





Plugin information
| Version | 1.1.0 |
|---|---|
| Author | Dataiku (Jérémy PLASSMANN) |
| Released | 2021-09-13 |
| Last updated | 2023-04-27 |
| License | Apache Software License |
| Source code | Github |
| Reporting issues | Github |
This plugin lets you transcribe audio files using Amazon Transcribe.
Note that the Amazon Transcribe API is a paid service, check their API pricing page for more information.
How to set up
If you are a Dataiku and AWS (Amazon Web Services) admin user, follow these configuration steps right after you install the plugin. If you are not an admin, you can forward this to your admin and scroll down to the How to use section.
1. Create a privileged IAM User for Amazon Transcribe in the AWS Console
In order to use the Amazon Transcribe API, you need an AWS account. If you don’t have one yet, you can sign up for the free tier here.
Next, you need to create credentials with the necessary permissions using AWS Identity and Access Management (IAM). If you don’t have an IAM user yet, create one first:
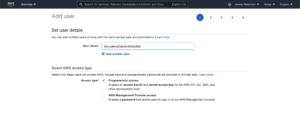
Next, grant the user access to Amazon Transcribe by giving them privileges directly, or by assigning them to a group.
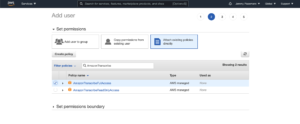
Make sure to take note of the Access key ID & Secret access key which will appear after creation. Once you have an IAM user with the necessary privileges, you just need to provide DSS with the credentials.
2. Create an API configuration preset – in Dataiku DSS
In Dataiku DSS, navigate to the Plugin page > Settings > API configuration and create your first preset.
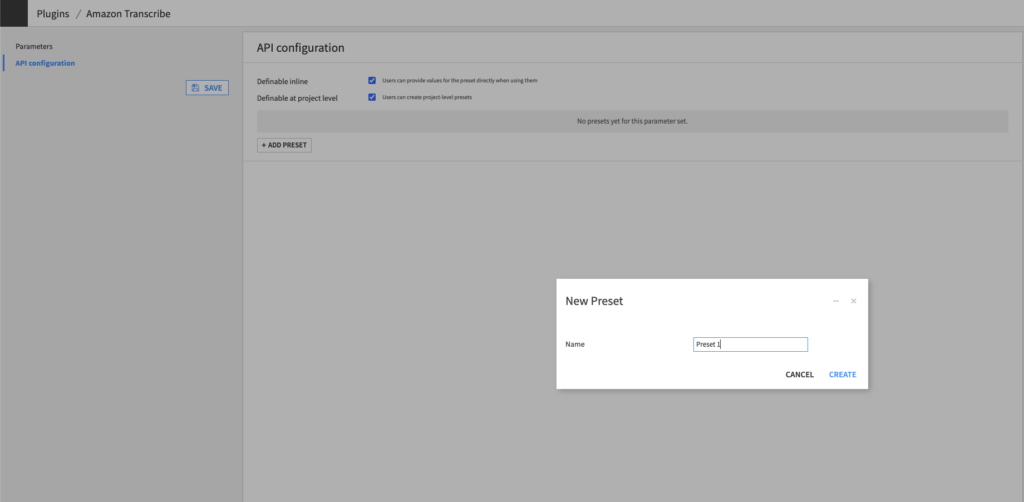
3. Configure the preset – in Dataiku DSS
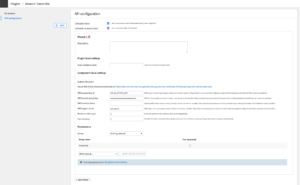
- Fill the AUTHENTICATION settings
- Enter your AWS Access key id & AWS secret access key in the corresponding fields. Leave the session token empty if you don’t have one. Next choose a region from the AWS availability regions.
- Alternatively, you may leave the fields empty so that the credentials are ascertained from the server environment. If you choose this option, please make sure the credentials are defined in the environment such as via a .bashrc file. Note that this option will not work in a User Isolation Framework (UIF) setup.
- (Optional) Review the PARALLELIZATION and ATTEMPTS settings
- The default Concurrency parameter means that 4 threads will call the API in parallel.
- We do not recommend changing this default parameter unless your server has a much higher number of CPU cores.
- The default Maximum Attempts means that if an API request fails, it will be tried another 3 times.
- Regardless of why the request fails (e.g. an access error with your AWS account or a throttling exception due to too many concurrent requests), it will be tried again.
- Note that AWS may charge you depending on the nature of the error, for each additional attempt.
- The default Concurrency parameter means that 4 threads will call the API in parallel.
- Set the Permissions of your preset
- You can declare yourself as the Owner of this preset and make it available to everybody, or to a specific group of users.
- Any user belonging to one of these groups on your Dataiku DSS instance will be able to see and use this preset.
Voilà! Your preset is ready to be used.
Later, you (or another Dataiku admin) will be able to add more presets. This can be useful to segment plugin usage by user group. For instance, you can create a “Default” preset for everyone and a “High performance” one for your Marketing team, with separate billing for each team.
How to use
Let’s assume that you have installed this plugin and that you have a Dataiku DSS project with a folder hosted on S3 bucket containing the audio files to transcribe.
