




Plugin information
| Version | 1.3.1 |
|---|---|
| Author | Dataiku (Alex COMBESSIE, Damien JACQUEMART) |
| Released | 2020-09 |
| Last updated | 2025-01 |
| License | Apache Software License |
| Source code | Github |
| Reporting issues | Github |
With this plugin, you will be able to:
- Detect dominant languages among 114 languages
- If you have multilingual data, this step is necessary to apply custom processing per language
- Identify and correct misspellings in 37 languages
- Tokenize, filter, and lemmatize text data in 59 languages
Note that languages are defined as per the ISO 639-1 standard with 2-letter codes.
Table of contents
How to set up
Right after installing the plugin, you will need to build its code environment.
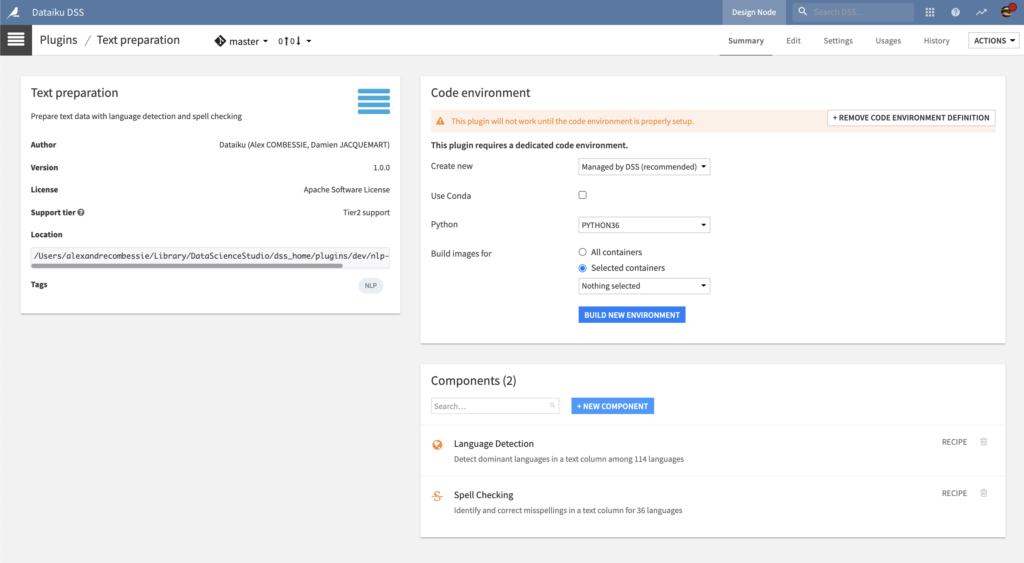
Note that Python version 3.6 or 3.7 is required. If you are installing the plugin on macOS, the pycld3 dependency requires at least macOS 10.14. Finally, Conda is not supported, as pycld3 is not currently available on Anaconda Cloud.
To use this plugin with containers, you will need to customize the base image. Please follow this documentation with this Dockerfile fragment.
