Why does data wrangling become a bottleneck in scaling AI and generative AI?
Data wrangling becomes a bottleneck because it is fragmented across teams, inconsistently executed, and rarely governed, making it difficult to reuse, trust, or scale data for AI.
Most enterprises don’t have a single data preparation problem. They have dozens of disconnected ones.
Marketing runs transformations in spreadsheets. Data engineering maintains Python scripts. The analytics team built its own pipeline months ago and hasn’t updated the documentation. Finance uses a different tool entirely. Each team believes its data is clean, but none are working from the same definitions, and nobody has a unified view.
Where fragmentation breaks down
Shadow data prep processes
Teams build unofficial pipelines outside IT visibility, introducing inconsistencies that surface only when models underperform or reports contradict each other. This lack of visibility is not limited to data prep. According to "7 Career-Making AI Decisions for CIOs in 2026," based on a Dataiku/Harris Poll survey of 600 enterprise CIOs, 54% of CIOs report discovering unsanctioned AI use for work tasks or projects, highlighting how quickly ungoverned practices can spread.
Version conflicts
Analysts transform the same source data differently and arrive at different conclusions, with no audit trail to reconcile discrepancies.
The business impact
- Delayed insights: Teams spend weeks rebuilding preparation work that already exists.
- Risk exposure: Models are trained on data whose lineage nobody can document.
- Operational inefficiency: Every AI project starts from scratch rather than building on governed, reusable data preparation assets.
For AI and generative AI specifically, the stakes are higher. Models are only as reliable as the data they're trained on, and generative AI applications amplify data quality issues by producing confident-sounding outputs from flawed inputs. Without consistent, governed data preparation, scaling AI is building on an unstable foundation.
The consequences are visible at the leadership level. According to the same Dataiku/Harris Poll survey, 85% report that explainability gaps have already delayed or stopped AI projects from reaching production. Undocumented data preparation is one of the most common drivers of those gaps: when teams cannot trace how raw data became model inputs, the project stalls.
What challenges do enterprises face with data wrangling at scale?
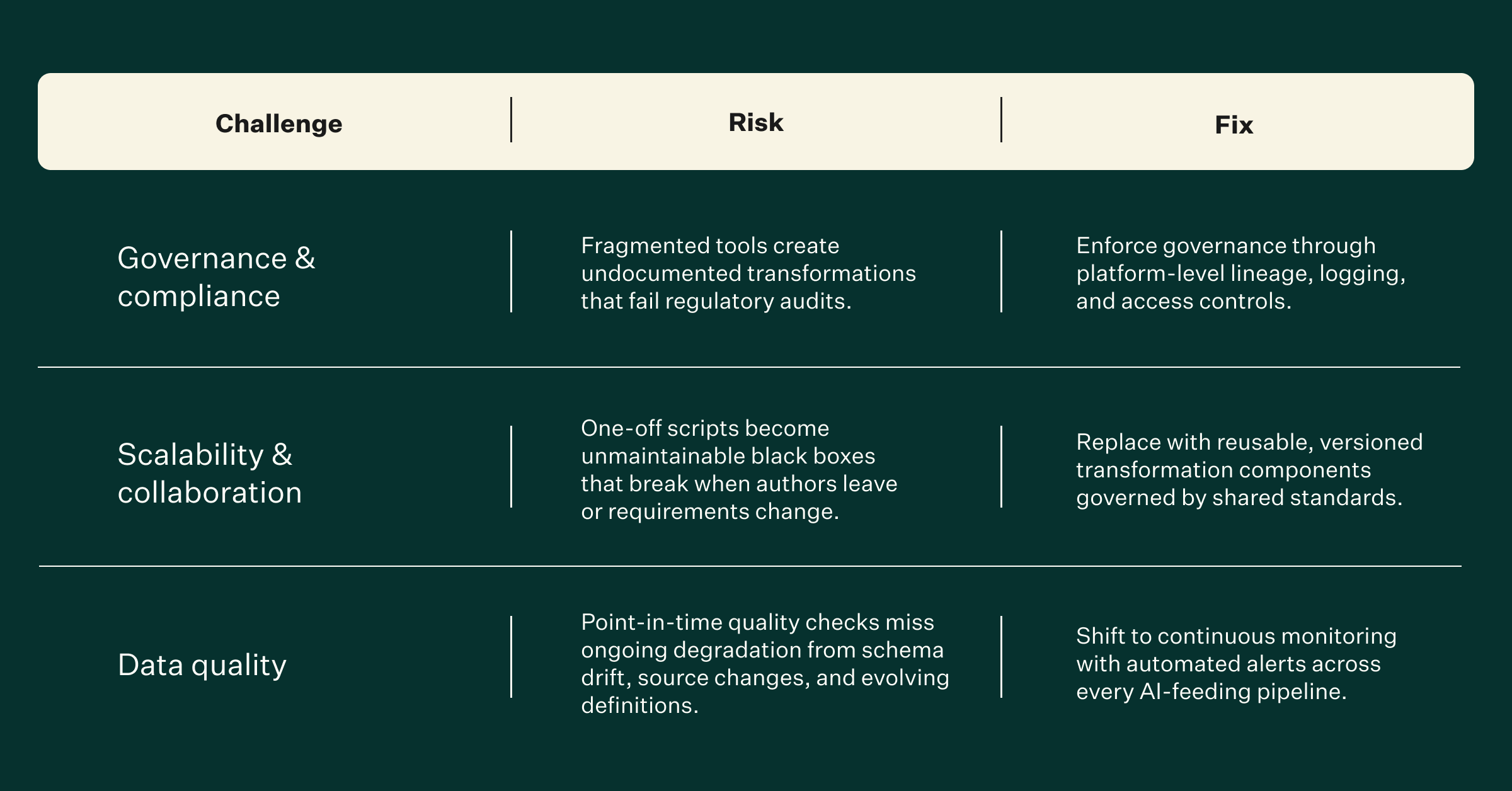
Enterprises face three interconnected data wrangling challenges at scale: governance and compliance visibility, cross-team collaboration, and operationalizing data quality as a continuous discipline rather than a one-time step. Each reinforces the others.
The table below summarizes these challenges, risks, and fixes.
 Click on the image above to zoom into full PDF
Click on the image above to zoom into full PDF
Governance and compliance risks
When data transformations happen across fragmented tools and scripts, organizations lose visibility into what was changed, when, by whom, and why. This creates documentation gaps that become liabilities during regulatory audits, particularly in industries with strict data handling requirements like financial services and healthcare.
