

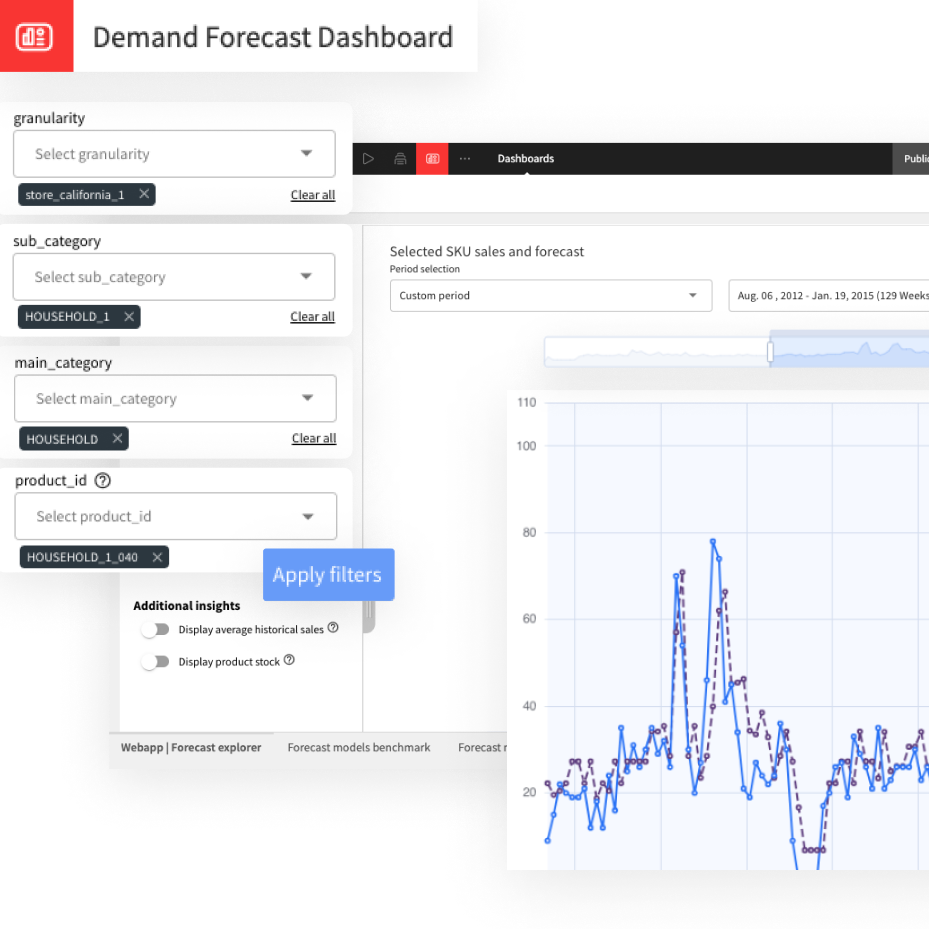



Plugin information
| Version | 0.2.0 |
|---|---|
| Author | Dataiku (Jane BELLAICHE, Alex COMBESSIE) |
| Released | 2021-06 |
| Last updated | 2023-04 |
| License | Apache Software License |
| Source code | Github |
| Reporting issues | Github |
With this plugin, you can tag documents matching keywords within a corpus of text documents
Table of contents
How to set up
After installing the plugin, you need to build its code environment.