How to use
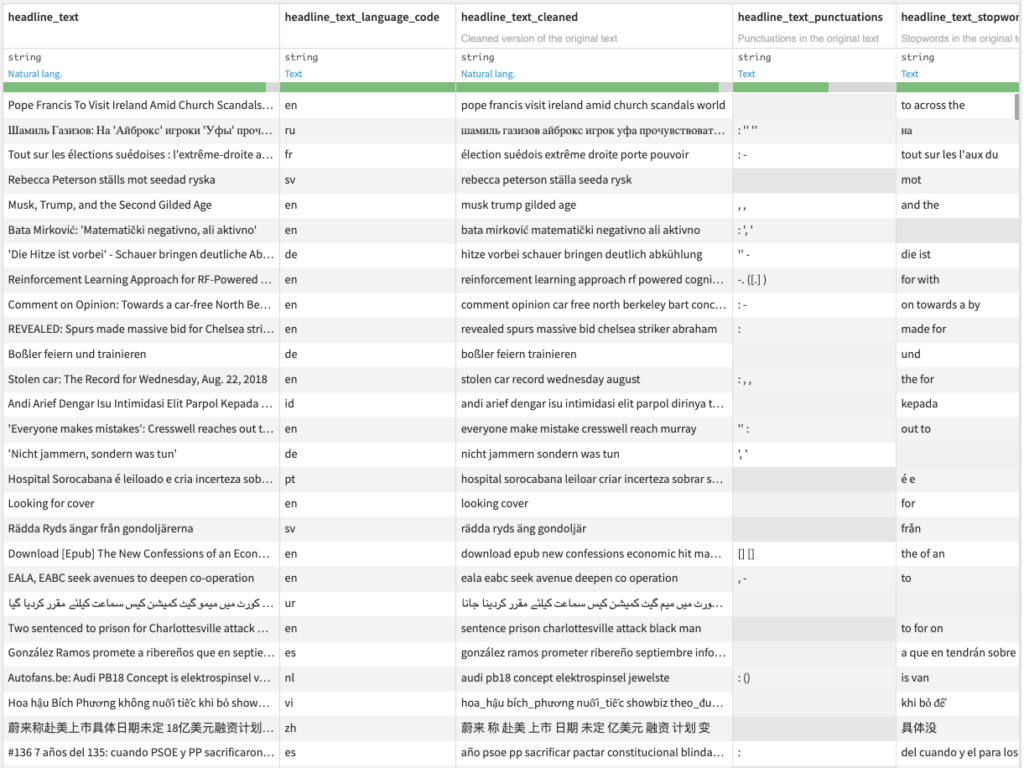
Let’s assume that you have a Dataiku DSS project with a dataset containing raw text data of multiple languages. This text data must be stored in a dataset, inside a text column, with one row for each document.
Navigate to the Flow, click on the + RECIPE button and access the Natural Language Processing menu. If your dataset is selected, you can directly find the plugin on the right panel.
Language Detection recipe
Detect dominant languages among 114 languages
Input
- Text dataset: Dataset with a text column
Settings
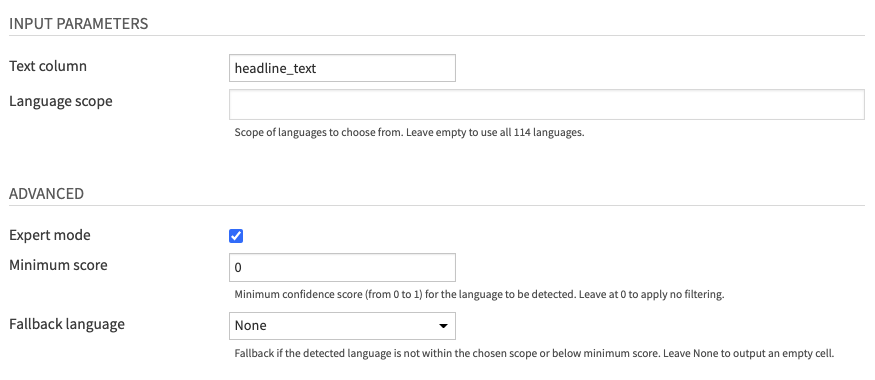
- Fill INPUT PARAMETERS
- The Text column parameter lets you choose the column of your input dataset containing text data.
- The Language scope parameter allows you to specify the set of languages in your specific dataset. You can leave it empty (default) to detect all 114 languages.
- (Optional) Review ADVANCED parameters
- You can activate the Expert mode to access advanced parameters
- The Minimum score parameter allows you to filter detected languages based on the confidence score in the prediction. You can leave it at 0 (default) to apply no filtering.
- The Fallback language parameter is for cases where the detected language is not in your language scope, or the confidence score is below your specified minimum.
- You can leave it at “None” (default) to output an empty cell.
- If the fallback is used, the confidence score will be an empty cell.
