





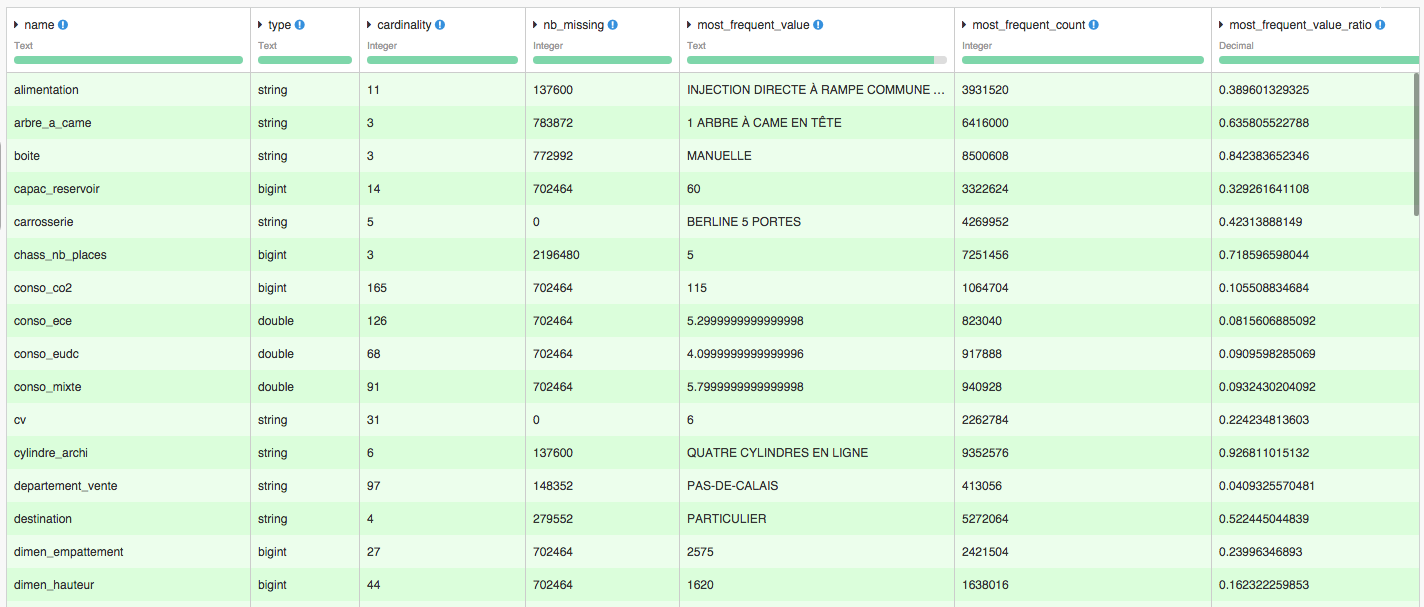
This plugin provides a recipe that takes a SQL-based or HDFS-based dataset as input, and outputs an audit of the data in the input dataset.
The output is a dataset with one line per column in the input dataset. For each column, the recipe outputs:
- Type
- Cardinality (number of distinct values)
- Number of missing/empty values
- Most frequent value and most frequent value count
- For numerical columns: min, max, avg
The recipe uses in-processing or in-Hadoop processing, as appropriate for the input dataset
Plugin Information
| Version | 0.0.6 |
|---|---|
| Author | Dataiku |
| Released | 2015/11/13 |
| Last updated | 2024/01/30 |
| License | Apache Software License |
| Source code | Github |
| Reporting issues | Github |
More information about the plugin is available in the Github repository