





Plugin information
| Version | 1.0.0 |
|---|---|
| Author | Dataiku |
| Released | 2020-08 |
| Last updated | 2020-08 |
| License | MIT License |
| Source code | Github |
| Reporting issues | Github |
In order to monitor deployed ML models, data scientists and ML engineers need to check whether or not their new data looks like training data. Automating these checks warrants that model retrains are sensible.
Installation Notes
This plugin can be installed from the Plugin Store or via zip download (see installation sidebar).
The plugin uses a custom code environment. The base Python version needs to be the same as the one used at training time in the visual ML. The plugin will fail when loading the model otherwise.
Principle
Given a reference dataset or saved model, we compute compliance metrics on new data:
- For numerical columns, the ratio of samples out of reference bounds is computed.
- For categorical columns, the list of new unseen categories is computed.
Numerical bounds can be determined in two ways:
- Absolute range: the absolute min and max of the reference column are taken into account. This mode displays sensitivity to outliers.
- Inter-quantile range: compliant data are defined as values that fall between Q1 − 1.5 IQR and Q3 + 1.5 IQR.
How to use
Custom metric: Compare a dataset with a reference
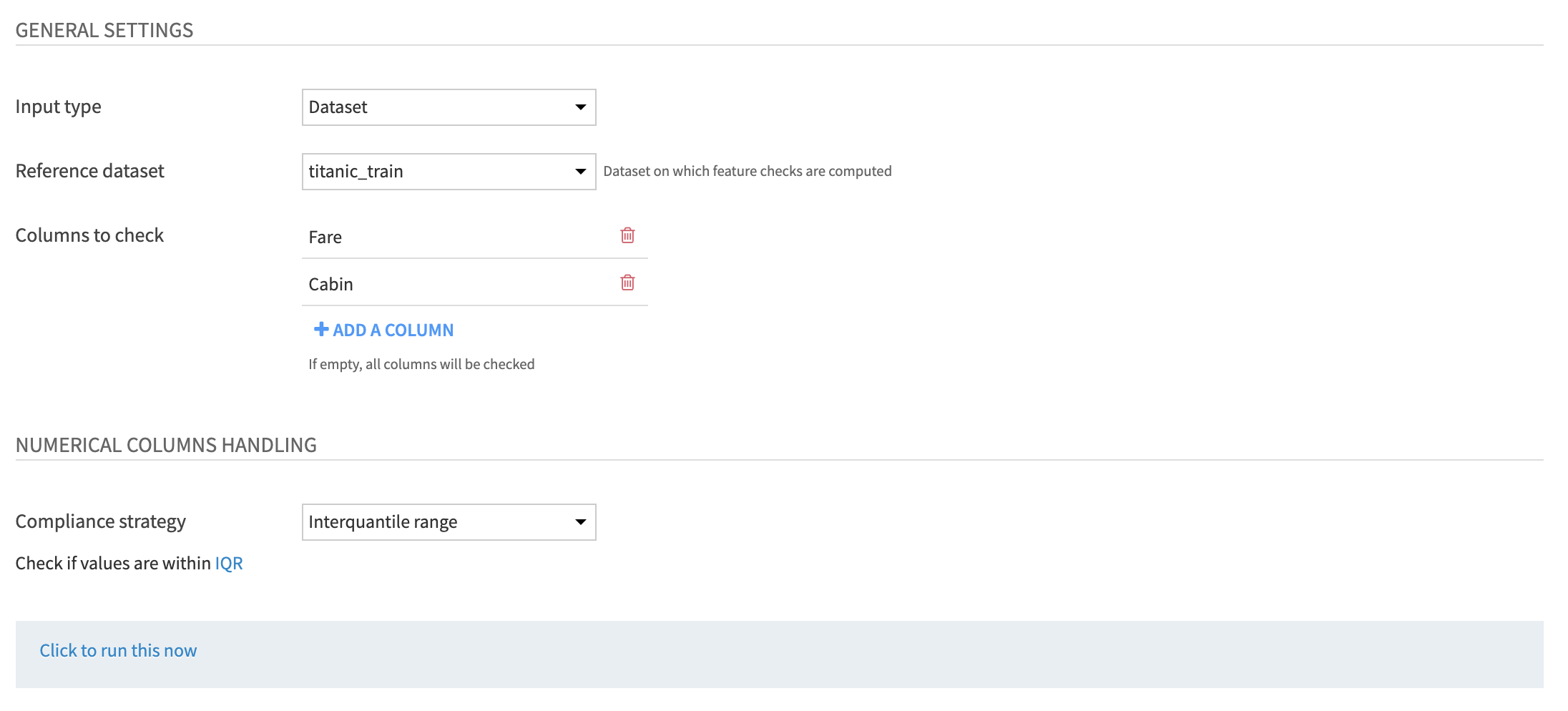
The reference data can either come from a dataset in the flow or a saved model. In the latter case, the original train set will be retrieved to be compared with the new data.
