




Plugin information
| Version | 1.1.2 |
|---|---|
| Author | Dataiku (Alex LANDEAU, Alex COMBESSIE) |
| Released | 2021-10 |
| Last updated | 2025-01 |
| License | Apache Software License |
| Source code | Github |
| Reporting issues | Github |
With this plugin, you can visualize text as word clouds in 59 languages.
Table of contents
How to set up
After installing the plugin, you need to build its code environment.
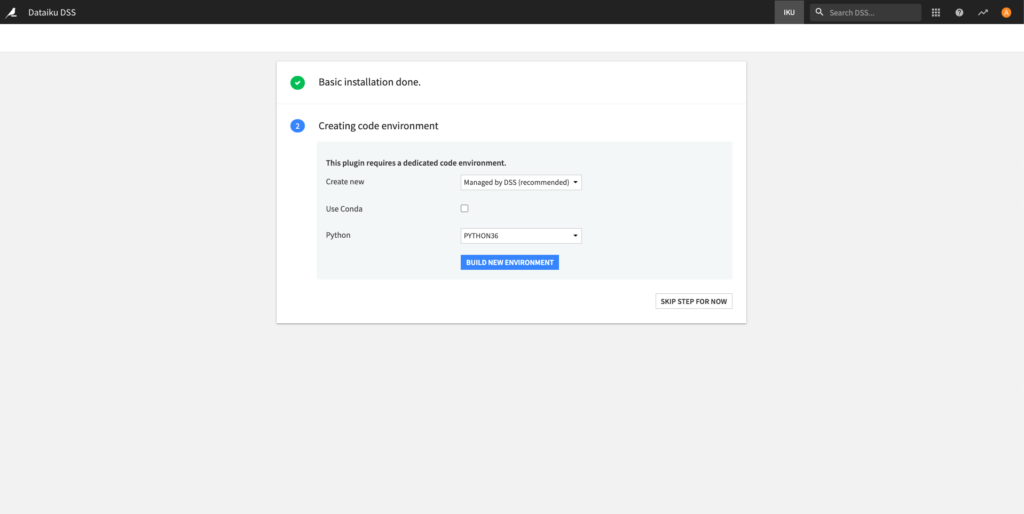
Note that Python version 3.6 or 3.7 is required.
To use this plugin with containers, you will need to customize the base image. Please follow this documentation with this Dockerfile fragment.
How to use
Let’s assume that you have a Dataiku DSS project with a dataset containing multilingual text data. This text data must be stored in a dataset, inside a text column, with one row for each document.
We recommend using the Text preparation plugin first to detect languages. You can also use this plugin to check misspellings and clean your text before visualization.
Navigate to the Flow, click on the + RECIPE button and access the Natural Language Processing menu. If your dataset is selected, you can directly find the plugin on the right panel.
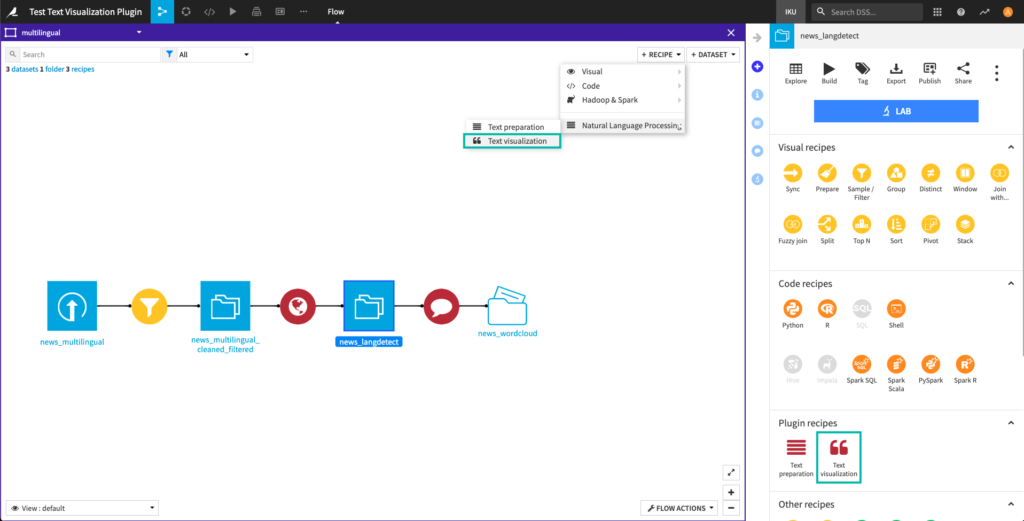
Word cloud recipe
Generate word clouds from your text data
Input
- Text dataset: dataset with a text column
Settings
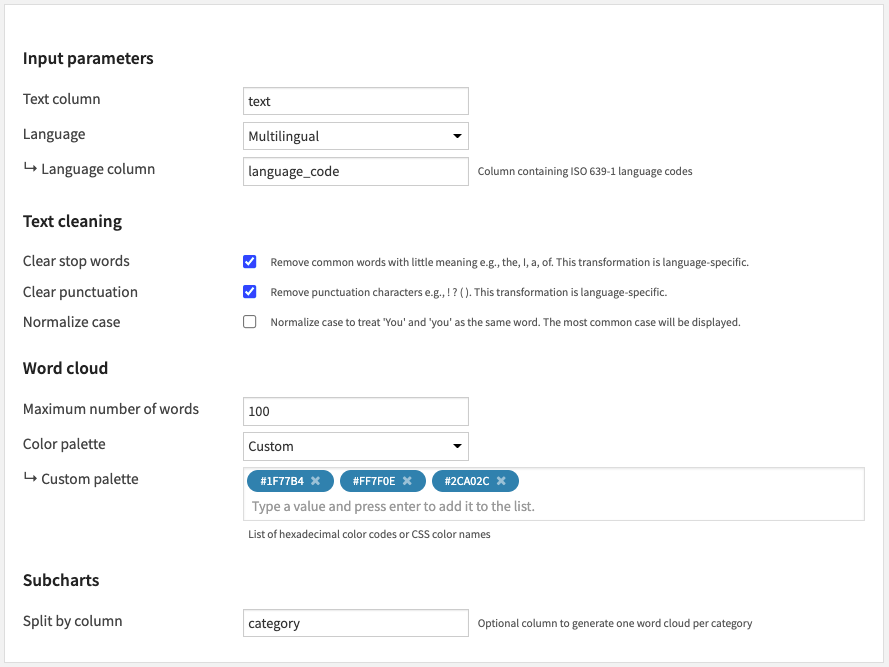
- Input parameters
- The Text column parameter lets you choose the column of your input dataset containing text data.
- The Language parameter lets you choose among 59 supported languages if your text is monolingual. Else, the Multilingual option will let you set a Language column.
- This Language column parameter can use the output of the Language Detection recipe or ISO 639-1 language codes computed by other means.
- Text cleaning
- You can choose to activate the following options:
