Why does explainable AI matter in financial services?
Explainable AI matters in financial services because regulators now require institutions to defend individual AI decisions — and most cannot. According to the "Global AI confessions report: data leaders edition," based on a Dataiku/Harris Poll survey, 95% of data leaders admit they could not fully trace AI decisions from input data through model output if asked by regulators.
In financial services, that failure surfaces where it costs the most: in the reasoning behind credit denials, in responses to customer disputes, in the documentation underlying suspicious-activity reports, in examiner challenges, and in trading decisions a counterparty contests.
Opaque models, GenAI systems, and agents compound three risks:
1. Regulatory fines arrive when adverse-action reasons cannot be produced, or when a high-risk system (whether a scoring model or an AI agent processing credit applications) lacks the documentation an EU AI Act is expected to demand.
2. Algorithmic bias enters when training data encodes historical patterns no one has stress-tested; when GenAI outputs reflect those patterns without attribution or an audit trail, teams have no way to understand and diagnose where the bias originated.
3. Reputational damage follows quickly and compounds. A single unexplainable decision that reaches a regulator, a journalist, or a customer advocate is enough to trigger scrutiny that extends well beyond the original case.
Operating transparently has its own returns. Customers trust outcomes they can question. Reason codes expose features no analyst would have prioritized, which improves internal decision quality. Regulatory alignment compounds: an explanation validated once flows through to adverse-action notices, model risk reports, and audit packets without rework.
The table below compares how opaque and explainable AI systems perform across key operational capabilities.
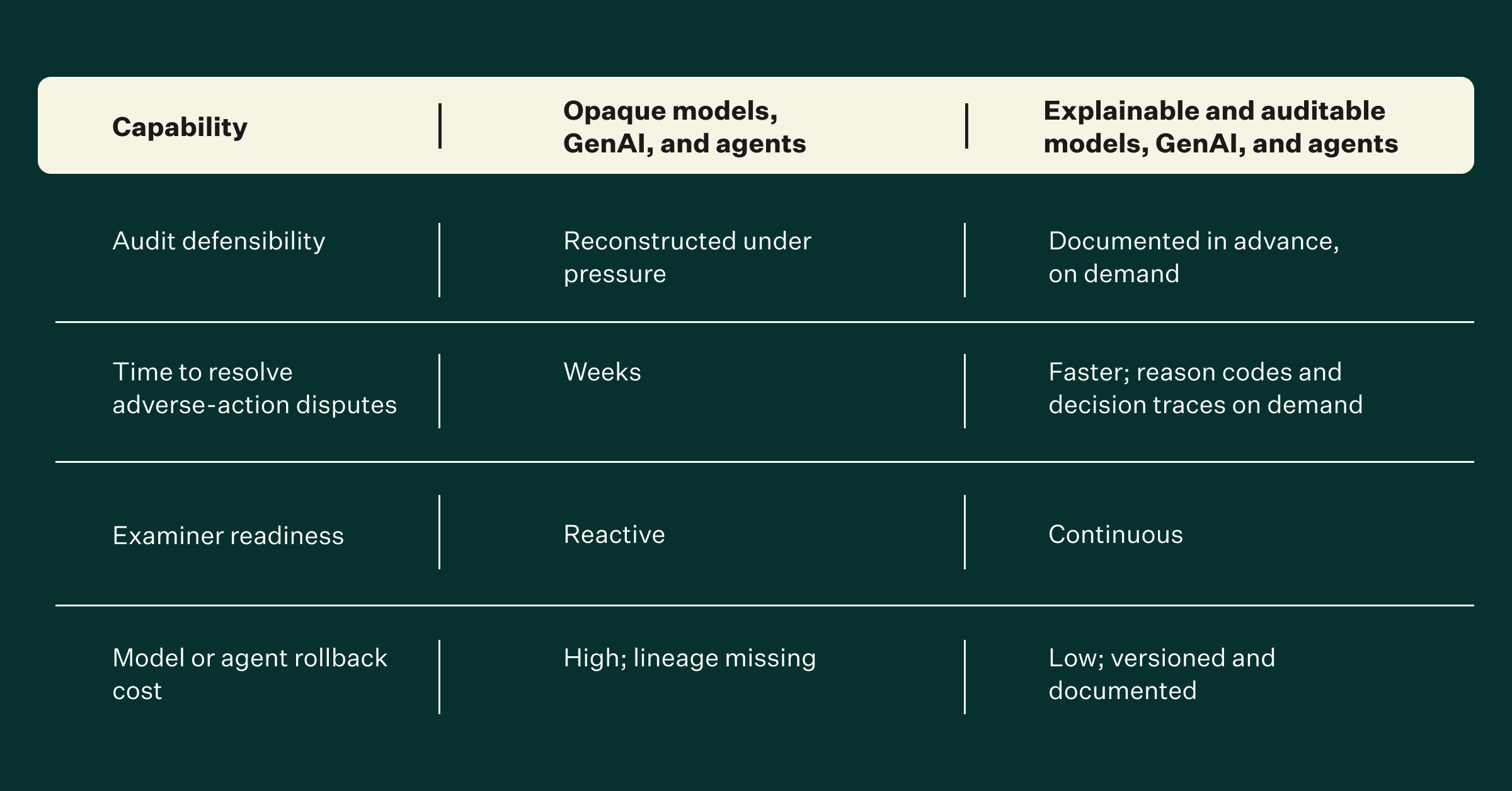
Click on the image above to zoom into full PDF
The business case for explainability is driven partly by operational advantage and partly by specific regulatory requirements institutions must now meet.