- You can activate the Expert mode to access advanced parameters
Output
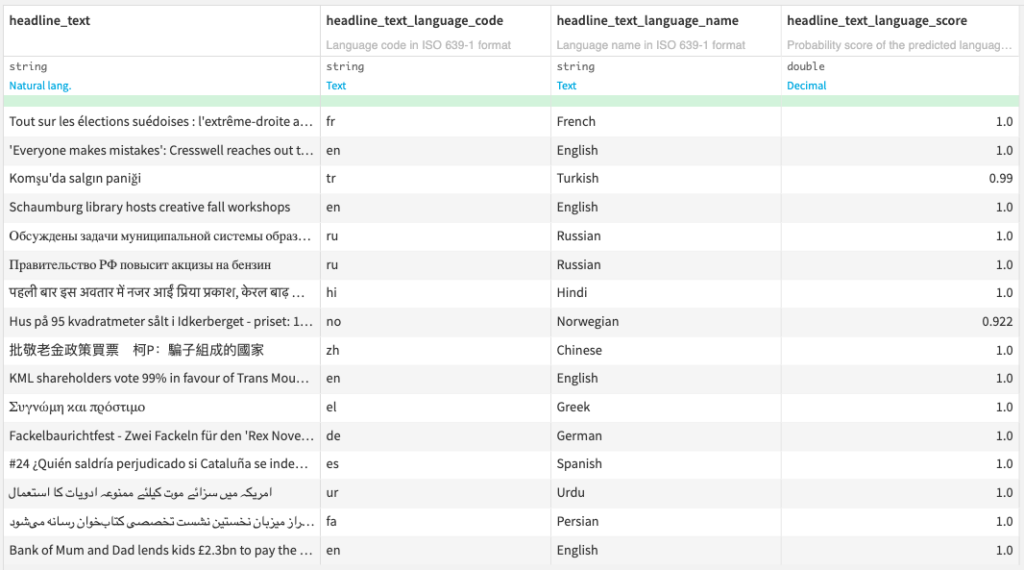
- Output dataset: Dataset with 3 additional columns
- ISO 639-1 language code
- ISO 639-1 language name
- Probability score of the predicted language from 0 to 1
Spell Checking recipe
Identify and correct misspellings in 37 languages
Input
- Text dataset: Dataset with a text column
- (Optional) Custom vocabulary dataset
- This dataset should contain a single column for words that should not be corrected.
- This input is case-sensitive, so “NY” and “Ny” are considered as different words.
- If your data contains special terms or slang which are not in the bundled dictionaries, we recommend using this dataset.
- (Optional) Custom corrections dataset
- This dataset should contain two columns, the first one for words and the second one for your custom correction.
- Words are also case-sensitive.
- If the same word is present in both custom vocabulary and corrections, the custom correction will overrule the custom vocabulary.
- Use this dataset if you wish to correct the special terms or slang contained in your data.
Settings
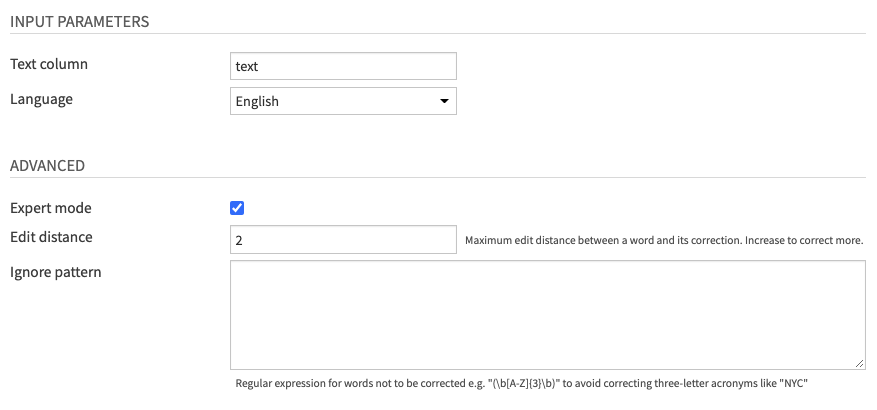
- Fill INPUT PARAMETERS
- The Text column parameter lets you choose the column of your input dataset containing text data.
