Inside the Box: Building an Explainable AI Foundation
Implementing an Explainable AI Strategy
Imagine being denied a mortgage, but no one can tell you exactly why. Today, AI systems make thousands of life-altering decisions, from loan approvals to medical diagnoses. Yet as these systems grow more complex, a crucial question emerges: can we trust decisions we can’t understand?
This question lies at the heart of the explainable AI challenge. As organizations deploy increasingly sophisticated AI models, they face a critical choice between powerful but opaque black-box systems and more transparent white-box alternatives. Success requires not just implementing AI, but implementing it responsibly.
In this guide, we’ll explore the essential tools and strategies that make AI interpretable, helping you build compliant, trustworthy systems while maintaining competitive performance. You’ll learn practical approaches to mitigate risks, ensure regulatory compliance, and establish robust data science practices that balance power with transparency.
Creating transparent, accessible AI systems is important not only for those behind the curtain developing the model (such as a data scientist), but also for end users not involved in model development (such as lines of business who need to understand the output and how it translates to other stakeholders in the company).
Don’t fret — there are ways to build models in a way that is trusted and reliable for the business. Enter: explainable AI. The rise of complex models over the last decade has led organizations to realize that there are consequences to AI that we don’t understand (that have real-world impacts), which, in turn, spurred many breakthroughs in the space, conferences dedicated to the topic, leaders in the field discussing it, and a need for tooling to understand and implement explainable AI models at scale.
Explainable AI is a set of capabilities and methods used to describe an AI model, its anticipated impact, and potential biases. Its objective is to address how black-box models reached their decisions and then make the model as interpretable as possible.
There are two main elements of explainability:
- Interpretability: Why did the model behave as it did?
- Transparency: How does the model work?
Ideally, every model — no matter the industry or use case — would be both explainable and transparent, so that, ultimately, teams trust the systems powered by these models, mitigating risk and enabling everyone (not just those involved) to understand how decisions were made. Examples where explainable and transparent models are useful include:
- Critical decisions related to individuals or groups of people (e.g., healthcare, criminal justice, financial services)
- Seldom-made or non-routine decisions (e.g., mergers and acquisitions work)
- Situations where root cause may be of more interest than outcomes (e.g., predictive maintenance and equipment failure, denied claims or applications)
Black-Box vs White-Box Models
We live in a world of black-box models and white-box models. On the one hand, white-box models have observable and understandable behaviors, features, and relationships between influencing variables and the output predictions (think: linear regression models and decision trees), but are often not as performant as black-box models (i.e., lower accuracy, but higher explainability). Essentially, the relationship between the data used to train the model and the model outcome is explainable.
Conversely, black-box models have unobservable input-output relationships and lack clarity around inner workings (think: a model that takes customer attributes as inputs and outputs a car insurance rate, without a discernible how). This is typical of deep learning models and boosted/random forest models, which model incredibly complex situations with high non-linearity and interactions between inputs.
Here, the relationship between the data and the model outcome is less explainable than a white-box model. There are no clear steps outlining why the model has made the decisions that it has, so it’s difficult to discern how it reached the outputs and predictions that it did.
In some situations, we may be comfortable with this tradeoff between model performance and explainability. For example, we might not care why an algorithm recommends a particular movie if it is a good match, but we do care why someone has been rejected for a credit card application.
To understand the tradeoffs between white-box and black-box models, we can use a real-life example of an opaque “system” — the medical doctor. Most people think of a doctor as a kind of black-box system that takes symptoms and test results as input and predicts the diagnosis as output. Without providing information about the way medical tests and evaluations work, the doctor delivers a diagnosis to a patient by explaining high-level indicators that are revealed in the tests. We don’t really understand what those tests are, yet we trust them for matters of life and death. This shows us that not all opaque systems are bad — just the ones that we don’t trust.
The central idea of explainable AI is about establishing trust from all of the involved parties, such as:
- The data scientist who builds the models wants to make sure it conforms to their model behavioral expectations.
- The stakeholders who use the model to make decisions want to be assured that the system is making the correct output (without understanding the mathematical details behind the scenes).
- The public, those who are affected directly or indirectly by the predictions of the model, want to ensure that they are not being treated unfairly.
The important point to note is that different individuals will have different expectations about the explainability of a system. It depends on their roles and their understanding of societal and domain standards. Therefore, the decision of whether or not a machine learning (ML) system is responsible, fair, and correct should and must always be the result of a discussion between all parties, using all the signals provided by the system.
Why Explainable AI Matters More in the Generative AI Age
As generative AI continues to evolve and proliferate across various domains, the need for explainability becomes even more pronounced to ensure responsible and ethical deployment of these powerful technologies.
- Understanding the Output: Generative AI models, especially in domains like natural language processing or image generation, produce outputs that can be complex and nuanced. Understanding why a model generates a particular output is essential for trust and reliability, especially in critical applications like healthcare or finance.
- Detecting Bias and Fairness Issues: Generative AI models can inadvertently learn and propagate biases present in the training data. AI model explainability tools and mechanisms help in identifying these biases and ensuring fairness and equity in the generated outputs.
