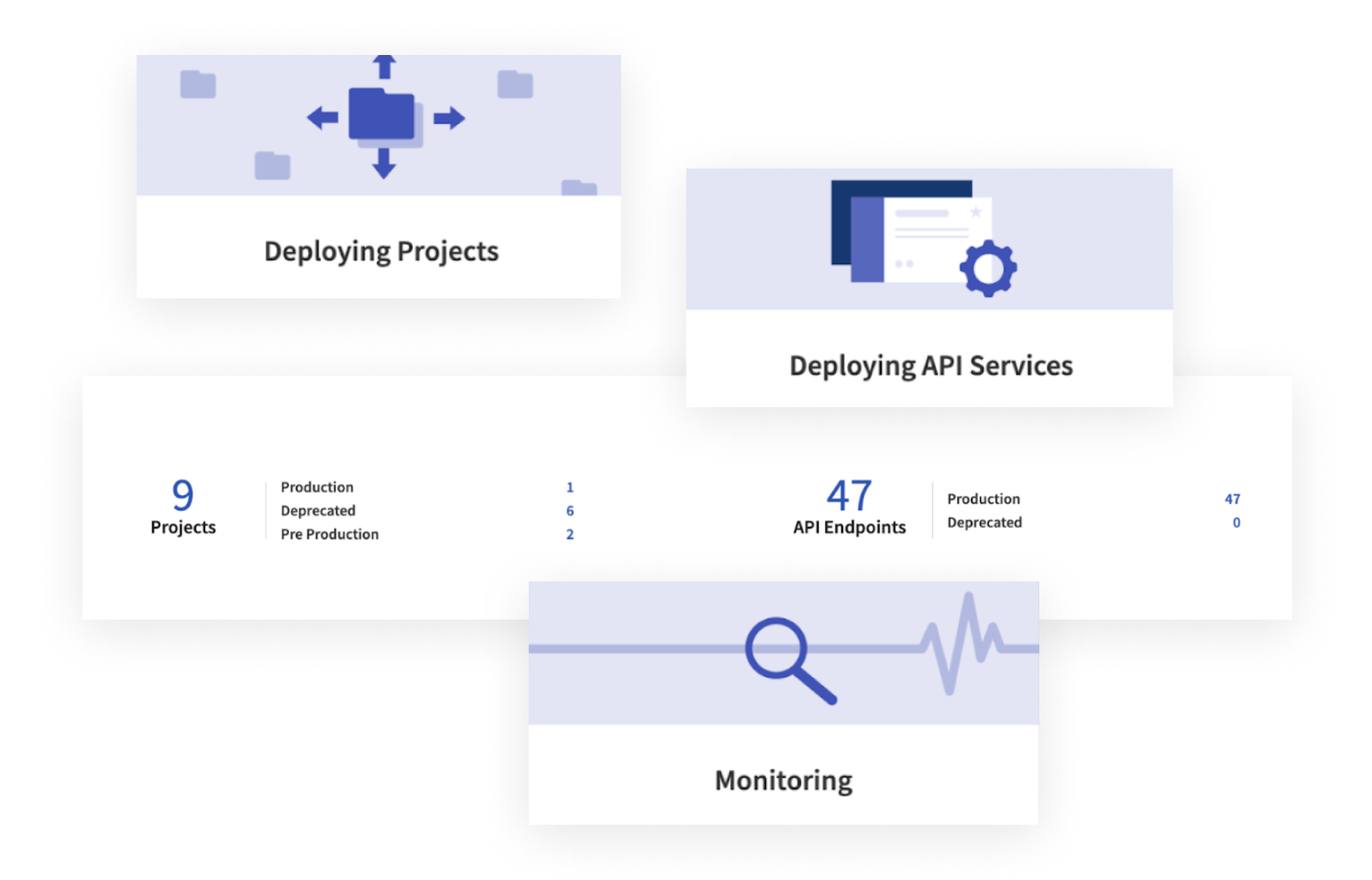
Deploy machine learning models reliably at scale
Deploy and manage models for both real-time and batch use cases across various infrastructures and environments.
Whether models require real-time predictions via APIs or scheduled batch processing, Dataiku ensures smooth deployments with full configuration to maintain operational stability.
Monitor ML model performance and detect model drift
The Dataiku model evaluation store captures key metrics for visualizing model behavior over time. That means insights into when models might drift or deteriorate, allowing for proactive interventions.