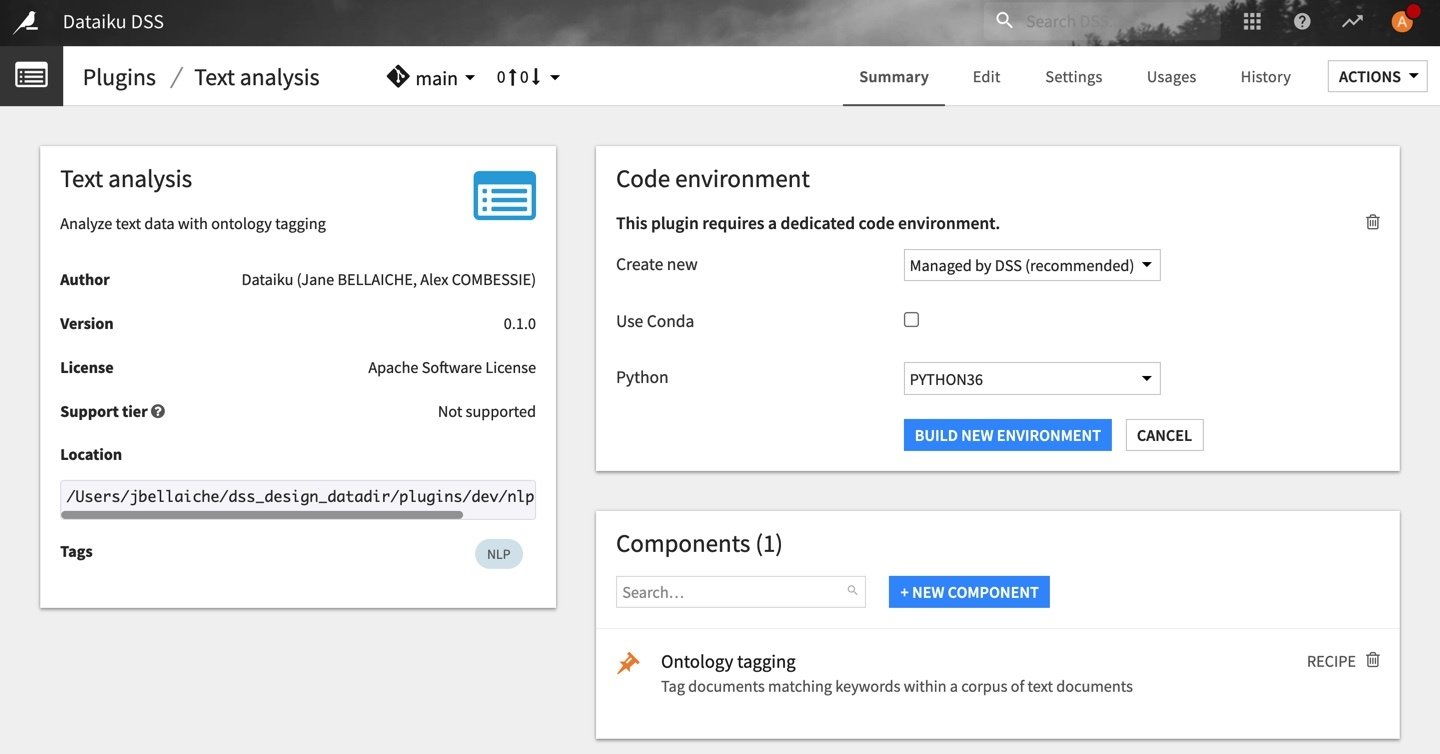
Note that Python version 3.6 or 3.7 is required.
To use this plugin with containers, you will need to customize the base image. Please follow this documentation with this Dockerfile fragment.
How to use
Let’s assume that you have a Dataiku DSS project with a dataset containing raw text data in one or more languages. This text data must be stored as a single column in the dataset, with one row for each document.
To create your first recipe, navigate to the Flow, click on the + RECIPE button and access the Natural Language Processing menu. If your dataset is selected, you can directly find the plugin on the right panel.
