Decoding MLOps: key concepts & practices explained
18 min read

A future-proof AI strategy must include the ability to deploy, monitor, and retrain models in production. It also must include the ability to adapt to changing situations by testing, training, and implementing new models quickly. That's the role of MLOps (sometimes referred to as LLMOps in the context of Generative AI). Whether working with traditional machine learning (ML) models or large language models (LLMs), the basic concepts are the same.
MLOps, short for machine learning operations, is the discipline of applying DevOps practices to machine learning workflows. It encompasses the processes and tools necessary to develop, deploy, monitor, and manage ML workflows and models in production environments efficiently and reliably.
Central to MLOps is the concept of continuous integration and continuous deployment (CI/CD). CI/CD is a software development practice aimed at automating the processes of code integration, testing, and deployment.

The journey from model development to deployment and maintenance can be fraught with challenges, including:
Scalability: Managing the MLOps lifecycle of ML models at scale.
Reliability: Ensuring consistent performance and reliability of deployed models.
Governance: Addressing regulatory compliance, ethical considerations, and data privacy concerns.
Collaboration: Facilitating the work between data scientists, machine learning engineers, and business stakeholders.
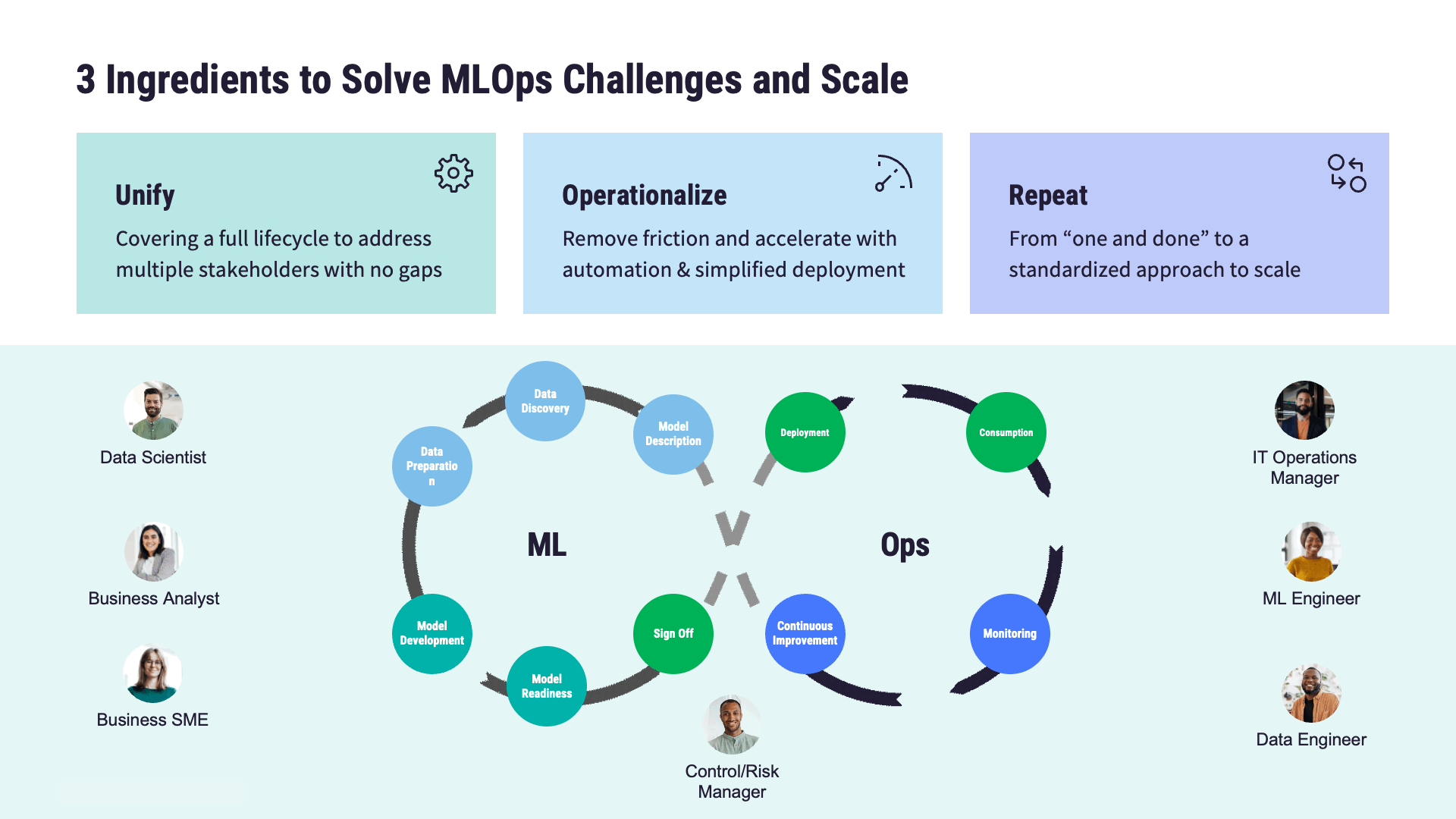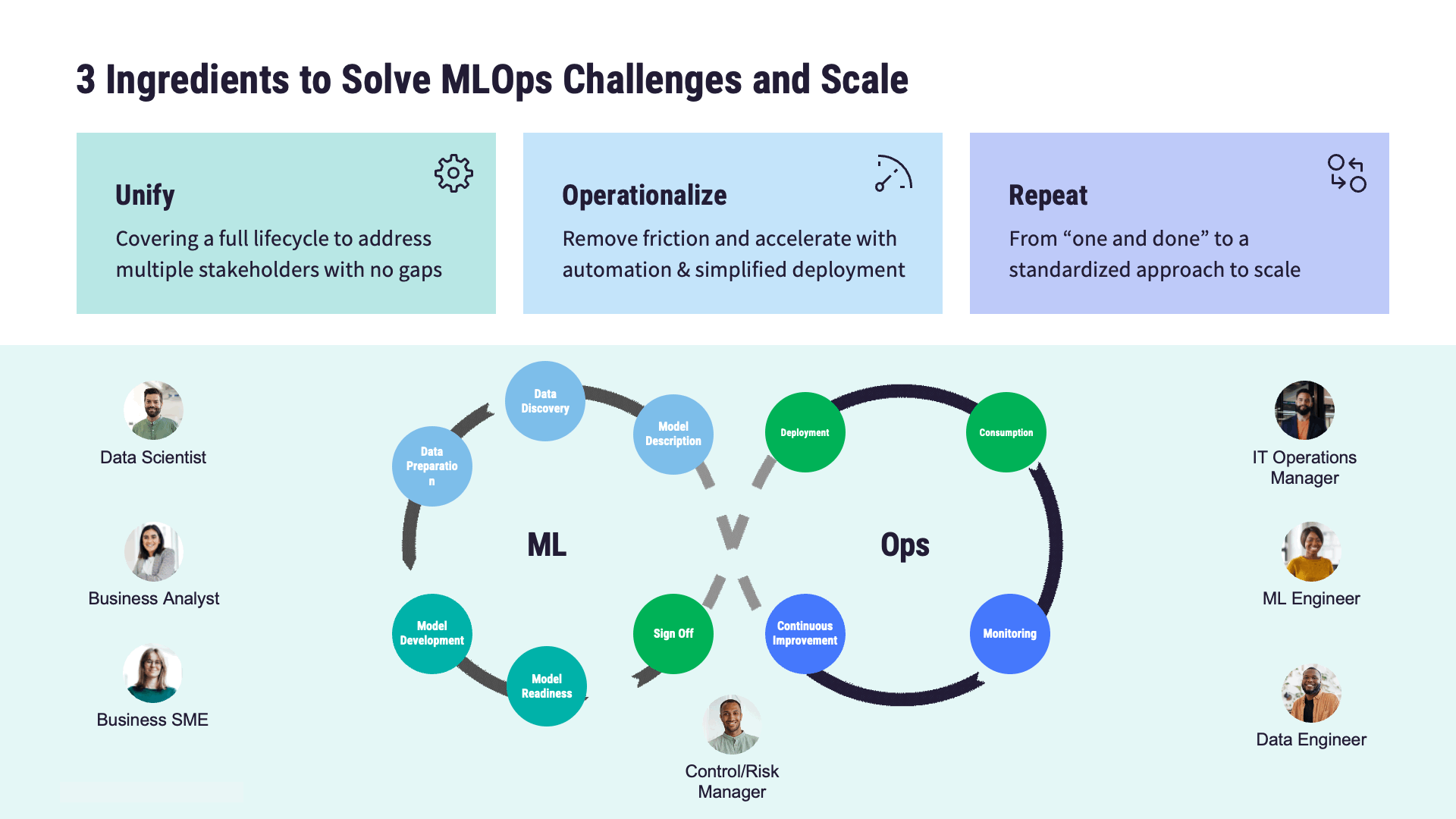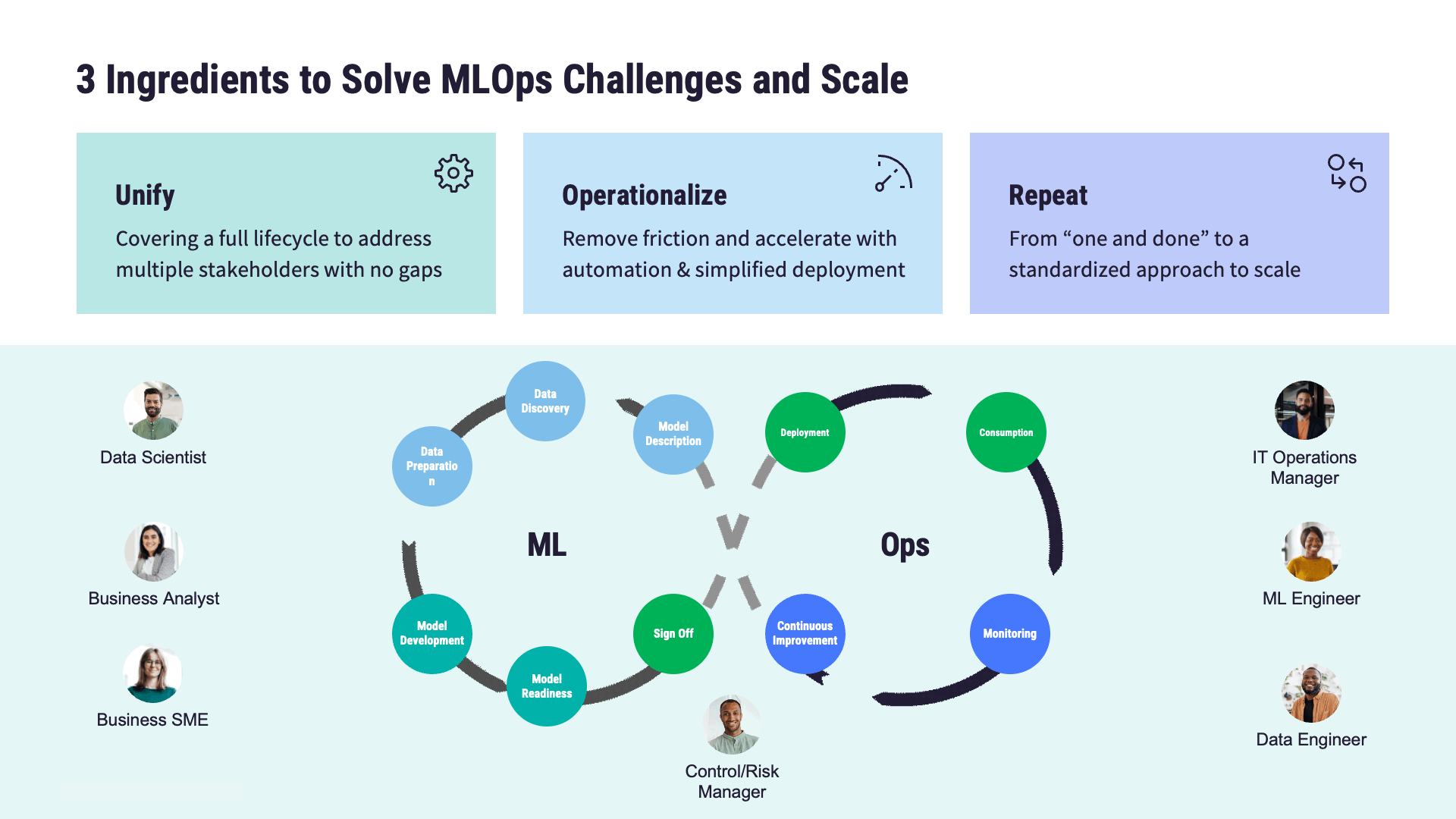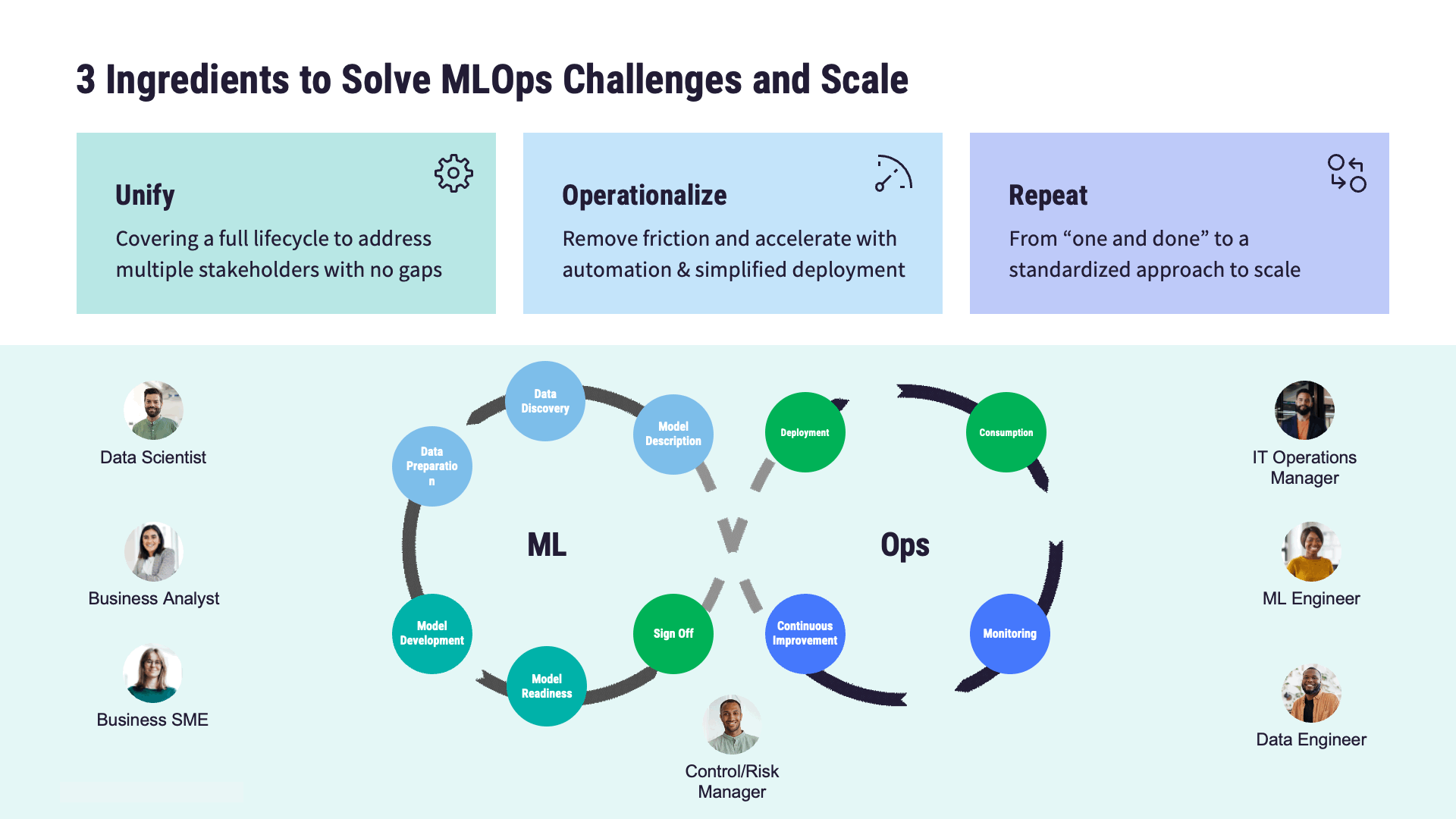
MLOps addresses these challenges by establishing standardized processes, MLOps best practices, and automation techniques. The end goal is to streamline the end-to-end lifecycle of ML models. Key stages along this journey, and therefore important components of an MLOps architecture, include:
Model development serves as a linchpin for transforming data into actionable insights. This process encompasses not only the development of traditional ML models but also of LLMs. Within MLOps, model development thus encompasses a diverse array of methodologies, from training predictive analytics models to exploring the creative possibilities of Generative AI.