With these metrics, teams can create checks and automate alerts for drift detection to take timely actions (e.g., retraining), keeping models accurate and aligned with business outcomes.
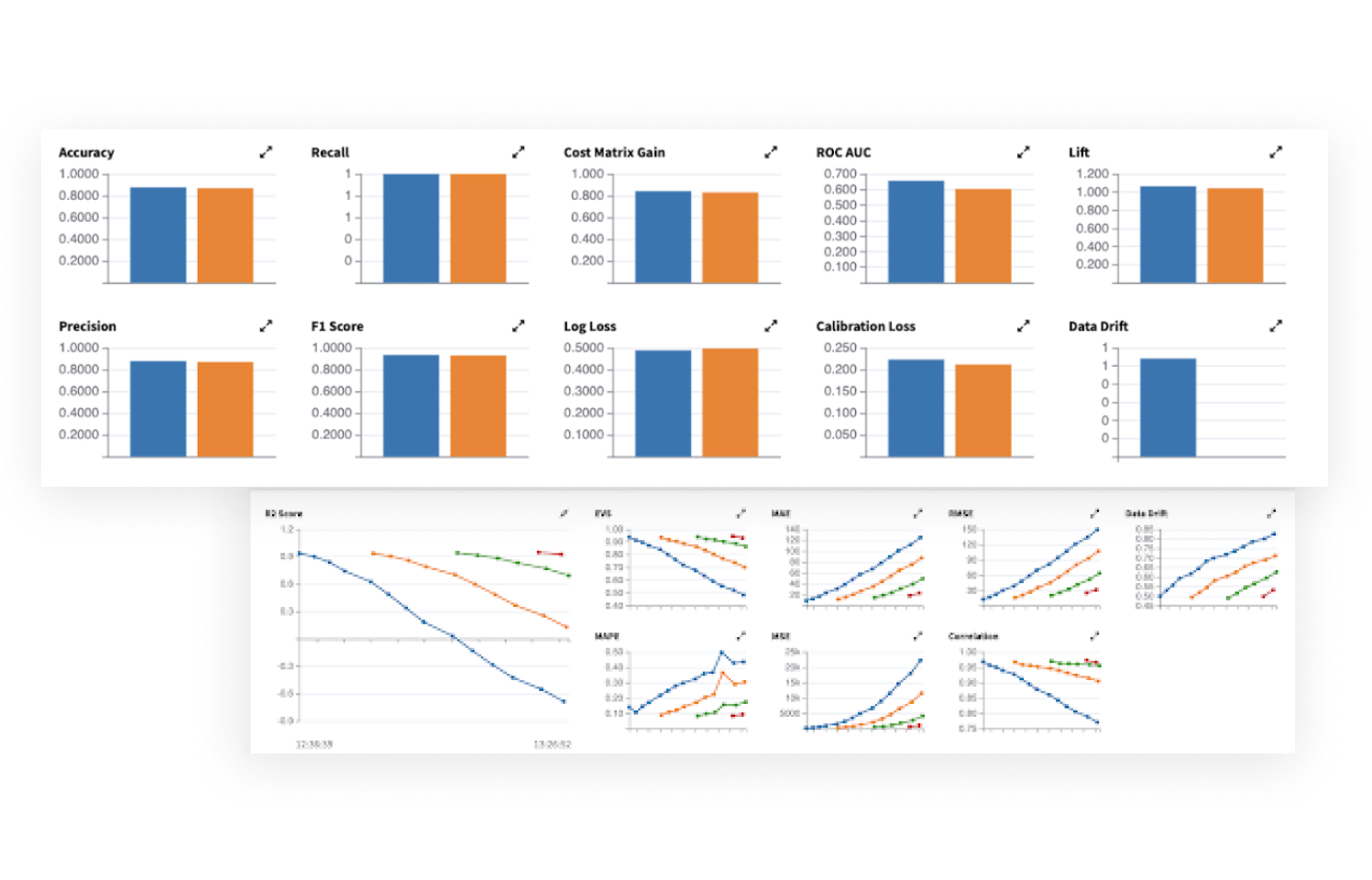
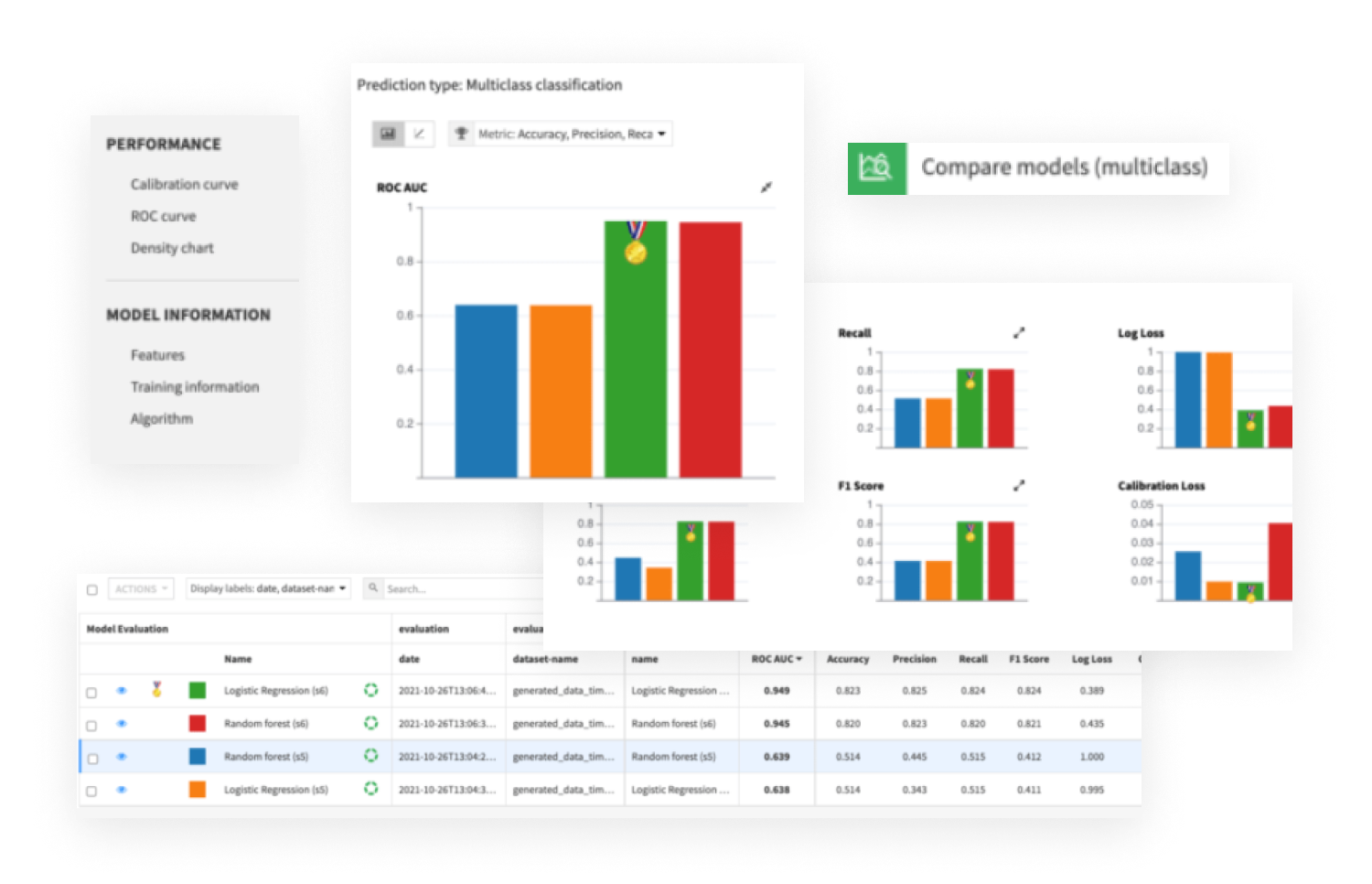
Version, retrain, and compare ML models
With Dataiku, maintain version control over all models and easily evaluate different versions through champion/challenger comparison. This ensures that model updates are intentional and measurable, supporting better decision making.
In case of performance issues or drift, teams can easily revert to previous versions, ensuring continuity and minimizing risks in production environments.
Loved by customers and recognized by analysts
“The platform is intuitive, collaborative, and streamlines workflows from data prep to model deployment. Dataiku has truly transformed how we handle data!”
Data scientist
Retail
Start your Dataiku 14-day trial
Experience the Platform for AI Success in a fully managed workspace, ready in minutes. Form not loading? Please reload the page.