- The Language parameter lets you choose among 37 supported languages if your text is monolingual. Else, the Multilingual option will let you set a Language column.
- This Language column parameter can use the output of the Language Detection recipe or ISO 639-1 language codes computed by other means.
- (Optional) Review ADVANCED parameters
- You can activate the Expert mode to access advanced parameters.
- The Edit distance parameter allows you to tune the maximum edit distance between a word and its potential correction.
- The Ignore pattern parameter lets you define a regular expression matching words which should not be corrected.
- This is useful if you work with special-domain data with acronyms and codes
- You can activate the Expert mode to access advanced parameters.
Output
- Output dataset: Dataset with 4 additional columns
- Corrected text
- Misspelled text
- List of unique misspellings
- Number of misspellings
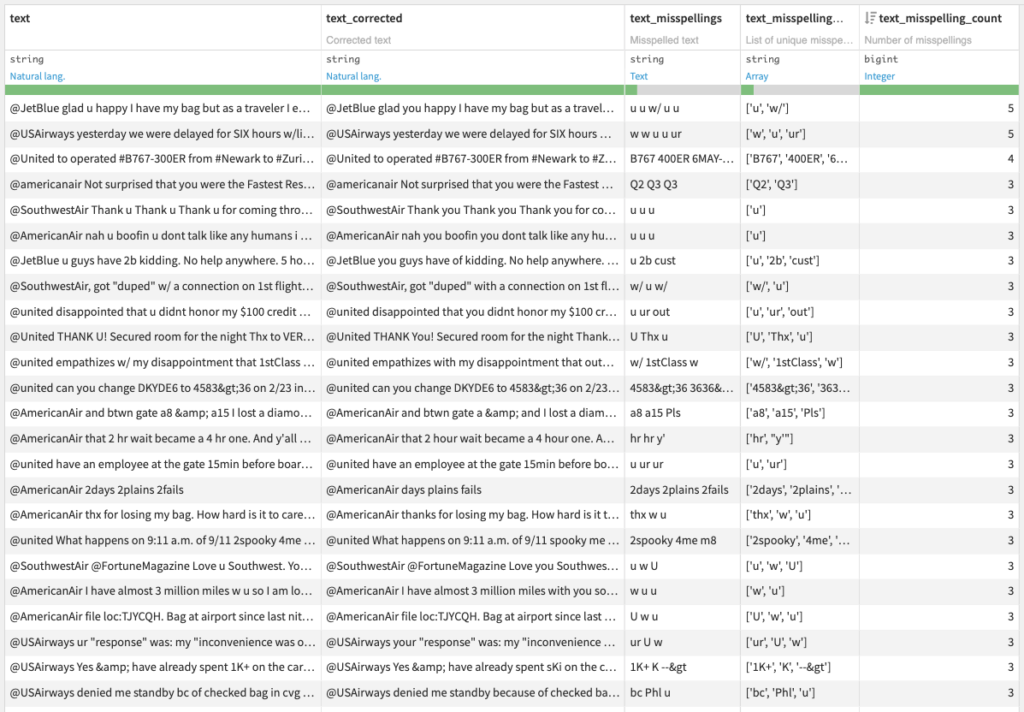
- (Optional) Diagnosis dataset with spell checking information on each word
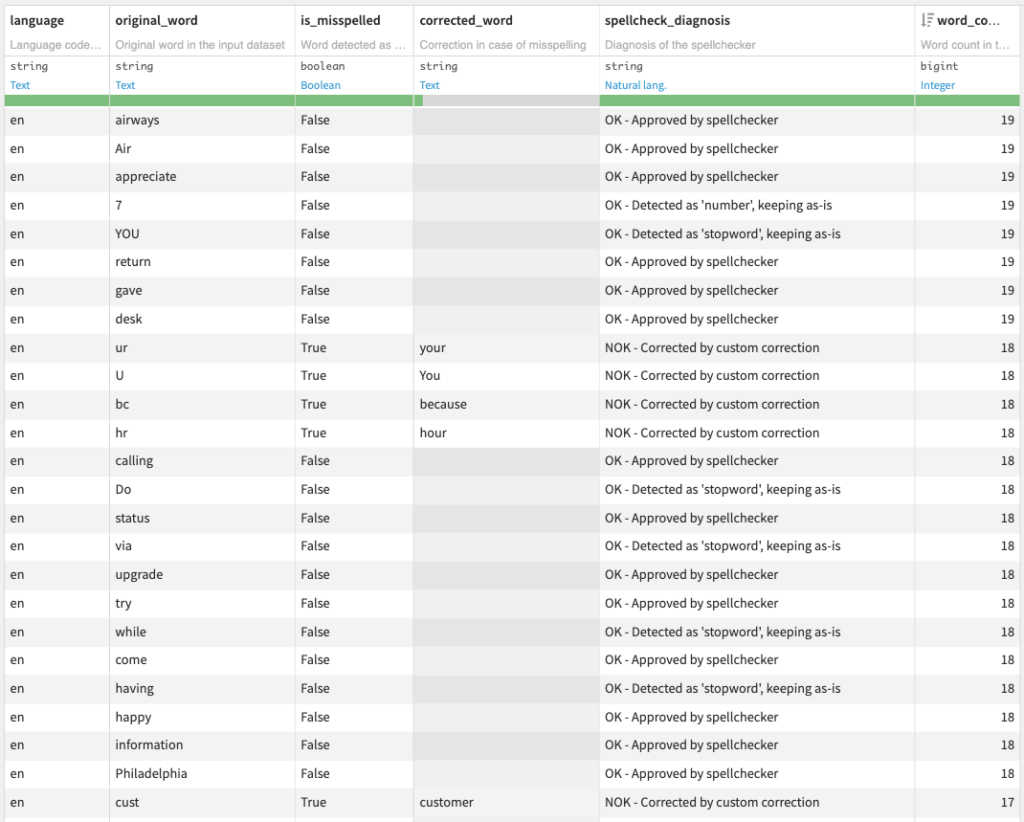
Note that including this optional diagnosis dataset will increase the recipe runtime.
Text cleaning recipe
Tokenize, filter, and lemmatize text data in 59 languages
Input
- Text dataset: Dataset with a text column
Settings
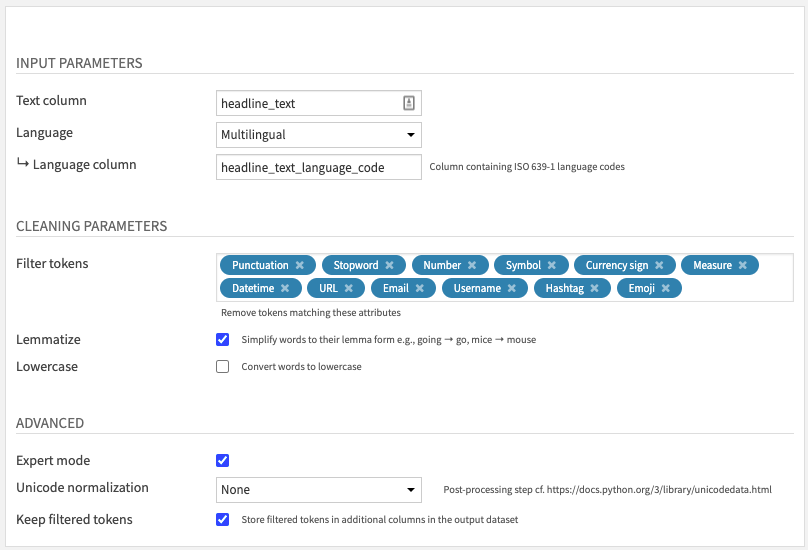
- Fill INPUT PARAMETERS
- The Text column parameter lets you choose the column of your input dataset containing text data.