The regulatory landscape and mandatory transparency requirements for AI in finance
Several overlapping regulations set the floor for any AI system that influences regulated decisions.
The EU AI Act classifies credit scoring, creditworthiness assessment and life and health insurance risk pricing as high-risk uses where those systems assess natural persons, not assets.
Obligations include technical documentation, data governance, human oversight, transparency to deployers, and post-market monitoring.
High-risk obligations were originally set to take effect in August 2026, with a provisional agreement reached in May 2026 to defer them to December 2027, pending formal adoption.
In the United States, Supervisory Letter SR 26-2 defines revised model risk management expectations and supersedes the 2011 model risk guidance.
Guidance from the Federal Reserve, OCC, and FDIC reinforces that machine learning inherits the same discipline: documented purpose, validated logic, monitored outcomes, and a named owner. SR 26-2 explicitly places generative AI and agentic AI outside its scope, noting they are novel and rapidly evolving — though the guidance directs institutions to apply existing risk management principles to determine appropriate controls for those systems.
ECOA and Regulation B require adverse-action notices that state specific principal reasons, which translates into per-decision reason codes that a model or agent can produce on demand.
GDPR Article 22 governs solely automated decisions with legal or similarly significant effects, while Article 15 gives individuals the right to obtain meaningful information about the logic involved in any processing that concerns them.
Singapore's MAS FEAT principles alongside the 2024 AI model risk management information paper and the 2025 Guidelines on AI Risk Management , Hong Kong's HKMA expectations on AI in banking, and APRA CPS 230 in Australia push institutions in the same direction.
Five questions consistently arise in compliance and audit conversations across these jurisdictions, regardless of which specific framework applies:
-
Can you produce the input features used for this specific decision?
-
Who approved this model, GenAI system, or agent for production, and when?
-
When was bias last tested, and what method was used?
-
What changed between version N and N+1, and who signed off?
-
Is the explanation method itself validated?
Those questions reveal an important distinction that these regulatory frameworks are beginning to formalize: explainability and auditability are related but not the same. Explainability answers the questions of how and why a decision was made: the mechanical logic of inputs and weights.
Auditability answers the evidentiary question of how it was made — which system, which version, which data, with which human sign-off, at what timestamp. Regulators require both. An explanation without an audit trail is not enough for an SR 26-2 review. An audit trail without a meaningful explanation does not satisfy GDPR Article 22 or ECOA adverse-action obligations.
In regulated markets, governance infrastructure is what makes both possible at scale — and it is a prerequisite for operating, not an optional add-on. Dataiku, the Platform for AI Success, unifies data preparation, machine learning, generative AI (GenAI), agents, and governance in one environment.
Dataiku Govern provides model documentation, version control, risk classification, and lineage that map directly to EU AI Act, GDPR, and SR 26-2 documentation requirements, while the platform's broader governance infrastructure extends those controls to GenAI and agent deployments. Dataiku's AI regulatory readiness playbook covers how to structure those controls in practice.
Once the regulatory floor and the governance infrastructure that supports it are clear, the practical question becomes which technical approaches can deliver the required level of transparency across different model, GenAI, and agent types and decision contexts.
What are the core techniques for achieving explainability across models, GenAI, and agents in finance?
Two families dominate for traditional ML models. Ante-hoc approaches use inherently interpretable models: logistic regression, generalized additive models, traditional scorecards, monotonic gradient-boosted trees, and shallow decision trees.
The model itself is the explanation. Post-hoc approaches layer explanation methods onto opaque models optimized for accuracy first.
Within those two families, four techniques carry most regulated finance audits:
1. SHAP (SHapley Additive exPlanations) assigns each input feature a contribution to the prediction, grounded in cooperative game theory. It produces consistent global and per-decision attributions, which is why it has become the default for regulated finance.
2. LIME (Local Interpretable Model-Agnostic Explanations) builds a small surrogate model around a single decision. It is fast, useful for spot checks, and the right tool when SHAP is computationally prohibitive on a specific model class.
3. Counterfactual explanations describe the smallest change to the input that would have flipped the decision. They are the natural fit for adverse-action notices because they answer the customer question ('What would I need to change?') directly.
4. Inherently interpretable models (monotonic GBMs, scorecards, GAMs) sidestep the explanation problem by being legible by construction.
Choose by use case, not by what is popular.