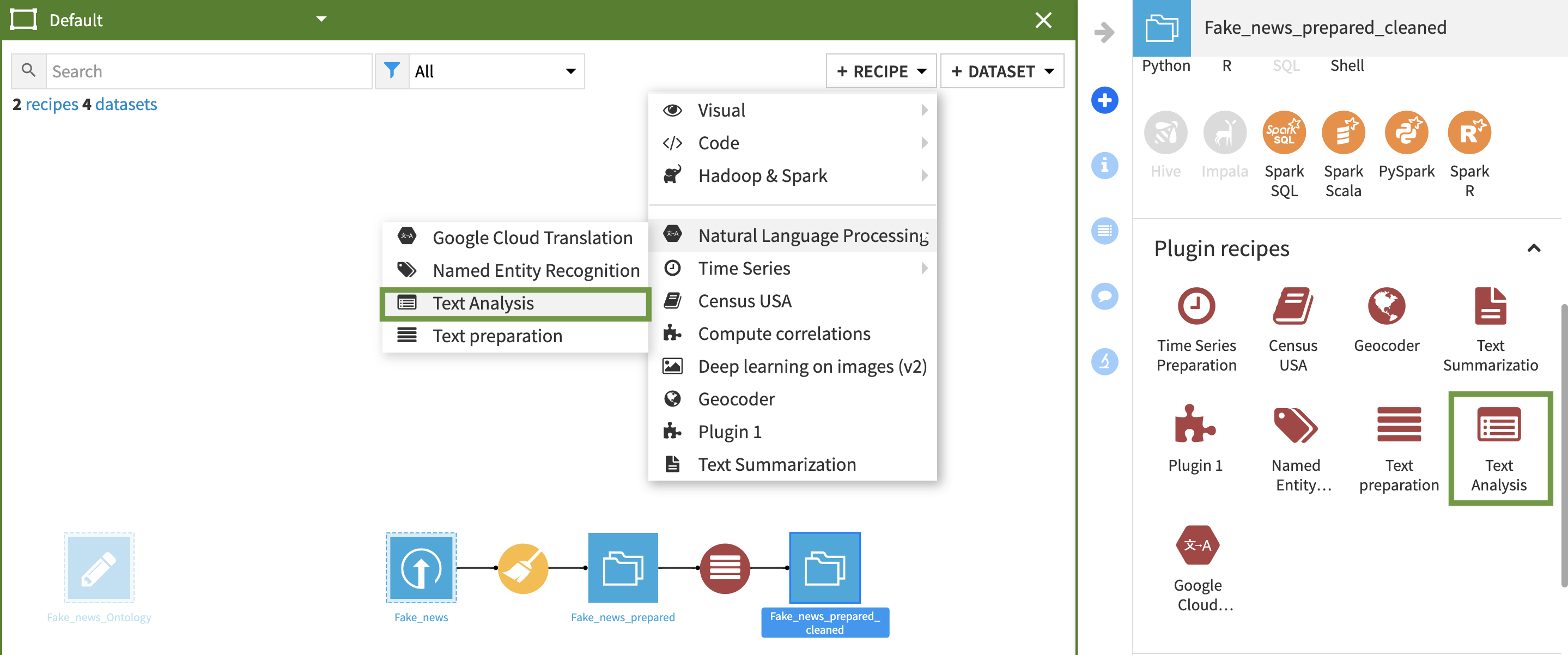
Ontology tagging recipe
Assign tags to documents matching keywords within a corpus of text documents
Inputs
- Document dataset: Dataset with a text column, and potentially a language column
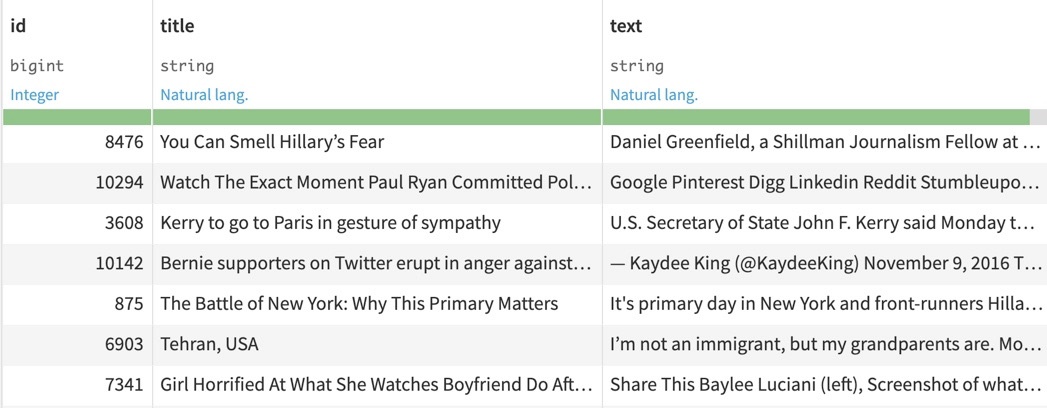
- Ontology dataset
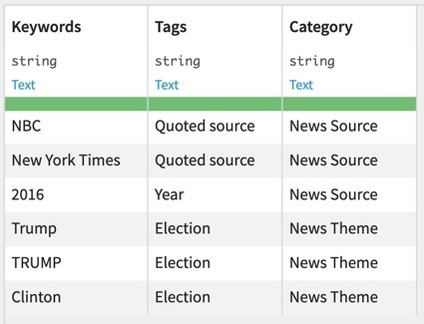
You will also need to create or import a dataset composed of the following columns:- a column such as “keywords”, which are the terms that will be searched for in the corpus of documents.