- The Language parameter lets you choose among 59 supported languages if your text is monolingual. Else, the Multilingual option will let you set a Language column.
- This Language column parameter can use the output of the Language Detection recipe or ISO 639-1 language codes computed by other means.
- Review CLEANING PARAMETERS
- Select which types of token to filter in the Token filters parameter, among
- Punctuation: if all token characters are within the Unicode “P” class
- Stopword: if the token matches our per-language stopword lists
- These stopword lists are based on spaCy and NLTK, with an additional human review done by native speakers at Dataiku
- Number: if the token contains only digits (e.g. 11) or matches the written form of a number in the corresponding language (e.g. eleven)
- Currency sign: if all token characters are within the Unicode “Sc” class
- Datetime: if the token matches this regular expression for tokens like “10:04” or “2/10/2049”
- Measure: if the token matches this rule for tokens like “17th” or “10km”
- URL: if the token matches this rule for tokens starting with “http://”, “https://”, “www.” or matching a correct domain name
- Email: if the token matches this regular expression
- Username: if the token begins with “@”
- Hashtag: if the token begins with “#”
- Emoji: if one of the token characters is recognized as a Unicode emoji
- Symbol: if the token is not an emoji and if all token characters are within the Unicode “M”, “S” classes
- Activate Lemmatization to simplify words to their “lemma” form, sometimes called “dictionary” form.
- It uses spaCy per-language lookup data under the hood.
- Activate Lowercase to convert all words to lowercase.
- Select which types of token to filter in the Token filters parameter, among
- (Optional) Review ADVANCED parameters
- You can activate the Expert mode to access advanced parameters.
- The Unicode normalization parameter allows you to add a post-processing step to apply one of the unicodedata normalization methods.
- If you activate the Keep filtered tokens parameter, you will get an additional column for each selected Token filter.
- This is useful if you want to analyze the usage of tokens like emojis or hashtags in your text data.
- You can activate the Expert mode to access advanced parameters.
Output
- Output dataset: Dataset with additional columns
- Cleaned text after tokenization, filtering, and lemmatization
- If the Keep filtered tokens parameter is activated, one column for each filter: punctations, stopwords, numbers, etc.
Happy natural language processing!
Advanced topics
Supported languages
Language detection
Here are the 114 supported languages and their ISO 639-1 format:
- Afrikaans (af)
- Albanian (sq)
- Amharic (am)
- Arabic (ar)
- Aragonese (an)
- Armenian (hy)
- Assamese (as)
- Azerbaijani (az)
- Basque (eu)
- Belarusian (be)
- Bengali (bn)
- Bosnian (bs)
- Breton (br)
- Bulgarian (bg)
- Burmese (my)
- Catalan (ca)
- Central Khmer (km)
- Chinese (zh)
- Croatian (hr)
- Czech (cs)
- Danish (da)
- Dutch (nl)
- Dzongkha (dz)
- English (en)
- Esperanto (eo)
