
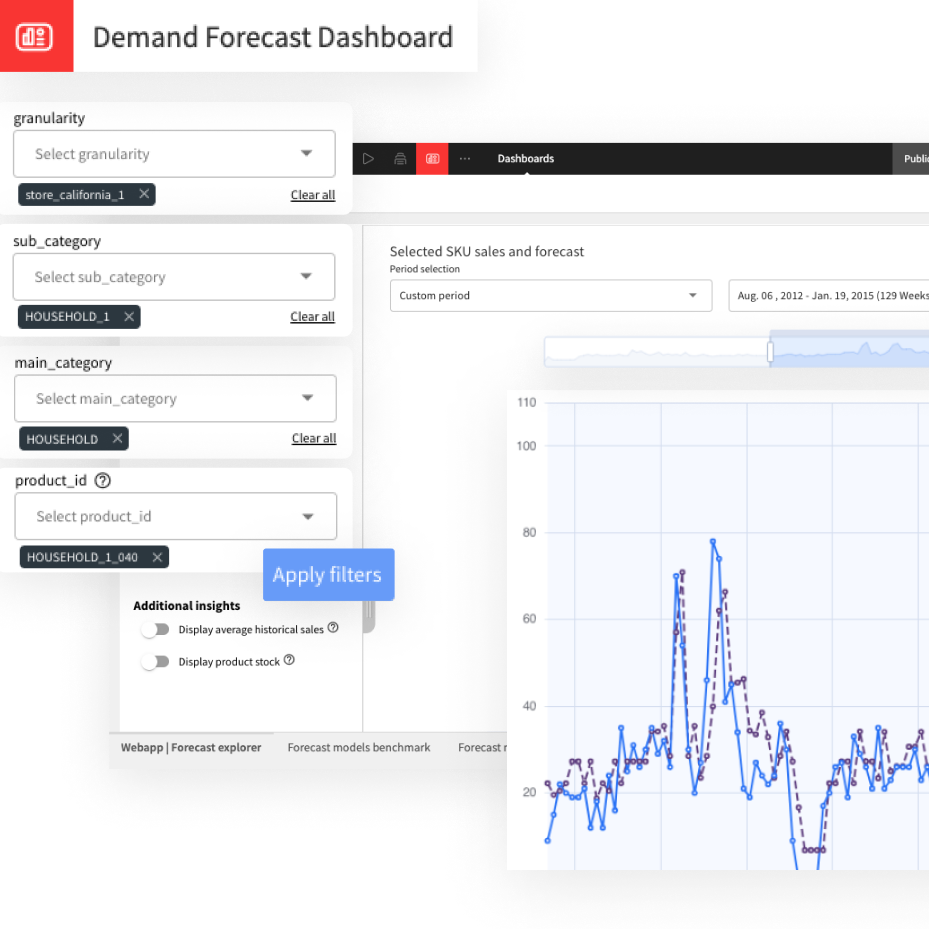



Search Page
So you can understand what we're trying to build, let's start by exploring the finished project. It's a search page. You can type in a few words to look for issues, and refine your search with the facets on the left.
EXPLORE !
When submitting a bug report, you want to make sure that no one has submitted the same report than you, to avoid duplicates as well as mean comments from the community. The problem is, the default search engine for github tickets does not handle synonyms or even plurals, so it’s not very efficient. So we decided to build another search engine.
To do this, we used the Algolia API, as well as two plugins, in Dataiku DSS of course, because we wanted something quick to setup.
This is actually a project that we use internally at Dataiku to search bugs reports, and our support tickets.
1. Save time by finding the relevant Github ticket right away:
2. Visualize stats on those tickets, for fun!
The steps are simple:
To save time, we make sure that everyday, only the tickets updated the day before are pushed to Algolia.