- Debugging and Improvement: AI explainability tools aid in debugging and improving generative AI models by providing insights into how the model makes decisions or generates outputs. This feedback loop is crucial for refining and enhancing the performance of the model over time.
- Regulatory Compliance: With increasing regulations around AI ethics and transparency, explainability becomes a legal requirement in many contexts. Generative AI systems must comply with these regulatory requirements to ensure accountability and mitigate potential risks.
- User Trust and Adoption: Users are more likely to trust and adopt generative AI systems if they can understand the reasoning behind the model’s decisions. Explainable AI provides transparency and helps build trust between human users and AI systems.
- Ethical Considerations: Understanding the inner workings of generative AI models is essential for addressing ethical concerns, such as the potential misuse of AI-generated content or the impact on privacy and security.
These explainability challenges are part of a broader consideration in AI implementation: balancing model performance with interpretability. This fundamental tension between black-box and white-box models presents unique tradeoffs that every organization must carefully evaluate.
Now that we’ve covered what explainable AI is, why it’s important, and the challenges and nuances you need to consider when building explainability into your frameworks, let’s summarize how Dataiku can help.
Explainable AI With Dataiku
It should be clear at this point that a high-performing AI organization should include transparent and explainable best practices — in essence, it should be trustworthy. To reach this high level of trustworthiness, an ML system needs a high level of interpretability.
A robust ML pipeline nowadays needs to provide not only predictions, but also enough information that allows humans to gain enough understanding of the model, and from there to build trust into the system. Let’s cover each phase of the ML pipeline, the questions you should be thinking about, and how Dataiku can help you answer these questions.
It’s critical for organizations to understand how their models make decisions because:
- It gives them the opportunity to further refine and improve their analyses.
- It makes it easier to explain to non-practitioners how the model uses the data to make decisions.
- Explainability can help practitioners avoid negative or unforeseen consequences of their models.
Dataiku helps organizations accomplish all three of these objectives by striking the optimal balance between interpretability and model performance. Dataiku, the Universal AI Platform, ensures models remain transparent and trustworthy across their entire lifecycle. So, how exactly does Dataiku help builders and project stakeholders stay aligned to their organizational values for responsible AI?
Data Explainability & Transparency
Responsible AI practices include inspecting your data set for potential flaws and biases. Dataiku makes it easy to quickly profile and understand key aspects of your data with built-in tools for data quality and exploratory data analysis. Uncover insights faster with a smart assistant that can suggest a variety of statistical tests and visualizations to help you identify and analyze relationships between columns. Specialized general data protection regulation options mean you can also document and track where personal identifiable information, or PII, is used, yielding better oversight of sensitive data points from the start.
Dataiku offers interactive statistics to allow you to examine the bias in the raw data, as well as:
- Data lineage, so you know where the data originated from.
- Transparent data transformation and cleaning to ensure data quality.
- Automated exploratory data analysis and summary statistics to identify outliers and key insights about the data.
- The Flow, a visual pipeline providing explainability and traceability into all actions performed.
- Git-based version control and a timeline of recent project actions, including the ability to revert changes.
Model Explainability
For projects with a modeling component, Dataiku’s Visual ML framework offers a variety of tools to fine tune and evaluate machine learning models and confirm they meet expectations for performance, fairness, and reliability.
Model Building & Training
To incorporate domain knowledge into model experiments in the form of common sense checks, subject matter experts can add model assertions — basically informed statements about how we expect the model to behave for certain cases. These ML assertions help you to systematically verify whether your model predictions align with the experience of your domain experts. A full panel of diagnostics helps us perform other sanity checks by automatically raising warnings if any issues such as overfitting or data leakage are detected.
Partial dependence plots help model creators understand complex models visually by surfacing relationships between a feature and the target, so business teams can better understand how a certain input influences the prediction.
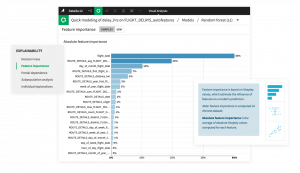
Interactive subpopulation analysis allows users to see results by group in order to see whether a model performs equally well across different subgroups in the population, or “cuts of the data.” A related view is model error analysis, which delivers insight into specific cohorts for which a model may not be performing well. Both these analyses help to find groups of people who may be unfairly or differently treated by the model, which will help teams deliver more responsible and equitable outcomes, as well as improve the model’s robustness and reliability before deploying.
Before deploying a solution that involves protected categories such as race, gender, age, or demographic characteristics, it’s important to assess whether systemic bias in the model treats these specific subgroups differently when it comes to the predictions. Dataiku’s model fairness reports were designed to help accomplish this task.
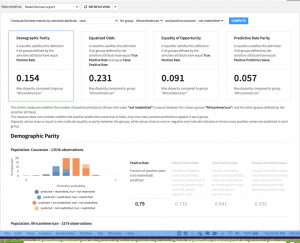
Depending on the individual use case, different lenses may need to be applied to evaluate fairness from various angles. The goal of these model views is to calculate several industry-accepted fairness metrics and explain the definitions for each. From there, users can choose the metrics that best assess the fairness of the situation at hand.
