
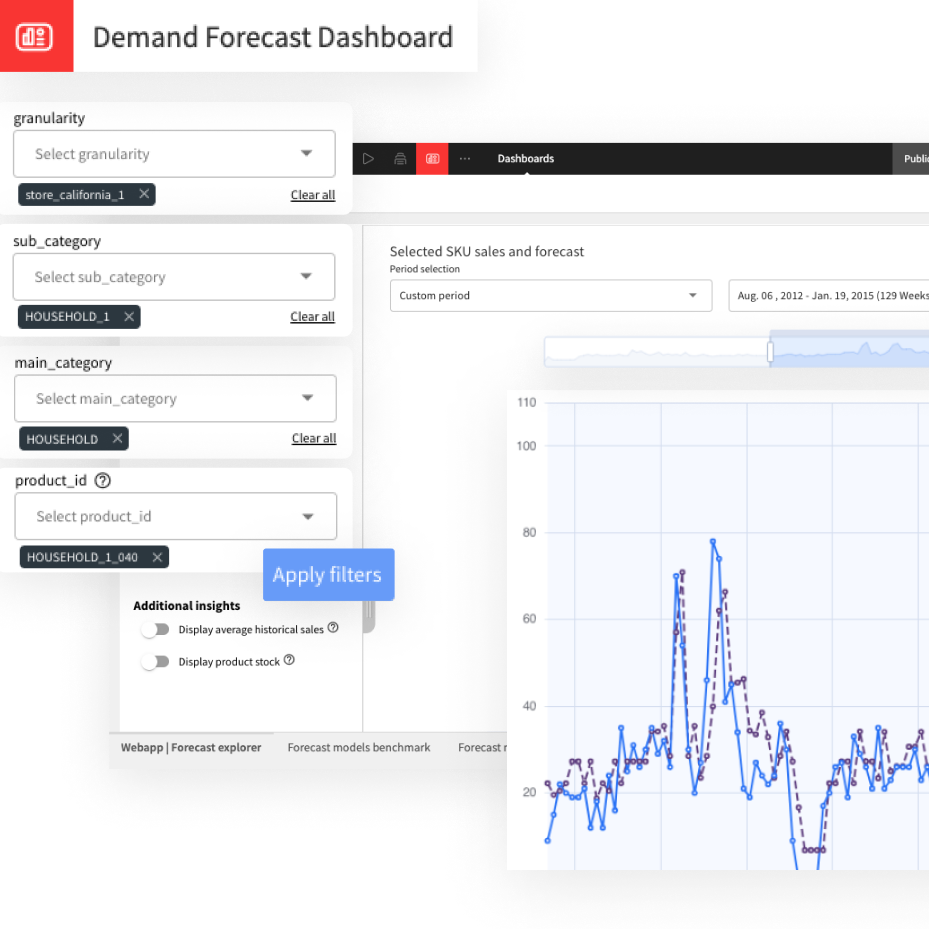



Dashboard
Look at the visual insights we built to monitor churn and understand our customers behavior. We updated these as we went along by adding graph steps to our preparation scripts. What could be a predictive business intelligence.
EXPLORE !
We’re a major telecom operator. Just like pretty much any company in the world, we are concerned with keeping our customers happy, so they won’t leave us. In other words, we want to reduce churn. To do this, we set up a task force of data analysts and people from our business teams who came up with several business goals to reduce churn.
We had our data science team collect historic data from users on their phone usage, and work on creating features from very large log files. They specified which clients had churned.
They also built the same features for our current clients, so we could deploy the model and predict who would churn.
Because we wanted to do more than just answer the yes no question of “will they churn,” we decided to build two models instead of one:
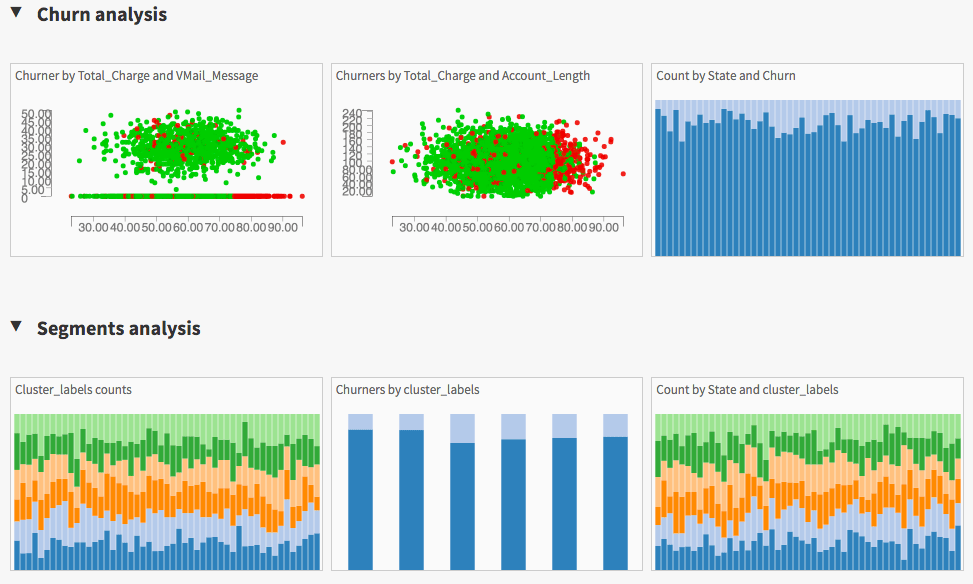
Look at the visual insights we built to monitor churn and understand our customers behavior. We updated these as we went along by adding graph steps to our preparation scripts. What could be a predictive business intelligence.