- a column such as “tags”, which are the tags you wish to assign to your documents. A tag can be linked to a set of keywords.
- (Optional) a column such as “category”, which are the categories you wish to group your tags by. All tags without categories will later be classified as “uncategorized”.
Settings
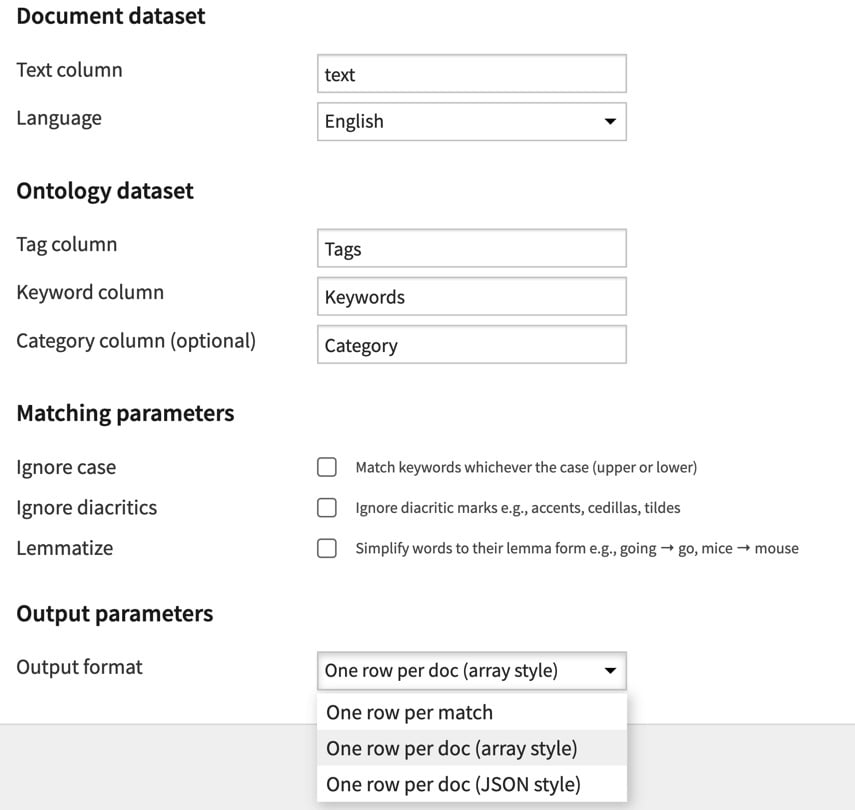
- Document dataset
- Text column: name of the column containing the text to be tagged
- Language: the language parameter lets you choose among 59 supported languages if your documents are monolingual. Else, the Multilingual option will let you specify an additional Language column, that is expected to contain the ISO 639-1 language code corresponding to each document.
- Ontology dataset
- Tag column: name of the tag column
- Keyword column: name of the keyword column
- (Optional) Category column: name of the category column
- Matching Parameters
You can widen the search by activating the following matching parameters:- Ignore case: To match documents by ignoring case (e.g will try to match ‘guitar’, ‘Guitar’, ‘GUITAR’)
- Ignore diacritics: To match documents by ignoring diacritics marks such as accents, cedillas, tildes
- Lemmatize: To match documents by simplifying words to their lemma form (e.g., going → go, mice → mouse).