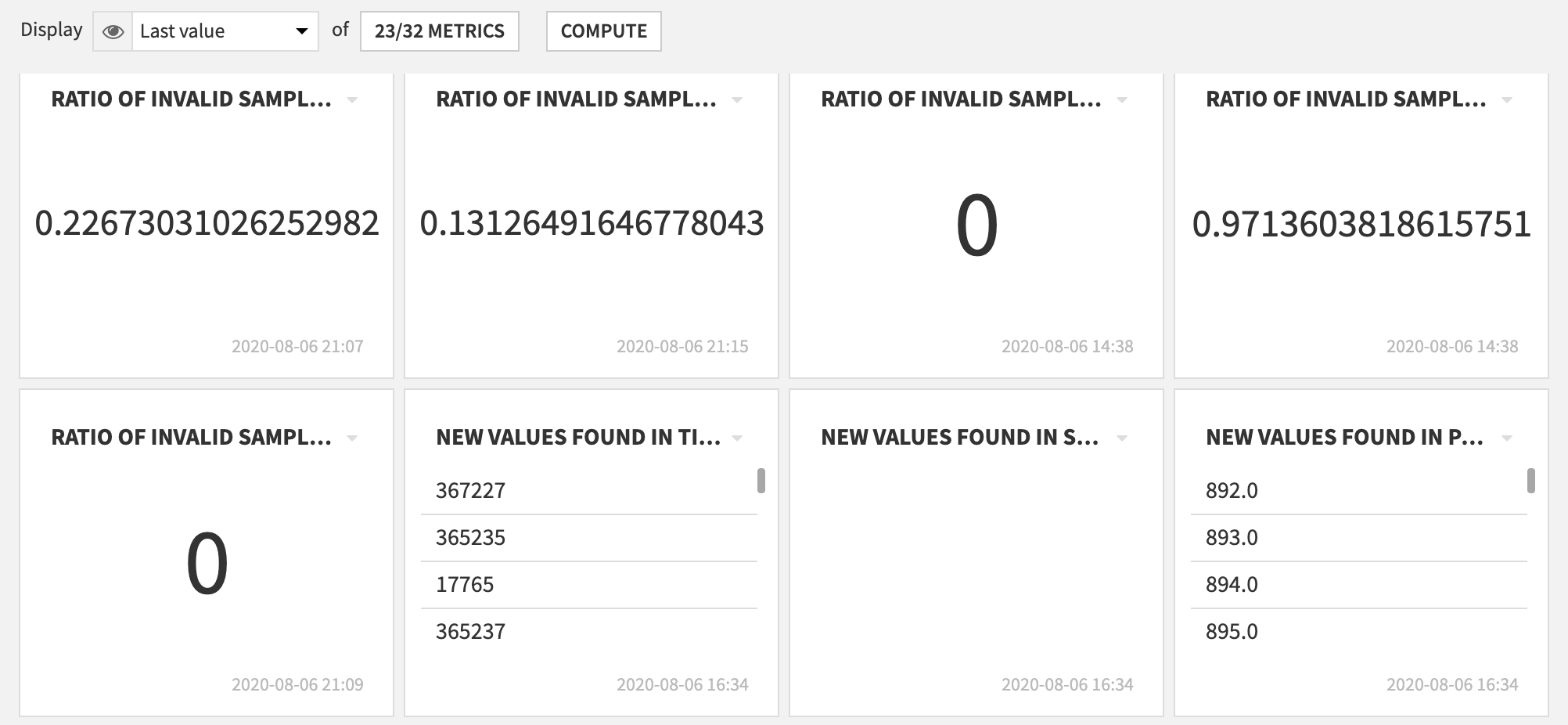
The plugin will create a compliance metric for each column.