- Estonian (et)
- Faroese (fo)
- Finnish (fi)
- French (fr)
- Galician (gl)
- Georgian (ka)
- German (de)
- Greek (el)
- Gujarati (gu)
- Haitian (ht)
- Hausa (ha)
- Hebrew (he)
- Hindi (hi)
- Hungarian (hu)
- Icelandic (is)
- Igbo (ig)
- Indonesian (id)
- Irish (ga)
- Italian (it)
- Japanese (ja)
- Javanese (jv)
- Kannada (kn)
- Kazakh (kk)
- Kinyarwanda (rw)
- Kirghiz (ky)
- Korean (ko)
- Kurdish (ku)
- Lao (lo)
- Latin (la)
- Latvian (lv)
- Lithuanian (lt)
- Luxembourgish (lb)
- Macedonian (mk)
- Malagasy (mg)
- Malay (ms)
- Malayalam (ml)
- Maltese (mt)
- Maori (mi)
- Marathi (mr)
- Mongolian (mn)
- Nepali (ne)
- Northern Sami (se)
- Norwegian (no)
- Norwegian Bokmål (nb)
- Norwegian Nynorsk (nn)
- Nyanja (ny)
- Occitan (oc)
- Oriya (or)
- Panjabi (pa)
- Persian (fa)
- Polish (pl)
- Portuguese (pt)
- Pushto (ps)
- Quechua (qu)
- Romanian (ro)
- Russian (ru)
- Samoan (sm)
- Scottish Gaelic (gd)
- Serbian (sr)
- Shona (sn)
- Sindhi (sd)
- Sinhala (si)
- Slovak (sk)
- Slovenian (sl)
- Somali (so)
- Southern Sotho (st)
- Spanish (es)
- Sundanese (su)
- Swahili (sw)
- Swedish (sv)
- Tagalog (tl)
- Tajik (tg)
- Tamil (ta)
- Telugu (te)
- Thai (th)
- Turkish (tr)
- Uighur (ug)
- Ukrainian (uk)
- Urdu (ur)
- Uzbek (uz)
- Vietnamese (vi)
- Volapük (vo)
- Walloon (wa)
- Welsh (cy)
- Western Frisian (fy)
- Yiddish (yi)
- Yoruba (yo)
- Zulu (zu)
Spell checking
Here are the 37 supported languages and their ISO 639-1 format:
- Albanian (sq)
- Arabic (ar)
- Bulgarian (bg)
- Catalan (ca)
- Chinese (simplified) (zh)
- Croatian (hr)
- Czech (cs)
- Danish (da)
- Dutch (nl)
- English (en)
- Estonian (et)
- Finnish (fi)
- French (fr)
- German (de)
- Greek (el)
- Hebrew (he)
- Hungarian (hu)
- Icelandic (is)
- Indonesian (id)
- Italian (it)
- Japanese (ja)
- Latvian (lv)
- Lithuanian (lt)
- Persian (fa)
- Polish (pl)
- Portuguese (pt)
- Romanian (ro)
- Russian (ru)
- Serbian (sr)
- Slovak (sk)
- Slovenian (sl)
- Spanish (es)
- Swedish (sv)
- Thai (th)
- Turkish (tr)
- Ukrainian (uk)
- Vietnamese (vi)
Text cleaning
Here are the 59 supported languages and their ISO 639-1 format:
- Afrikaans (af) *
- Albanian (sq) *
- Arabic (ar) *
- Armenian (hy) *
- Basque (eu) *
- Bengali (bn)
- Bulgarian (bg) *
- Catalan (ca)
- Chinese (simplified) (zh) *
- Croatian (hr)
- Czech (cs)
- Danish (da)
- Dutch (nl)
- English (en)
- Estonian (et) *
- Finnish (fi) *
- French (fr)
- German (de)
- Greek (el)
- Gujarati (gu) *
- Hebrew (he) *
- Hindi (hi) *
- Hungarian (hu)
- Icelandic (is) *
- Indonesian (id)
- Irish (ga) *
- Italian (it)
- Japanese (ja) *
- Kannada (kn) *
- Latvian (lv) *
- Lithuanian (lt)
- Luxembourgish (lb)
- Macedonian (mk)
- Malayalam (ml) *
- Marathi (mr) *
- Nepali (ne) *
- Norwegian Bokmål (nb)
- Persian (fa)
- Polish (pl)
- Portuguese (pt)
- Romanian (ro)
- Russian (ru)
- Sanskrit (sa) *
- Serbian (sr)
- Sinhala (si) *
- Slovak (sk) *
- Slovenian (sl) *
- Spanish (es)
- Swedish (sv)
- Tagalog (tl)
- Tamil (ta) *
- Tatar (tt) *
- Telugu (te) *
- Thai (th) *
- Turkish (tr)
- Ukrainian (uk) *
- Urdu (ur)
- Vietnamese (vi) *
- Yoruba (yo) *
* Lemmatization not supported