- Clear stop words (activated by default): remove common words with little meaning e.g., the, I, a, of. This transformation is language-specific, using built-in lists specified here.
- Clear punctuation (activated by default): remove punctuation characters e.g., ! ? (). This transformation is language-specific, using rules from spaCy.
- Normalize case (not activated by default): treat ‘You’ and ‘you’ as the same word. The most common case will be displayed.
- You can choose to activate the following options:
- Word cloud
- Set the Maximum number of words to draw in each word cloud. Default is 100.
- Select a Color palette amongst the DSS built-in palettes, or set a custom one.
- You can enter a list of hexadecimal color codes or CSS color names in the Custom palette.
- Subcharts (optional)
- You can use the Split by column to generate one word cloud per category.
- In the multilingual case, you can split by Language column to get one word cloud per language.
Output
- Word cloud folder: folder where the word clouds will be saved as images
Known limitations
This plugin currently renders word clouds as images, which are generated using a single font. Hence, it does not support:
- Word clouds with a mix of Indo-European and Sino-Tibetan languages: In this case, we use a multilingual font that covers all Indo-European languages (English, French, Hindi, …), but not Sino-Tibetan ones (Chinese, Japanese, …). Ideograms will be rendered as “tofu” characters □.
- The solution is to use the Split by column parameter to generate one word cloud per language.
- In this case, each word cloud will be generated using a language-specific font.
- Emojis: They will be rendered as “tofu” characters □. The reason is that emoji fonts do not support regular characters.
- We do not currently have a solution to render emojis. For now, we recommend using the cleaning recipe of the Text preparation plugin to remove them.
We plan to address these limitations by allowing other rendering formats in the future.
Happy natural language processing!