EXPLORE !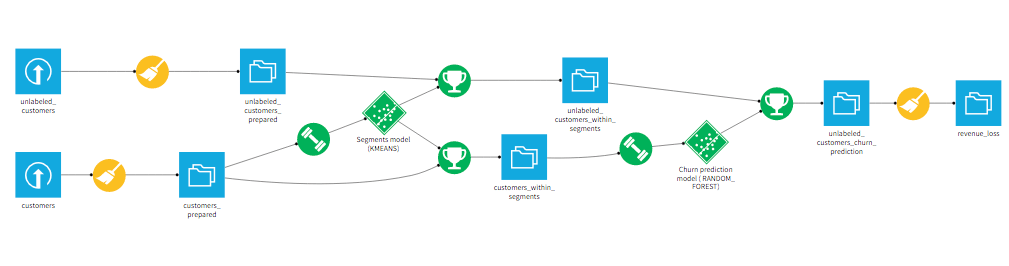
Check out the few steps of data preparation and machine learning that are needed for this advanced analytics operation. You'll notice cleaning recipes (in yellow), and the 2 models in green.
EXPLORE !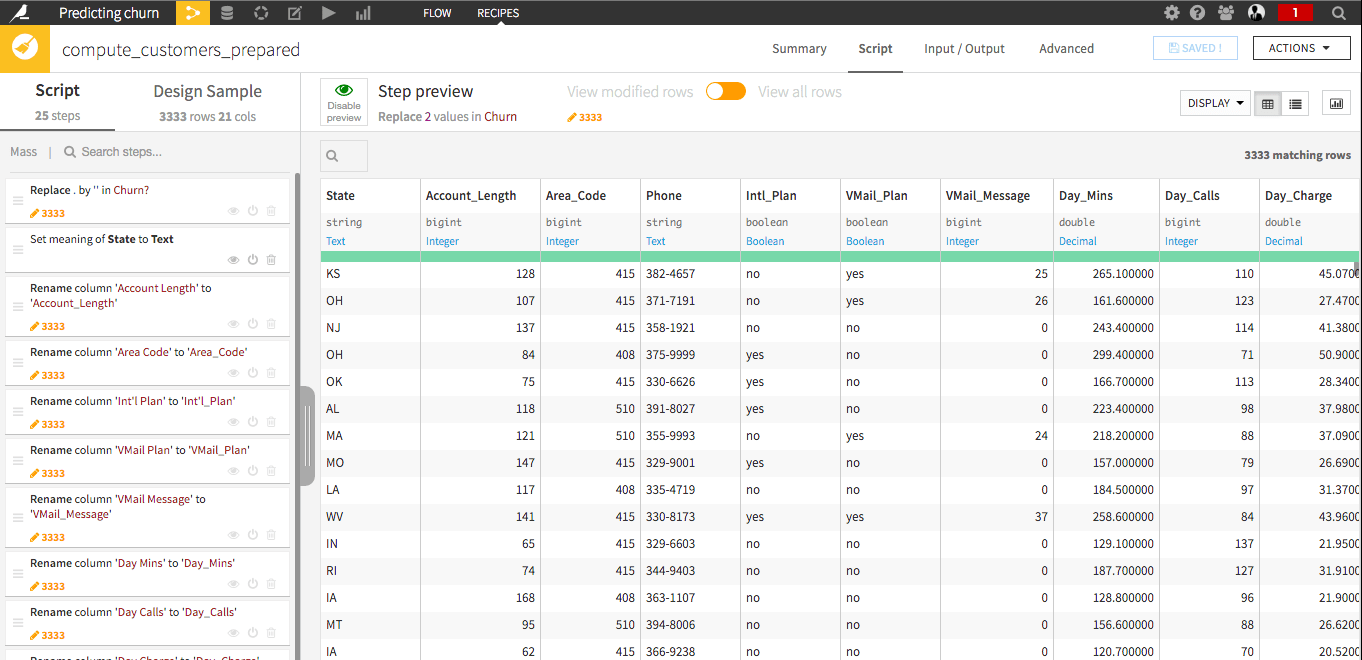
Look at the data preparation script to clean the customer data and create new features.