Input
- Remote Folder hosted on a S3 bucket on the same account as the one of Amazon Transcribe containing the audio files to process
- Only the files in the format FLAC, MP3, MP4, Ogg, WebM, AMR, or WAV are taken into account.
- The file has to last less than 4 hours in length and less than 2 GB in size (500 MB for call analytics jobs)
Amazon Transcribe recipe
To create your first recipe, navigate to the Flow, click on the + RECIPE button and access the Natural Language Processing menu. If your folder is selected, you can directly find the plugin in the right panel.
Settings
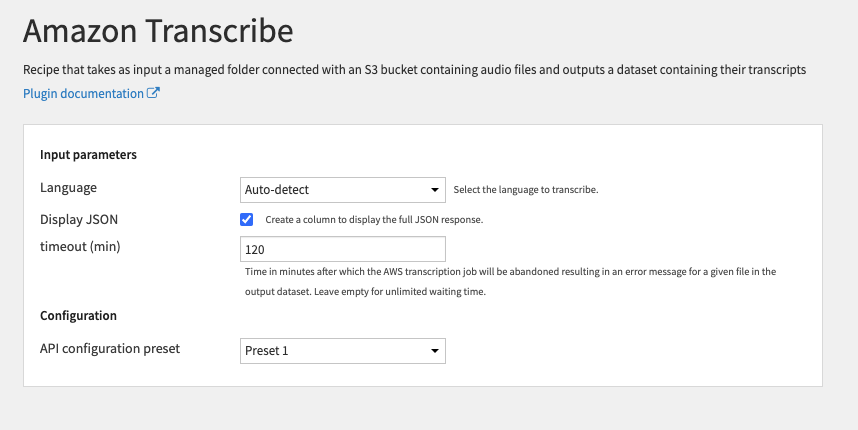
- Review INPUT parameters
- The language parameter is the original language of the audio files . If you would like the transcribe api to infer the original language, you can select the Auto-detect option.
- Find the available languages here.
- Check Display JSON checkbox if you want a column with the raw JSON results of the transcription.
- The Timeout parameter is the maximum time to wait for an audio file to be transcribed, if this the job is longer than that time, the result will not be shown in the dataset. However, the JSON file will appear in the output folder. Leave it empty if you don’t want a timeout.
- The language parameter is the original language of the audio files . If you would like the transcribe api to infer the original language, you can select the Auto-detect option.
- Review CONFIGURATION parameters
- The Preset parameter is automatically filled by the default one made available by your Dataiku admin. You may select another one if multiple presets have been created.
Output
- Dataset with text transcribed from the audio files
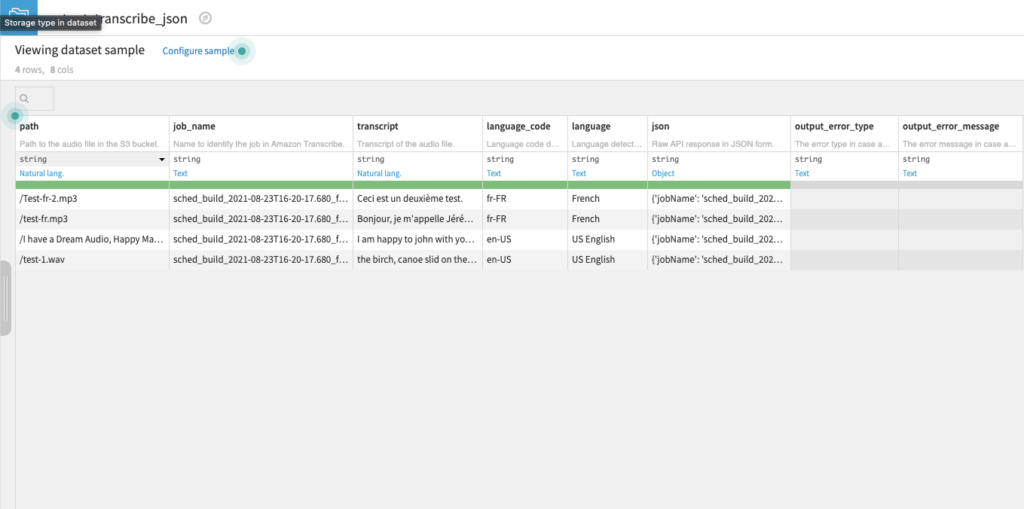
The columns of the output dataset are as follows:
- path
- Path to the audio file in the S3 bucket
- job_name
- Name to identify the job in Amazon Transcribe
- transcript
- Transcript of the audio file
- language
- Language detected or setup by the user
- language_code
- Language code detected or setup by the user
- (Optional) json
- Raw API response in JSON form
- output_error_type
- The error type in case an error occurs
- output_error_message
- The error message in case an error occurs
- (Optional) Output folder to put the JSON results from Amazon Transcribe
- Remote folder hosted in an AWS S3 bucket. This folder will be written by Amazon Transcribe by putting the JSON results in this folder when the jobs are done. The plugin will then read that folder to put it in the output dataset.
- This output folder is optional, if you decide to not give an output folder to the plugin, the results are written in the input folder. Make sure it has the write permissions.
Happy natural language processing!