In traditional ML model development, data preprocessing plays a crucial role. This involves not only capabilities any good data ops platform provides (accessing, joining, cleaning data, etc.), but also more specialized data transformations such as dataset reshaping, encoding unstructured text or images as numeric vectors, or converting categorical values to dummy variables to ensure data is structured in a way suitable for model training.
Feature engineering follows, where data scientists leverage domain knowledge or special techniques to capture important patterns within the data. Then, data scientists apply ML on the prepared data to identify the best-performing model for the given task. Hyperparameter tuning optimizes performance, while evaluation metrics such as accuracy, precision, and recall assess the model's effectiveness.
Development in the context of LLMs often involves qualitative assessments by human evaluators to gauge the quality and creativity of generated content. Data scientists might leverage different LLMs, such as open-source versus self-hosted models, or models from different providers. The ultimate goal in development is to find the best model (e.g., most performant and least costly) for the task at hand.
Model deployment marks the transition from experimental models to practical solutions that handle real-world data in production environments. After data scientists build or select the right model, the next step is deployment. The goal here is to ensure models' continuous operation and integration into business workflows.
MLOps streamlines this process by emphasizing automated deployment pipelines, containerization, and orchestration techniques that facilitate seamless and reproducible model deployments across diverse infrastructure environments.
Automated deployment pipelines serve as the backbone of efficient model deployment in MLOps. It enables organizations to automate the process of packaging, testing, and deploying ML models at scale. These automated MLOps pipelines streamline the movement of models from development to production. They do this by reducing manual intervention and minimizing the risk of errors or inconsistencies.
By automating repetitive tasks such as environment setup, dependency management, and deployment validation, organizations can accelerate the time-to-market for their AI models and solutions. All this while maintaining reliability and consistency across deployments.
The goal of model monitoring is to ensure that deployed models maintain their effectiveness and reliability over time.
Once deployed into production, continuous monitoring is essential for detecting deviations in model behavior. Continuous monitoring can help ensure accuracy as well as proactively identifies potential issues before they escalate. MLOps embraces a proactive approach to monitoring. That means tracking model performance metrics, data quality, and model drift in real time.
At the heart of model monitoring in MLOps lies the tracking of performance metrics. These key metrics provide insights into how well models are performing in production. Accuracy, precision, recall, and F1-score offer quantifiable measures of model effectiveness, enabling organizations to assess whether models are meeting predefined performance thresholds.
By monitoring these metrics over time, data teams can identify performance degradation or anomalies that may signal underlying issues. For example, teams can identify signs of concept drift, data drift, or model degradation to take corrective actions promptly.
In addition to performance metrics, MLOps encompasses tracking data quality and model drift. For example, MLOps tools should help teams assess the completeness and consistency of input data. The end goal is to ensure that models receive high-quality inputs for inference. Any deviations from expected data distributions or anomalies in data characteristics may indicate data quality issues that can impact model performance.
Similarly, model drift monitoring involves detecting changes in the relationship between input data and model predictions over time. Drift monitoring flags when models are operating outside their intended scope or when underlying data patterns have shifted. With this information, teams can retrain or recalibrate models as needed to maintain accuracy and relevance.
Model governance is paramount within the MLOps ecosystem. This is particularly the case in regulated industries where organizations must meet stringent compliance requirements. Organizations should ensure MLOps frameworks address governance and compliance challenges. This includes processes and controls for managing model versioning, tracking lineage, implementing access controls, and auditing model behavior.
Effective model versioning is a cornerstone of model governance in MLOps. It allows organizations to keep track of changes to models over time and ensure reproducibility and traceability. By maintaining a version history of models, organizations can easily revert to previous versions if needed. Plus, they can clearly track the evolution of models from development to deployment.
Proper versioning of course facilitates knowledge sharing among data teams. However, it also provides a clear audit trail for regulatory compliance purposes. Efficient MLOps should ultimately demonstrate transparency and accountability across model development and deployment processes.
In addition to versioning, proper tracking lineage is also essential for MLOps. Data lineage is about knowing how data teams made models and what data they used to train them. Of course, this is helpful for AI democratization across the organization in general. However, it also makes following compliance and regulatory requirements more seamless.
A robust ML model management program for strong MLOps would aim to answer questions such as:
What performance metrics are measured when developing and selecting models?
How do we make sure our models are robust, bias free, and secure?
What level of model performance is acceptable to the business?
Have we defined who will be responsible for the performance and maintenance of production ML models?
How are ML models updated and/or refreshed to account for model drift (i.e., deterioration in the model’s performance)? Can we easily retrain models when alerts come in?