- Output parameters
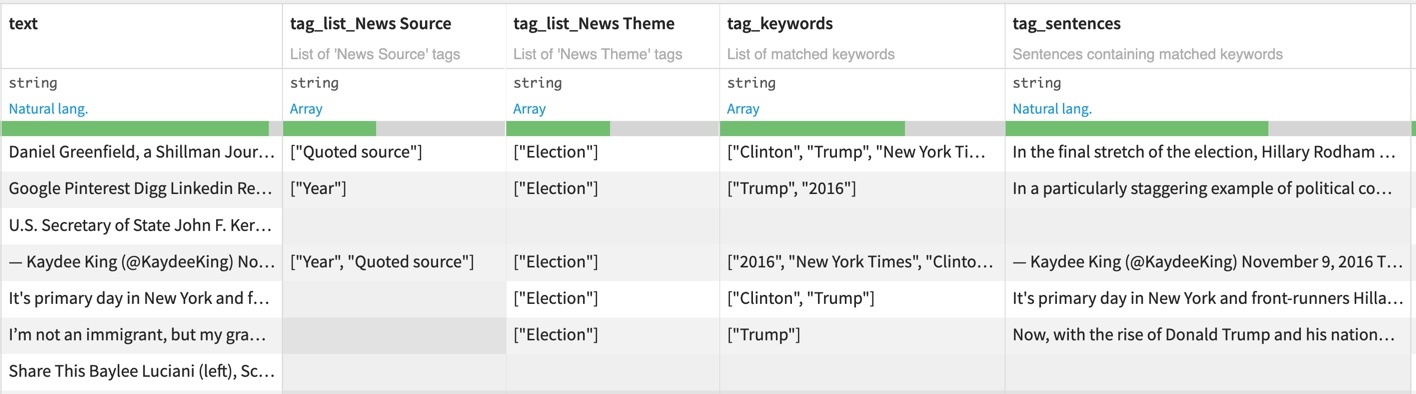
There are three available output formats. All the output formats preserve the initial data of the input dataset- Default output “One row per document (array style) ”: A row for each document, with additional columns:
- tag_list column: the assigned tags of the document (array-like). If you gave a category column in the matching parameters, you will have one column per category, each one containing a list of associated tags
- tag_keywords column: the keywords that matched the document (array-like)
- tag_sentences column: the concatenated sentences that matched the keywords (string-like).
- Output “One row per document (JSON style) ”: A row for each document, with additional output columns:
- tag_json_full column: a dictionary with details about occurrences for each tag, matched keywords for each tag, and the sentences where they appear. (object-like)
- If you gave a category column in the matching parameters, you will also have a column tag_json_categories (object-like), which is a simplified version of the previous dictionary containing categories (keys) and associated tags (values)
- Output “One row per match ”: A row per match per document. This mode may create an output dataset with more rows than the input dataset, as you may have multiple matching keywords in a single document, which would result in duplication of that document in the output for each matched keyword. In this case, the additional output columns would be:
- tag column: a tag column (string-like)
- keyword column: a keyword column (string-like)
- sentence column: a sentence column (string-like)
- category column: (Optional) a category column (string-like)
- Default output “One row per document (array style) ”: A row for each document, with additional columns:
Output
- Dataset with assigned tags for each document
Advanced topics
Supported languages
Ontology tagging
Here are the 59 supported languages and their ISO 639-1 format :
- Afrikaans (af) *
- Albanian (sq) *
- Arabic (ar) *
- Armenian (hy) *
- Basque (eu) *
- Bengali (bn)
- Bulgarian (bg) *
- Catalan (ca)
- Chinese (simplified) (zh) *
- Croatian (hr)
- Czech (cs)
- Danish (da)
- Dutch (nl)
- English (en)
- Estonian (et) *
- Finnish (fi) *
- French (fr)
- German (de)
- Greek (el)
- Gujarati (gu) *
- Hebrew (he) *
- Hindi (hi) *
- Hungarian (hu)
- Icelandic (is) *
- Indonesian (id)
- Irish (ga) *
- Italian (it)
- Japanese (ja) *
- Kannada (kn) *
- Latvian (lv) *
- Lithuanian (lt)
- Luxembourgish (lb)
- Macedonian (mk)
- Malayalam (ml) *
- Marathi (mr) *
- Nepali (ne) *
- Norwegian Bokmål (nb)
- Persian (fa)
- Polish (pl)
- Portuguese (pt)
- Romanian (ro)
- Russian (ru)
- Sanskrit (sa) *
- Serbian (sr)
- Sinhala (si) *
- Slovak (sk) *
- Slovenian (sl) *
- Spanish (es)
- Swedish (sv)
- Tagalog (tl)
- Tamil (ta) *
- Tatar (tt) *
- Telugu (te) *
- Thai (th) *
- Turkish (tr)
- Ukrainian (uk) *
- Urdu (ur)
- Vietnamese (vi) *
- Yoruba (yo) *
* Lemmatization not supported