


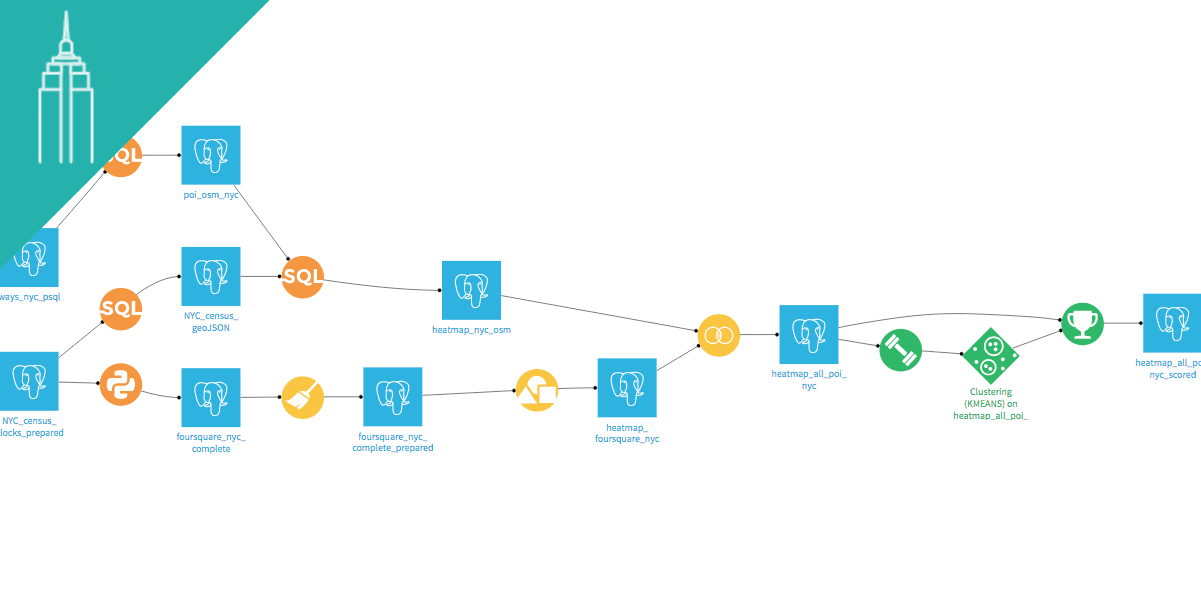
Flow
Start by looking at the flow and visualizing the different steps of the project. You can see the preparation steps in yellow and the modeling steps in green.
EXPLORE !
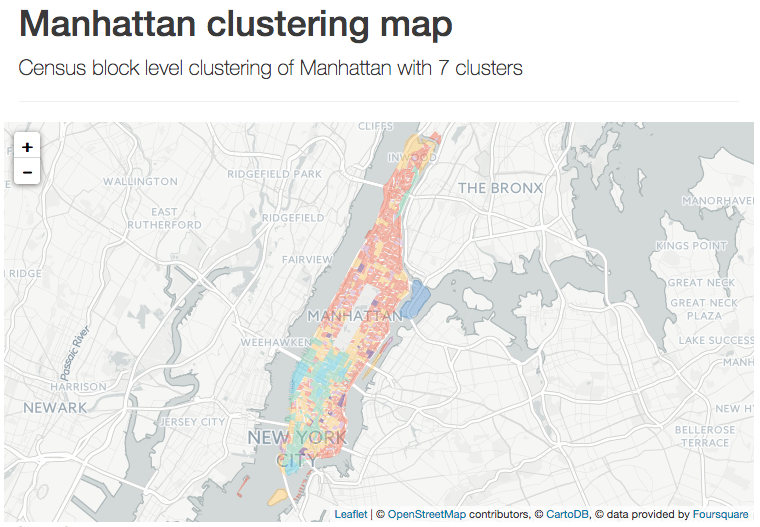
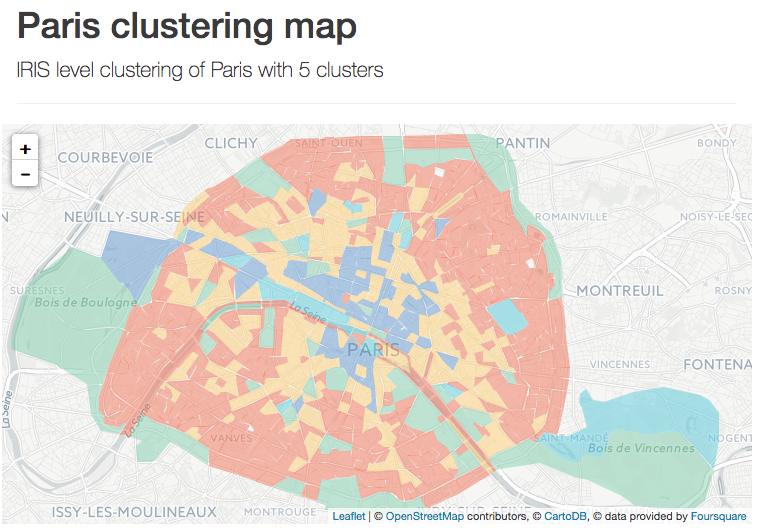
This sample project is based on data from Open Street Map and Foursquare, that we associate with the neighborhoods of the borough of Manhattan and of the city of Paris.
We aggregate points of interest (POI) by type and count how many venues are present in each neighborhood. Based on this data we run an unsupervised machine learning algorithm to cluster the neighborhoods.
We have two datasources: Open Street Maps and Foursquare
We will use the census block dataset from the data portal of the city of New York City as a grid for the borough of Manhattan.