How do we enhance models and ML projects' reliability for deployment?
How can we swiftly deploy ML projects to address ever-changing business needs in a fast-paced AI environment?
How are models monitored over time to detect model deterioration or unexpected, anomalous data and predictions?
How are models audited, and are they explainable to those outside of the team developing them?
How are we documenting models and projects along the AI lifecycle?
These questions span the range of the ML model lifecycle. Notably, their answers don’t just involve data scientists, but people across the enterprise. That’s because MLOps is not just about tools or techniques. It's about breaking down silos and fostering collaboration to enable effective teamwork on ML projects around a continuous, reproducible, and frictionless AI lifecycle.
Organizations deploying machine learning models at scale without proper MLOps practices in place will face issues with model quality and continuity. Teams without MLOps practices risk introducing models that have a real, negative impact on the business. Think, for example, of a model that makes biased predictions that reflect poorly on the company.
When it comes to MLOps vs DevOps, MLOps is a bit more complex than simply applying DevOps practices to ML. In fact, there are three key reasons that managing ML lifecycles at scale is challenging:
A fragmented AI tool landscape: In contrast to DevOps, the AI tools landscape is highly fragmented and constantly changing. It involves many heterogeneous technologies and practices. With a multitude of frameworks, libraries, and platforms available, organizations must select the right tools for their specific needs. At the same time, they must ensure compatibility and interoperability across the machine learning pipeline.
Multidisciplinary collaboration: Operating AI at scale is a team sport, and not everyone speaks the same language. Even though the ML lifecycle involves different teams (technology, business, etc.), they don't use the same tools. And in many cases, these different profiles don't even share the fundamental skills, making collaboration challenging. Bridging the communication gap between these diverse stakeholders is essential for driving successful MLOps implementations.
Skill set misalignment: (Most) data scientists are neither software engineers nor data engineers. Most are specialized in model building and assessment, and they are not necessarily experts in deploying and maintaining models. However, they often have no choice but to work on model deployment if they want to see their work in production. This discrepancy in skill sets can lead to inefficiencies and bottlenecks in the MLOps workflow.
As companies use more AI, it becomes harder to track and fix problems in a consistent way. This is particularly tough if teams use multiple platforms to build, deploy, and track models’ post-deployment health. These issues lead to the last three words an executive wants to hear: lack of oversight. The integration of DataOps, MLOps, and LLMOps into a unified domain, often referred to as “XOps”, draws on the shared goals and intentions of each discipline to create a cohesive approach, rather than relying on disparate and disjointed platforms and processes.
Amid the ever-increasing demand for rapid Generative AI digital delivery, it becomes imperative not only to overhaul the technology stack but also to revolutionize the underlying practices and processes that underpin AI deployment. To use an analogy, over decades, car manufacturing progressed from bespoke vehicles to highly automated assembly lines that standardized components, streamlining processes to achieve efficient and scalable production.
AI engineering is a similar transformation for AI initiatives, transitioning from custom-made models to standardized, scalable solutions. Both domains require a shift in mindset, standardization of processes, and a strong focus on implementation. By embracing AI engineering practices and ensuring Responsible AI deployment, organizations can leverage the power of AI to drive innovation and deliver value to society. So, where does XOps come in here?
Integrating ModelOps and DataOps within a unified XOps approach is a highly effective strategy for cultivating intellectual property (IP) that spans the entire AI lifecycle. This approach streamlines the consolidation of engineering practices along the AI value chain, encompassing both the experimentation phase and the long-term operationalization phase, all within a single, cohesive environment.
XOps seeks to standardize practices, processes, and technologies, ensuring organizations transition from one-off, custom AI models to building IP through a robust AI assembly line.
It’s neither a solitary nor an isolated endeavor. It is a collaborative and universal effort that captures knowledge along the lifecycle from workflow design to recipe creation and model validation, and this valuable knowledge should be preserved and leveraged on an agnostic platform.
Just as cars are assembled from various parts designed by different manufacturers, XOps thrives on being universal when it assembles, processes, governs, and operationalizes models from a range of providers.
Dataiku acts as the universal assembly line for XOps, fostering collaboration and innovation. By adopting this approach, organizations can drive AI innovation to new heights, creating scalable data products that deliver real value, moving us toward a future where AI enhances every aspect of our lives.

