A deeper understanding of deep learning
13 min read
When navigating the world of artificial intelligence (AI), you’ll likely encounter increasing complexity because of its sometimes confusing terminology. AI is sometimes used alongside (or even interchangeably with) terms like machine learning (ML) and deep learning.
To start diving into a topic like deep learning, we need to first define it, and then understand:
The distinctions between deep learning and related AI concepts (including GenAI)
When you would use — and not use — deep learning
Why it’s also important to learn about supervised and unsupervised learning when thinking about deep learning
How Dataiku can help with both ML and deep learning implementation at your organization.
What is deep learning? What is deep learning vs artificial intelligence? How does deep learning relate to GenAI and reinforcement learning?
In short, deep learning is a subset of machine learning, which is itself a subset of AI. Deep learning is also a building block to GenAI: Large language models (LLMs), a variety of GenAI, are a type of transformer network, and transformers are a specialized deep learning architecture. In simpler terms, LLMs are algorithms that employ deep learning methods. Hence, deep learning is not only a type of AI, but is also at the root of GenAI.
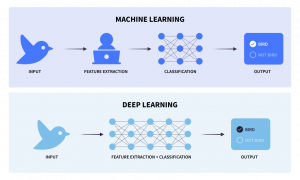
Traditional ML algorithms such as linear or logistic regression, random forest, or gradient boosting use underlying statistical techniques that enable machines to iteratively learn from labeled training data how to perform specific prediction or clustering tasks. This approach typically requires data scientists or domain experts to manually extract, engineer, and select which features (variables) to use in the model, which can be a time-consuming stage of any ML project.
Deep learning is a specialized, more modern subset of ML that uses neural network architectures with many layers — often referred to as “deep neural networks” — to model complex patterns in data. Common types of deep neural networks include convolutional neural networks (CNNs), recurrent neural networks (RNNs), and transformer networks.
In contrast with traditional ML models, deep learning models can automatically learn to extract features directly from raw data, reducing the need for manual feature engineering and making them very powerful for applications involving unstructured data like text, images, video, or audio. Although deep learning models excel in tasks such as image and speech recognition, natural language processing (NLP), and complex game playing where they can outperform traditional ML methods, these models are more complex and computationally intensive, typically requiring large amounts of training data and specialized hardware like GPUs.
Of course, handling more complex data means more complex algorithms. And to extract general enough complex patterns from complex data, you need lots (read: lots) of examples — much more than an ML model. As a guideline, you’d typically need from tens of thousands up to millions of labeled images to train a deep learning model from scratch.
With deep learning on the scene, we don't throw classic ML models out the window. For many classical prediction tasks that involve only structured, tabular data, ML approaches still are more suitable than deep learning because they are simpler and less computationally intensive.
For example, here’s a simple illustration: If I want to go from Manhattan to Brooklyn, should I walk or fly in a plane? It comes down to a simple tradeoff between cost and time spent versus the desired outcome. Flying from Manhattan to Brooklyn is the equivalent of using a deep learning model for a “simple” problem. In other words, for this particular problem, it’s not efficient at all!
Deep learning and GenAI are closely related, with deep learning serving as the foundational technology that enables GenAI. Deep learning, which involves neural networks with multiple layers, excels at learning complex patterns from large datasets.
In the context of GenAI, deep learning models such as Generative Adversarial Networks (GANs) and Transformer architectures (like GPT) are used to generate new content — whether it's text, images, or other data — by learning from existing data. Essentially, deep learning provides the underpinnings for the sophisticated model architectures that allow GenAI to create realistic and innovative outputs.
Like deep learning, reinforcement learning is a subset of ML where an agent learns to make decisions by performing actions that maximize cumulative rewards. The agent interacts with the environment, receives feedback in the form of rewards or penalties, and adjusts its actions based on this feedback. A common example is game-playing.
Reinforcement learning can also intersect with deep learning (aka: deep reinforcement learning) by leveraging deep neural networks to represent policies or value functions. This is especially valuable in environments with complex, high-dimensional state and action spaces, such autonomous driving or video games, where traditional reinforcement learning methods may struggle. Deep reinforcement learning is also useful when you have raw sensory inputs like pixels in images or audio because deep learning algorithms can do the feature extraction without the need for manual feature engineering, as described above.