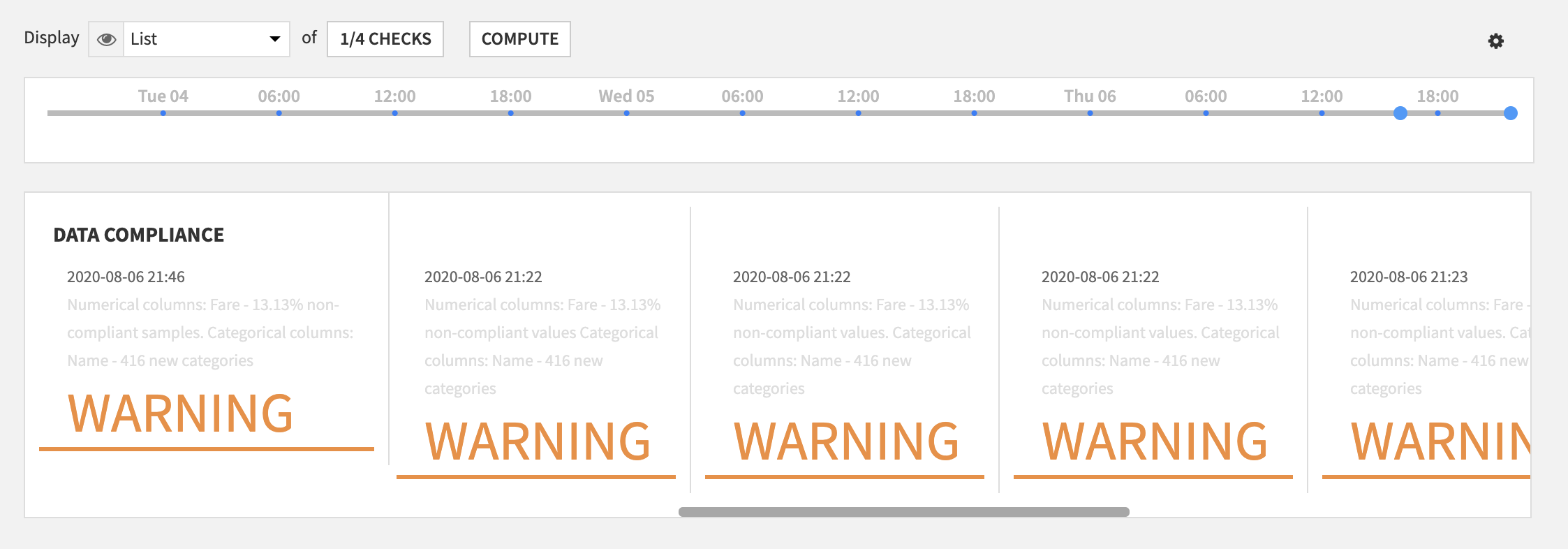
From there you can create a check on a specific column, or use a custom check (see below) to check all columns.