Let’s face it: Many data science teams are wasting time on the wrong things. For example, they spend too much time on data preparation and data management. Their production deployments are brittle and difficult to maintain. And building interfaces and applications for their end users distracts from their core expertise of experimentation and model development.
Bringing MLOps solutions into the picture is part of the answer.
Dataiku is the comprehensive solution for managing all models and projects in production for your organization. From data access and preparation, through modeling, app development, production deployment, and maintenance, Dataiku is one central platform. Whether data teams use traditional ML, Generative AI, or a combination of both, Dataiku accelerates their work.
One leading financial services institution uses Dataiku for MLOps and to detect potential risk. They support more than 125 stakeholders with mission-critical workloads at scale. Using Dataiku as their MLOps platform has resulted in an:
86% reduction in time spent optimizing and refactoring model code for production.
75% less pipeline production code written by ML engineers thanks to Dataiku visual recipes and GUI.
90% reduction in overall time to deployment compared to prior desktop solutions.
Integrating design and production environments can streamline the process of deploying ML projects seamlessly and efficiently. For example, by offering integrated design and production environments, Dataiku empowers organizations to transition seamlessly from model development to deployment. Plus, Dataiku eliminates the need for extensive refactoring or reconfiguration. Bottom line: Dataiku accelerates time to value so that teams drive real business results.
One of the key MLOps features in Dataiku is the Deploy Anywhere capability. With Deploy Anywhere, organizations can deploy models developed with Dataiku on any cloud ML platform. This flexibility eliminates vendor lock-in and empowers organizations to leverage the infrastructure of their choice. Deploy Anywhere facilitates a seamless transition between different cloud providers or hybrid environments, ensuring scalability, resilience, and cost-effectiveness in their ML deployments.
Furthermore, the seamless integration between design and production environments in Dataiku facilitates collaboration and knowledge sharing across cross-functional teams. Data scientists, data engineers, business analysts, and IT professionals can collaborate within a unified environment. Each person and team can leverage their respective expertise and skills to drive innovation and achieve shared business objectives.
This collaborative approach fosters agility and transparency throughout the ML lifecycle. With Dataiku, organizations quickly adapt to changing requirements and market dynamics while maintaining governance, security, and compliance standards.
After deployment, Dataiku's robust MLOps services come into play, automating the monitoring and maintenance of projects to ensure ongoing performance and scalability. This automation relieves the team from the burden of manual project upkeep. That means more data teams focus on driving innovation and other value-added tasks. With Dataiku's advanced monitoring features, organizations can effortlessly:
Track the health and performance of deployed models.
Detect anomalies or deviations in real-time.
Take proactive measures to address any issues that may arise.
One of the key advantages of Dataiku's MLOps capabilities is its seamless integration with experiment tracking. This allows team members to conduct iterative experiments and test different approaches with ease.
By leveraging Dataiku's experiment tracking functionality, data scientists and MLOps engineers achieve rapid iteration and optimization of models. This "fail fast" approach to experimentation fosters a culture of innovation and continuous improvement.
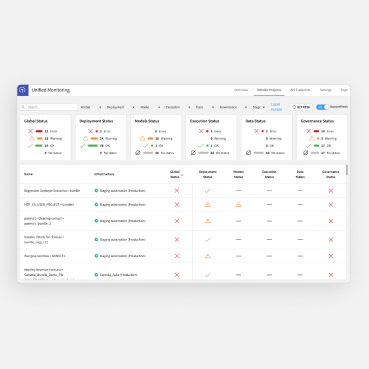
Dataiku has been evolving into the comprehensive solution for managing all models and projects in production. For example, Dataiku Unified Monitoring serves as a centralized hub for all visibility and oversight into MLOps processes. This provides organizations with a truly comprehensive view of their ML deployments.
From model performance metrics to data quality indicators and resource utilization statistics, Dataiku Unified Monitoring offers a holistic perspective on the health and efficiency of MLOps workflows. This centralized monitoring capability enables organizations to drive continuous improvement in their AI initiatives. With Dataiku Unified Monitoring, organizations can achieve greater transparency, efficiency, and agility in their practical MLOps operations. That means, bottom line — delivering more value faster and more reliably to stakeholders.
Bonus: With Dataiku's LLM Mesh, Prompt Studios, and RAG capabilities, data scientists can quickly enrich their models and projects with Generative AI. That means using all of the latest LLMs and services, all in an IT-approved environment.