We will use the IRIS dataset from the French statistics institute as a grid for the city of Paris. They represent “small neighborhoods” encompassing 1,800 to 5,000 inhabitants.
All the POI retrieved from OSM and Foursquare can be associated to a specific neighborhood of Manhattan or Paris.
We will compute features for each neighborhood based on aggregations of the POI we retrieved. We aggregate businesses and locations based on their type. So for example we have for each zone the number of food-related locations, both from OSM and Foursquare.
We then create a segmentation with a k-means clustering algorithm.
We recommend that you follow the links to the project that corresponds to the city you know best. This way, you will have a better understanding of how well the clustering algorithm works!
Start by looking at the flow and visualizing the different steps of the project. You can see the preparation steps in yellow and the modeling steps in green.
EXPLORE !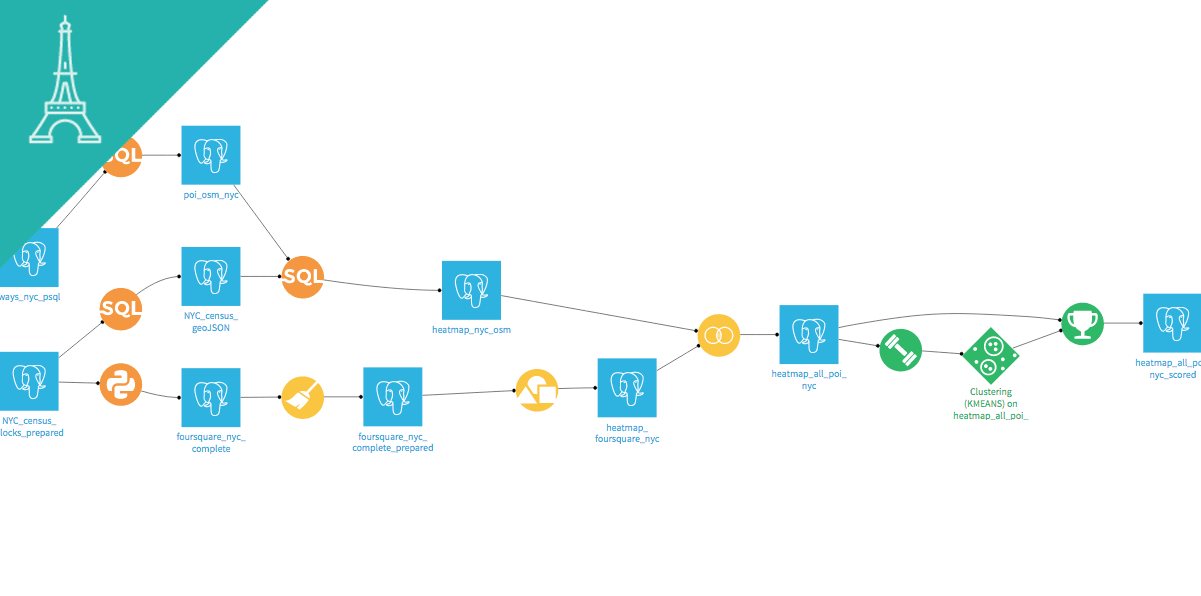
The flow for the city of Paris is very similar, most of the data preparation and the modeling steps are identical.
EXPLORE !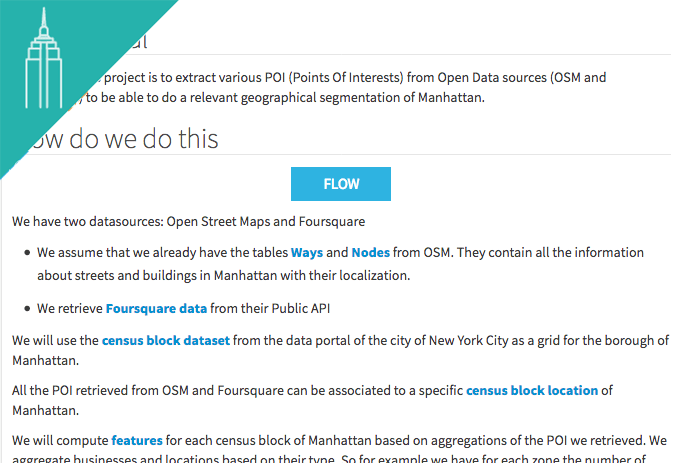
Find out how we proceed for the borough of Manhattan by reading the detailed description of the project.
EXPLORE !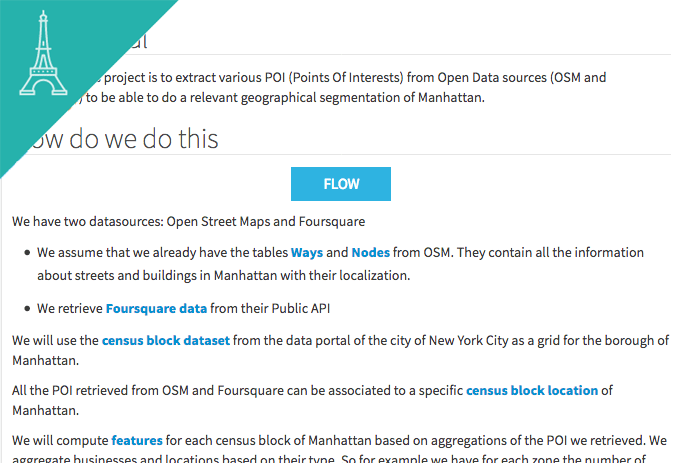
The project for the city of Paris also features a detailed description. The only difference is the choice of block-level polygons, provided by INSEE.
Explore !