Deep learning has swiftly gained popularity, especially as major breakthroughs in the field of artificial neural networks have driven companies across industries to implement deep learning solutions as part of their AI strategy.
From chatbots in customer service to image and object recognition in retail, deep learning has unlocked myriad sophisticated new AI applications. The opportunity and potential are immediately apparent, but is it always the right way to go?
The outstanding performance of deep learning algorithms with complex tasks that require huge amounts of data, combined with the increasing availability of pre-trained models on publicly-available data, have made deep learning particularly appealing to many organizations. However, as we will see, it doesn’t mean that deep learning is the answer to all business problems.
But how can we tell when deep learning is necessary, and when it isn’t? Each use case is individual and depends on your specific business objectives, AI maturity, timeline, data, and resources, among other things. Below are four general considerations to take into account before deciding whether or not to use deep learning to solve a given problem.
One of the main advantages of deep learning lies in being able to solve complex problems that require discovering hidden patterns in the data, or a deep understanding of intricate relationships between a large number of interdependent variables. Deep learning algorithms are able to learn hidden patterns from the data by themselves, combine them together, and build much more efficient decision rules.
Deep learning really shines when it comes to complex tasks, which often require dealing with lots of unstructured data, like image classification, NLP, or speech recognition, among others.
For simpler tasks that involve more straightforward feature engineering and don’t require processing unstructured data, classical ML might be a better choice.
While deep learning does reduce the human effort of feature engineering because much of the feature extraction work is done automatically by the algorithm, it also increases the difficulty for humans to understand and interpret what the model is doing. In fact, as mentioned before, interpretability is one of deep learning’s biggest challenges.
When evaluating any ML model, there's usually a fundamental tradeoff to be made between accuracy and interpretability, which is the crux of the challenge of Explainable AI. Deep networks have achieved accuracies that are far beyond that of classical ML methods in many different domains, but as they are modeling very complex situations with high non-linearity and interactions between inputs, they are nearly impossible to interpret.
However, because of the direct feature engineering involved in classical ML and the availability of more interpretable machine learning algorithms such as linear/logistic regressions and decision trees, there are more tools and analyses accessible to data scientists to help interpret and understand what’s happening behind the scenes.
Even with increasing accessibility, deep learning in practice still remains a complicated and expensive endeavor. Due to their inherent complexity, the large number of layers, and the large amounts of data required, deep learning models are very slow to train and require a lot of computational power, which makes them very time- and resource-intensive.
Dataiku’s hot take for AI in 2024 was around the fact that graphics processing units, or GPUs, have practically become a requirement to execute deep learning algorithms. GPUs are very expensive, but hardware acceleration and a distributed or parallelized training process are almost a necessity for large-scale deep learning projects due to the computational and memory demands of training these complex models.
Although GPUs and parallelization can speed up training for certain classical ML tasks where you’re dealing with large datasets or using ensemble methods, many traditional ML tasks may not require distributed training. Classical ML algorithms can be trained normally with just a decent central processing unit (CPU), without requiring the best hardware. Because they aren’t so computationally expensive, organizations can also iterate faster and test different techniques in a shorter period of time.
One of deep learning’s main strengths is the ability to handle more complex data types and relationships, but this also means that the algorithms used in deep learning are more complicated. Again, try not to think of either supervised machine learning or deep learning as a model guessing what the right answer is.
To extract latent patterns from data, you’ll need to provide lots of labeled examples — typically tens of thousands of labeled samples for fine-tuning a pretrained model, or up to millions to train a model from scratch.
Without a sufficiently large corpus of precisely labeled, high-quality data, you risk getting disappointing results in some business cases. Organizations face challenges when clearing, preparing, and labeling data, and these processes often take up a massive volume of time and resources from teams — time and resources that could be better spent building the next ML models or pushing them into production.
We’ve arranged all of these considerations into a handy section that you can reference later:

Whether you decide to go with classical ML or deep learning for a certain data project, a common thread is that there should be human intervention, evaluation, and decision-making involved in every step of the process. The human-in-the-loop augmented intelligence is the key to truly responsible and transparent AI.
So, is deep learning supervised or unsupervised? Note: It can be both. For example, image classification using a CNN is an unsupervised deep learning task.