EXPLORE !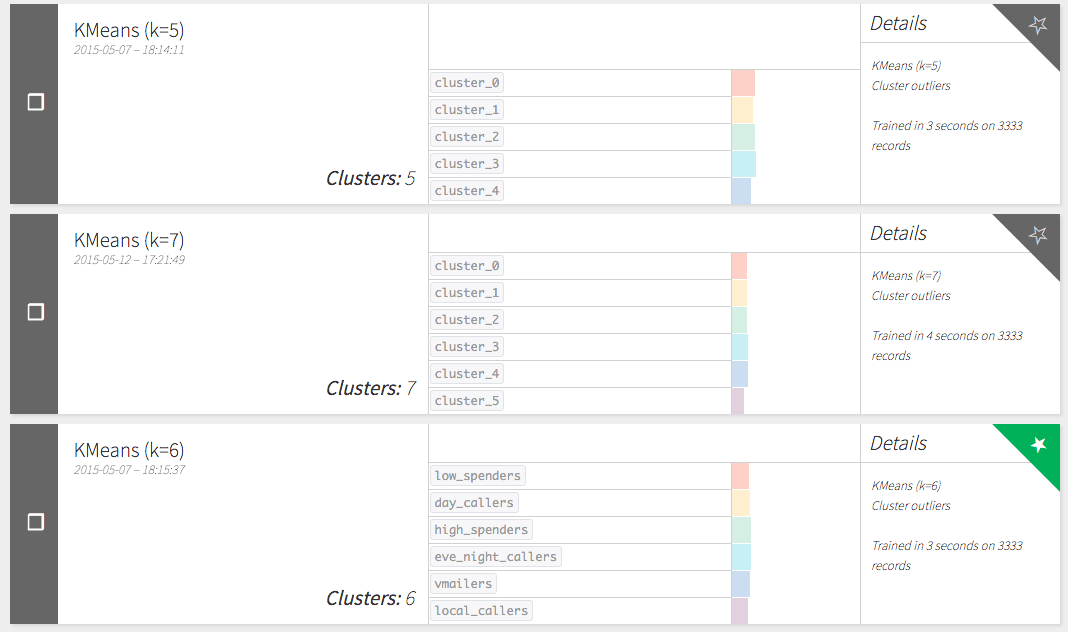
Read here how we created our first model to segment our customers, and then deployed on our current customers' data AND on our historical data.
EXPLORE !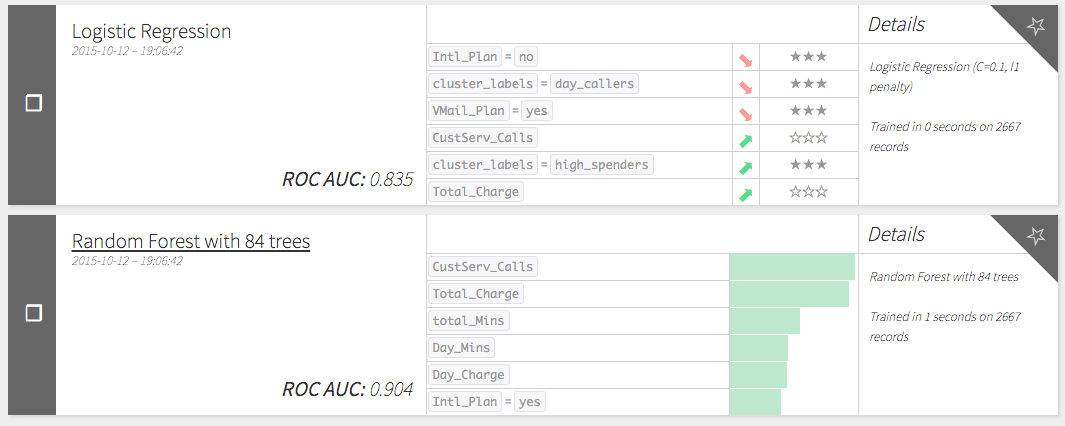
Understand how we then worked on our second algorithm to predict churn behavior.
EXPLORE !