Model Deployment & Monitoring
Explainability can be especially helpful in model monitoring, because it can be easier to diagnose whether models are still healthy, accurately representing current conditions, and performing the jobs they were built for. If the answer to any of these questions is “no,” explainable workflows are critical to troubleshooting and finding answers.
Monitoring ML models in production is an important, but often tedious task for everyone involved in the data lifecycle. Conventional model retraining strategies are often based on monitoring model metrics, but in many use cases, using a metric like area under the curve might not do the trick.
This is especially true in cases where long periods of time pass before receiving feedback on the accuracy of the model’s predictions. Dataiku’s model drift monitoring shortens the feedback loop and allows users to examine if new data waiting to be scored has drifted from the training data.
Further, data quality rules in Dataiku can be used to detect data drift from the model training data, but also just to check that data within pipelines (with or without an ML component) isn’t shifting too far from a predetermined tolerance threshold.
Dataiku’s what-if analysis allows data scientists and analysts to check different input scenarios and publish the what-if analysis for business users with interactive scoring. With what-if analysis accessible to business users, they can build trust in predictive models as they see the results they generate in common scenarios and test new scenarios.
Dataiku’s AI Explain enables organizations to instantly explain both pipelines and code in layman’s terms, which helps preserve critical project knowledge and increase understanding from diverse stakeholders. The model document generator (which has customizable templates) automatically generates descriptions that explain Dataiku Flows or individual Flow Zones. Teams no longer need to spend countless hours maintaining project documentation — thanks to this robust auto-documentation, organizations can maintain consistent records of projects for regulatory compliance and alignment with responsible AI guidelines.
This reduces the time needed to manually update a document after every minor change to keep it current. It also allows stakeholders outside of the data science team to clearly see the big picture — how the data was prepared, the features, the details of deployment, and so on — simultaneously creating a foolproof audit trail.
Local Explainability
For AI consumers who are using model outputs to inform business decisions, it’s often useful to know why the model predicted a certain outcome for a given case. Row-level, individual explanations are extremely helpful for understanding the most influential features for a specific prediction, or for records with extreme probabilities. During scoring, prediction explanations can be returned as part of the response, fulfilling the need to have reason codes in regulated industries and providing additional information for analysis. Row-level interpretability helps data teams understand the decision logic behind a model’s specific predictions.
Project Explainability
For overall project transparency and visibility, zooming back out you can see how Dataiku’s Flow provides a clear visual representation of all the project logic. Wikis and automated documentation for models and the Flow are other ways builders, reviewers, and AI consumers alike can explain and understand the decisions taken across each stage of the pipeline.
Audit Centralization & Dispatch
Audit trails and having detailed activity and job logs are important for effective MLOps and technical troubleshooting. They are also often required from a risk and compliance standpoint. Dataiku centralizes audit logs across all users’ activity, as well as capturing query logs for deployed API services to complete the feedback loop.
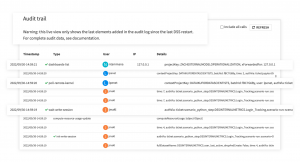
Automated model documentation, row-level prediction explanations, and centralized audit logs in Dataiku help organizations create a traceable and transparent path to enterprise AI. Without robust transparency and explainability systems, organizations could risk building AI applications that can output prediction at scale without understanding its profound implications. With Dataiku, organizations can quickly create sustainable and responsible AI practices without investing in additional standalone tools.
Collaboration
Dataiku is an inclusive and collaborative platform that makes data and AI projects a team sport. By bringing the right people, processes, data, and technologies together in a transparent way, strategic decisions can be better made throughout the model lifecycle leading to greater understanding of, and trust in, model outputs. Specifically, Dataiku provides:
- A visual flow where everyone on the team can use common objects and visual language to describe the step-by-step approach to their data projects, documenting the entire process for future users
- An all-in-one platform where coders and non-coders can work on the same projects
- Discussion threads that allow teams to collaborate within the project framework, saving time and maintaining the history of the conversations and decisions as part of the project itself
- Wikis that preserve knowledge about the project for current and future users
No matter the model you select, Dataiku enables you to build with transparent and explainable best practices. Dataiku AI governance and MLOps capabilities enable teams to build responsible, accountable AI.
Go Further
Explore the Dataiku Model Data Compliance Plug-In
Watch the Model Document Generator Dataiku Demo
Watch the Governance Dataiku Demo
Watch the Explainable AI Dataiku Demo
Putting It Together
For enterprise-scale data science projects, data scientists and other model developers need to be able to explain not only how their models behave, but also the key variables or driving factors behind the predictions.
Building transparent, interpretable models is easier with Dataiku, enabling organizations to take accountability for their AI systems, ensure regulatory and risk compliance standards are met, and reduce harm and negative impacts from biased machine learning models.
As industries continue to integrate ML and AI (including generative AI) technology into their operations, balancing model performance with transparency is crucial. By leveraging tools and strategies from companies like Dataiku, you too can implement responsible data practices that underscore the importance of explainable AI.