The problem isn't that governance rules don't exist. It's that the tooling doesn't enforce them. If a data scientist can transform a dataset in a local notebook without any record in a central system, governance exists on paper but not in practice. Compliance teams end up chasing documentation after the fact, reconstructing lineage from memory and email threads rather than from automated audit trails.
Mitigation: Enforce governance through platform-level controls — automated lineage, transformation logging, and access policies — rather than relying on documentation processes that teams bypass under deadline pressure.
Scalability and collaboration
At the individual level, a custom Python script solves the preparation problem for one project. At enterprise scale, hundreds of one-off scripts become unmaintainable. When the original author leaves, the script becomes a black box. When business requirements change, nobody knows which downstream processes will break.
The alternative is reusable data pipelines with standardized transformation logic that multiple teams can discover, understand, and extend. This requires cross-team agreement on naming conventions, data definitions, and quality thresholds, which is an organizational challenge as much as a technical one.
Mitigation: Replace one-off scripts with reusable, versioned transformation components that are discoverable across teams and governed by shared standards for naming, definitions, and quality thresholds.
Operationalizing data quality
Most organizations treat data quality as a pre-deployment checkpoint: clean the data, validate it, then move on. But data changes continuously. Source systems are updated. Business definitions evolve. New data sources are integrated. A dataset that passed quality checks last month may be producing unreliable results today.
Operationalizing data quality means building validation frameworks that run continuously, not once. It means monitoring pipelines in production for schema drift, missing values, and distribution shifts. And it means creating observability into data health that's accessible to the teams consuming the data, not just the engineers maintaining the pipelines.
Mitigation: Shift from point-in-time validation to continuous monitoring with automated alerts for schema drift, distribution shifts, and completeness degradation across every pipeline feeding AI systems.
From manual wrangling to modern data preparation
The shift from manual data wrangling to governed data preparation follows a clear pattern.
Individual scripting gives way to centralized transformation logic where rules are defined once, versioned, and applied consistently across projects. Version control and reproducibility replace ad hoc notebooks that can't be audited or reliably rerun.
Metadata-driven workflows replace tribal knowledge about which fields mean what, how they were derived, and where they came from.
The most important shift is integration: when data preparation lives inside the same environment as modeling, deployment, and monitoring, it stops being a disconnected upstream task and becomes part of the AI lifecycle.

Click on the image above to zoom into full PDF
How to evaluate modern data wrangling tools
Modern data wrangling tools fall into four categories: programming-based approaches, visual and low-code enterprise platforms, advanced data processing frameworks, and cloud-native transformation services. Each involves different tradeoffs across governance, scalability, and collaboration.