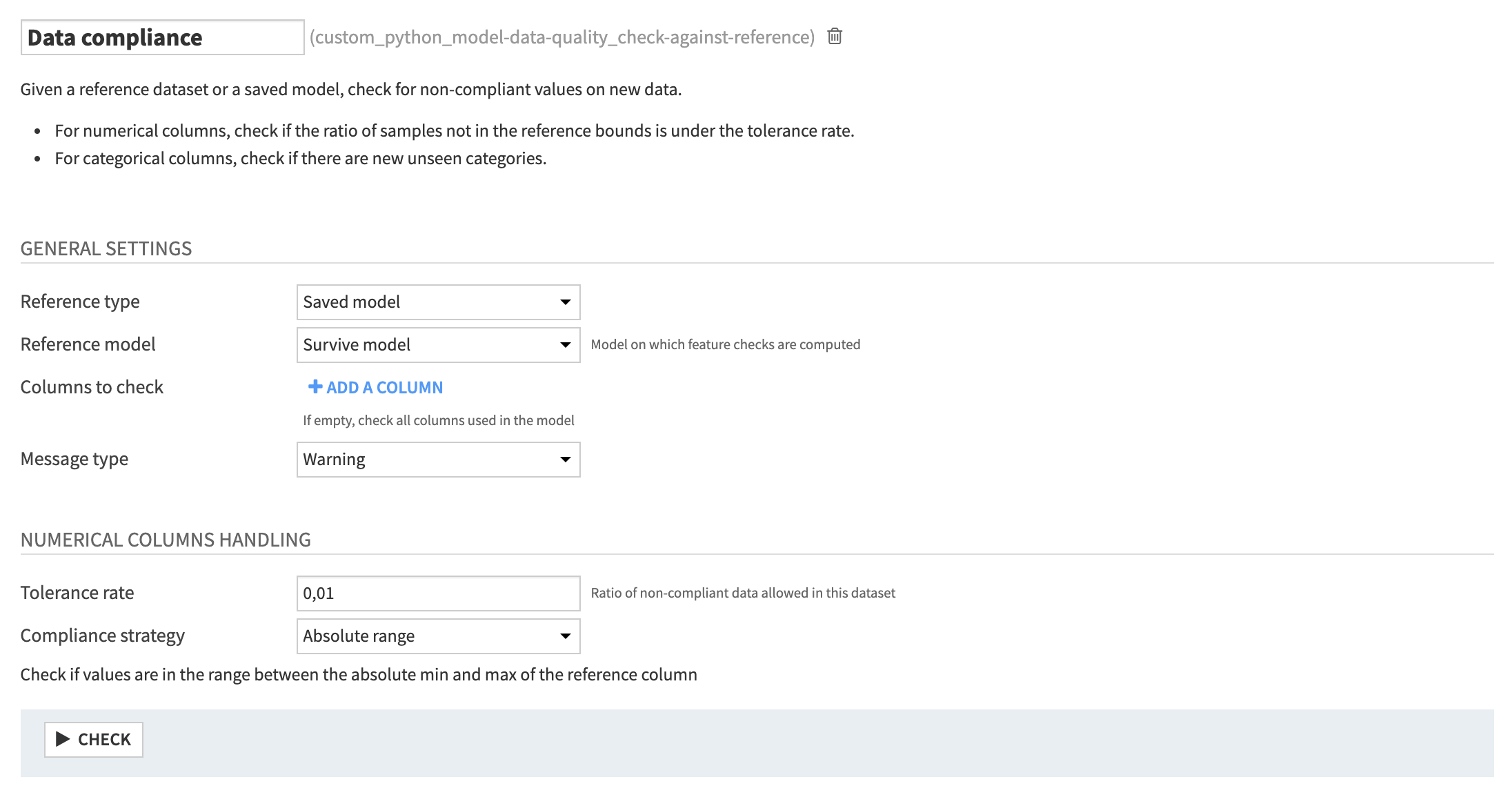
Custom check: Check dataset against reference
The reference data can either come from a dataset in the flow or a saved model. In the latter case, the original train set will be retrieved to be compared with the new data.
For numerical columns, you can define a tolerance ratio for non-compliant data. For categorical columns, as any new unseen category will most likely break the model, a warning or an error message will be raised immediately.
Once created, the check will check and report which columns contain non-compliant data.