By contrast, anomaly detection using autoencoders is an example of an unsupervised deep learning task. In the next section, we'll explore some examples where it's typically one or the other.
In each subsequent section, we’ve incrementally deepened our understanding of deep learning. There’s a healthy amount of information here, but putting it all into practice could prove even more difficult without additional help.
This is where we come in.
Because you know a bit more about deep learning now, it’s time to start investigating and exploring its real-world capabilities for yourself. There are so many great opportunities to start your deep learning journey in Dataiku as the platform that truly puts the power of AI in your hands.
With everything from no-code solutions with AutoML, to full-code, completely customizable model building, Dataiku makes it easy to involve more people in the ML and deep learning creation process. Features for model explainability and interpretability mean that you can have a better understanding of model outcomes, comprehend the impact of different variables on model performance, and proactively monitor results.
Pre-built AutoML templates make it simple to dive into even advanced deep learning techniques such as image classification or object detection or specialized types of ML such as time series forecasting or causal predictions — all without needing to code.

In this last section, we’ll cover every aspect, from labeling your data to building your first model with visual ML or code notebooks to jumpstarting your process with transfer learning. You can also jump right into deep learning by checking out these Dataiku walkthroughs to build your first model, explore NLP, or visual deep learning.
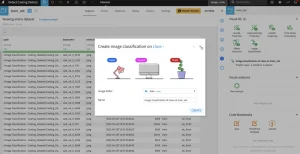
Dataiku provides visual, no-code deep learning templates for pre-defined use cases like computer vision, but for custom tasks, you may find the low-code path suits your needs better. This approach requires a little bit of coding skill to define the deep learning architecture or perform custom data pre-processing or augmentation, and Dataiku handles the rest.
From features handling and hyperparameter search optimization to deploying and scoring the model, this becomes like any other model created and managed in Dataiku. Since deep learning models require so much compute power, Dataiku supports training on CPUs up to multiple GPUs and through container deployment capabilities. You can easily train and deploy models on cloud-enabled dynamic GPU clusters.
Next up are the unlimited capabilities of coding within Dataiku. Get ready to code your heart out and build that custom deep learning model you’ve always dreamed of deploying because in this case, Dataiku doesn’t restrict you to the algorithms that are part of its visual ML capabilities. You can code your own model, either in Python or Scala, or start with the above visual ML and customize to build out your model for your unique needs. From Keras, TensorFlow, TensorBoard, and more — the world is your oyster!
You’ll have plenty of support along the way for the latest and greatest deep learning algorithms, libraries, and environments. Get to coding!
If you’re training a fresh model or fine-tuning a pre-trained models, you’ll need a lot of labeled data to teach the algorithm how to perform your task, which can be a big undertaking to obtain. If you don’t have labeled data yet, don’t worry!
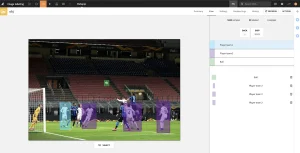
Dataiku streamlines data annotation initiatives with a built-in, managed labeling recipe that helps teams efficiently label tabular, textual, or image-based datasets. For example, the image below shows how a labeler might annotate an image with bounding boxes denoting classes of interest, in order to teach the model how to detect certain objects within a larger picture.
You could even implement an active learning approach to prioritize the samples for labeling that are most informative for the model’s learning process, such as records where the model is least confident in its predictions, records from all corners of the input space to ensure diverse coverage of observations, and records that are representative of the overall data distribution and will likely generalize well.
Active learning is useful because it improves model performance while minimizing labeling costs and effort, making it particularly valuable when labeled data is scarce or expensive to obtain.
We’ve now defined deep learning, discussed the differences and similarities between deep learning and other concepts like AI, when you’d consider using deep learning, why you should also understand the difference between supervised and unsupervised learning, and how Dataiku solutions can help you implement ML and deep learning solutions of your own.
Whether we’re defining ML, deep learning, or AI, the common foundation that they all share is that each of these areas should be human driven. Bringing a human into the intelligence — like you — is the key to truly responsible and transparent AI.
Although Everyday AI is at peak hype at the moment, bringing attention and enthusiasm to the data science space, it’s very important for organizations to continue to educate themselves and build a responsible mission and vision for the implementation of AI to have a semblance of true impact.
Tags