-
1. Programming-based approaches (Python with pandas, R, SQL scripts) offer maximum flexibility for complex transformations. They suit expert practitioners but create collaboration barriers, governance gaps, and maintainability risks when used as the primary enterprise approach.
-
2. Visual and low-code enterprise platforms like Dataiku, the Platform for AI Success, provide governed environments where both code-first and visual users work on the same data pipelines. Transformations are documented automatically, reusable across projects, and connected to downstream modeling, GenAI, agents, and deployment.
-
3. Advanced data processing frameworks (Apache Spark, Dask) handle large-scale distributed computation. They're essential for organizations processing massive datasets but require engineering expertise and don't inherently provide governance or collaboration features.
-
4. Cloud-native data transformation services (managed services from major cloud providers) integrate with cloud data warehouses and offer scalability. They work well within a single cloud ecosystem but can create fragmentation when organizations operate across multiple environments.
When evaluating tools, the criteria that matter most at enterprise scale are governance (are transformations auditable?), scalability (can the tool handle production workloads?), auditability (can you trace every change back to its origin?), collaboration (can technical and non-technical users work together?), and AI readiness (does prepared data flow directly into modeling and deployment?).
How to align data wrangling with an AI transformation strategy
Aligning data wrangling with AI strategy means treating data preparation as strategic infrastructure rather than an operational task that happens before the real work begins. When that shift happens, it enables three outcomes that compound across the organization.
-
1. Explainability through lineage. Data lineage documentation lets regulators and stakeholders trace a model's output back through every transformation to its original source. Without that traceability, explainability claims have no foundation.
-
2. Reduced model risk through consistency. When models across the organization are trained on data governed by the same quality standards, preparation inconsistencies stop being a source of silent model failures.
-
3. Self-service without chaos. Governed by centralized policies and quality checks, self-service data preparation allows business teams to work with data directly without creating the ungoverned sprawl that keeps IT leaders awake at night.
The leadership shift is straightforward: data wrangling belongs in the same strategic conversation as model development, deployment, and monitoring. It's the layer everything else depends on.
Best practices for operationalizing data wrangling at scale
Turning data wrangling from an ad hoc activity into a governed enterprise capability requires five operational shifts:
-
1. Standardized transformation frameworks: Define common transformation patterns (date formatting, currency conversion, entity resolution) as reusable templates that teams can apply rather than rebuilding from scratch.
-
2. Centralized governance policies: Establish organization-wide rules for data access, transformation documentation, and quality thresholds. Enforce them through tooling, not through policy documents that nobody reads.
-
3. Reusable data preparation components: Build a library of governed data prep recipes that teams across the organization can discover, trust, and extend. Each component should include documentation, ownership, and quality metrics.
-
4. Documentation and audit trails: Automate the capture of who transformed what, when, and why. Manual documentation is unreliable at any scale. Automated lineage within a platform is the only approach that works consistently.
-
5. Platform consolidation: Reduce the number of disconnected tools involved in data preparation. Every additional tool in the stack is another integration to maintain, another governance gap to monitor, and another silo to bridge.
Data wrangling vs. ETL vs. ELT
Data wrangling, ETL (extract, transform, load), and ELT (extract, load, transform) are related but serve different purposes in the data lifecycle.

Click on the image above to zoom into full PDF
In practice, the ownership question matters as much as the technical distinction. ETL pipelines are typically owned by data engineering. ELT transformations are shared between engineering and analytics. Data wrangling, when ungoverned, ends up owned by everyone and governed by no one, which is precisely the problem this article addresses. The strategic answer is bringing wrangling under the same governed infrastructure as production data pipelines.
Bringing data wrangling into the AI lifecycle
Sustainable AI at scale depends on governed data preparation that is reusable across teams, documented automatically, and integrated into the platforms where models are built, deployed, and monitored. Data wrangling is not data cleaning.
The organizations scaling AI successfully are not the ones with the best models. They're the ones that solved the data preparation problem first: governed transformations, reusable across teams, documented automatically, and integrated directly into the platforms where models are built, deployed, and monitored.
Dataiku brings data preparation into the same governed environment as modeling, GenAI, agents, deployment, and AI governance. Visual and code-based users work on the same pipelines, transformations are version-controlled and documented automatically, and prepared data feeds directly into ML and generative AI workflows without leaving the platform.




.png?width=928&height=620&name=Thumbnail%20link%20(2).png)
.png)