Should you want to reuse and adapt this project to your own need, here are the steps. This project requires:
DATA_DIR/bin/pip install markdownDATA_DIR/pyenv/lib/python2.7/site-packages/github/Requester.py according to https://github.com/PyGithub/PyGithub/pull/378/files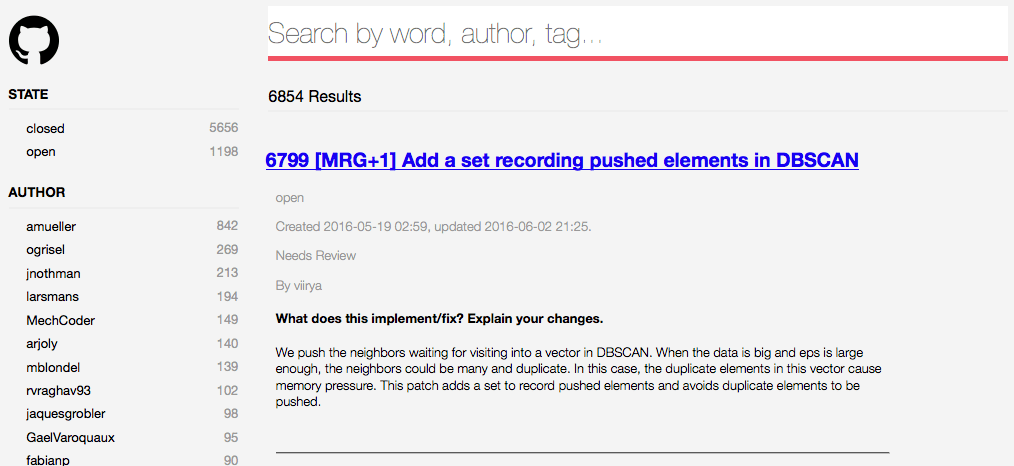
So you can understand what we're trying to build, let's start by exploring the finished project. It's a search page. You can type in a few words to look for issues, and refine your search with the facets on the left.
EXPLORE !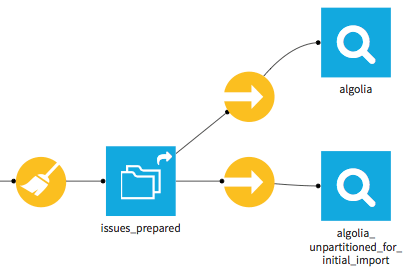
The flow is linear. We started by downloading all the issues from the Scikit repository on git. You can obviously choose another repository, even a private one to which you have access. We do this with Dataiku DSS's github plugin, which provides a custom dataset. This is the input dataset at the left of the flow.
- This dataset does not store the data (just a sample for preview), it mereley provides the connection. So a sync recipe copies this data into a managed local dataset.
- Then a Python recipe formats the comments.
- The resulting dataset goes through a preparation script to rename some columns and format dates according to Algolia's needs. The result is partitioned thanks to the “Redispatch partitioning according to input columns” option. (We partition according to the “updated_at_partition_id” column).
- This final dataset is uploaded to Algolia by a sync recipe, which every day uploads just the tickets updated the day before. Here as well, the output dataset does not store the data, it only provides the connection.
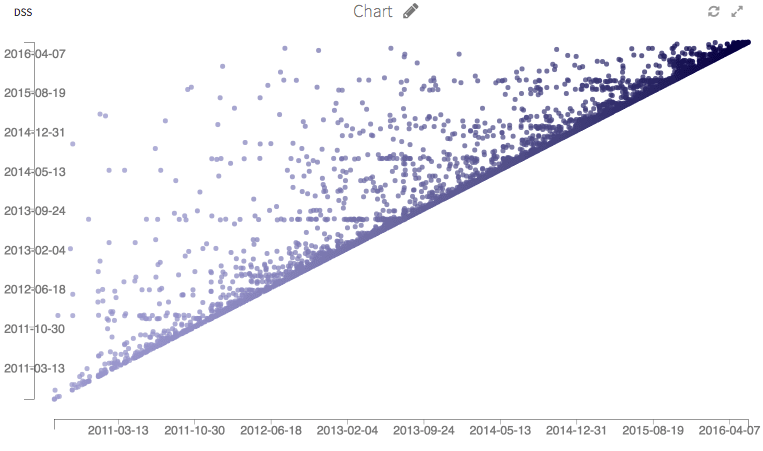
Finally, here are some graphs. We could run many more stats on this dataset, this is just an illustration.
EXPLORE !