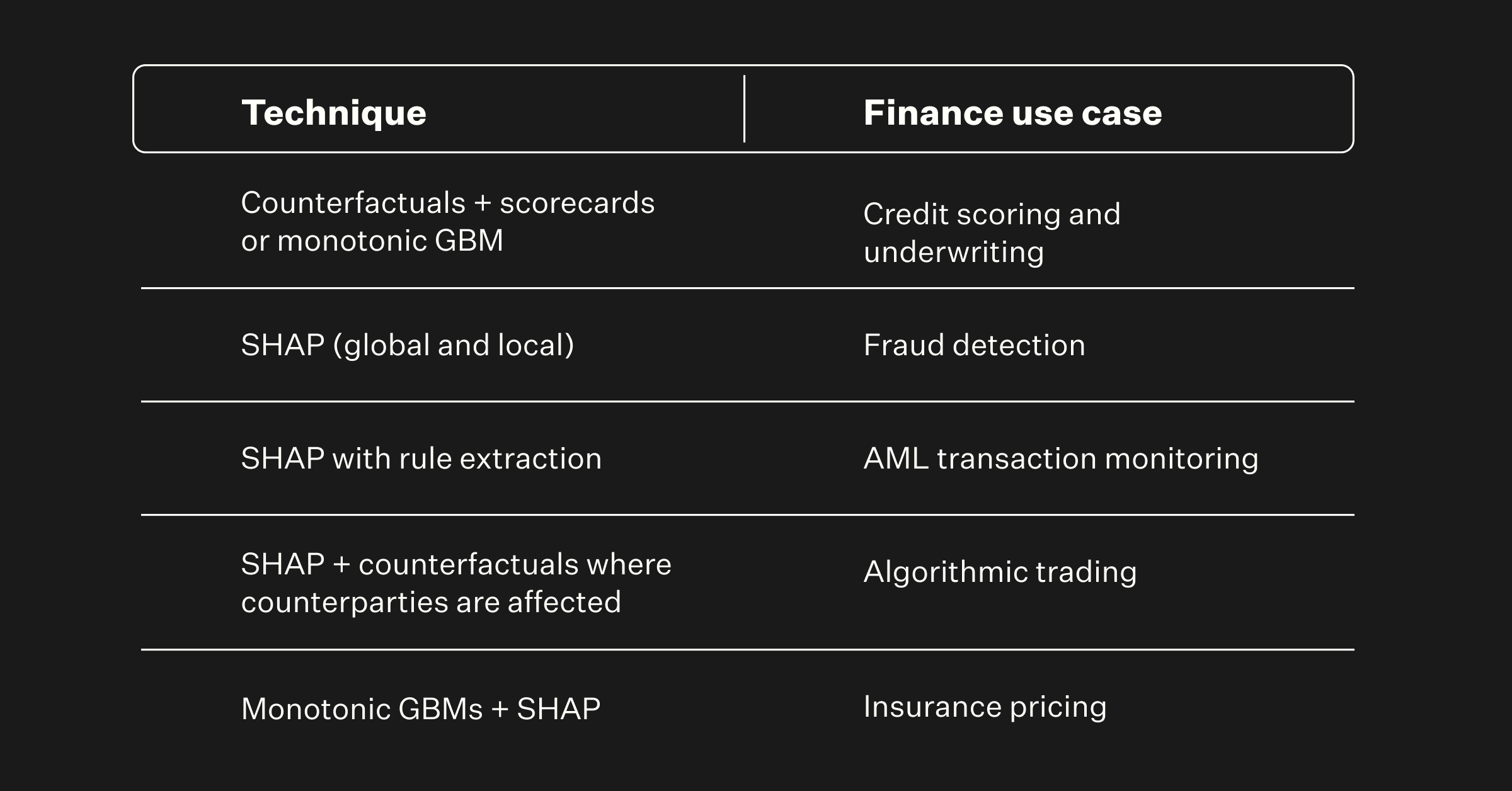
Click on the image above to zoom into full PDF
Fraud detection is worth calling out specifically. The decision happens in milliseconds, but the explanation must be available for audit after the fact. What compliance teams need to require is that explanation generation and audit logging are part of the same governed workflow as the decision itself, not a separate process reconciled later.
Dataiku's built-in explainability modules embed SHAP, partial dependence plots, and feature importance directly into the ML lifecycle, so the audit record is produced alongside the decision rather than reconstructed from it.
The accuracy-transparency trade-off resolves cleanly under regulatory exposure. When the cost of opacity exceeds the marginal accuracy gain, pick the interpretable model. Otherwise, pair the opaque model with rigorous post-hoc explanations and counterfactual auditability.
Choosing the right technique per use case is the first discipline; deploying it consistently across the organization and extending it to GenAI and agents requires a structured rollout framework.
Agent decisions themselves can be made explainable using Kiji Inspector, the open-source framework from Dataiku's 575 Lab, which inspects the model at the moment it commits to a tool choice and translates that into a traceable explanation (currently supported for NVIDIA Nemotron open models).
A 5-step framework for implementing auditable and explainable AI in financial services
Treat explainable AI in finance as a pipeline you install once, not a fix you bolt on per model, GenAI application, or agent deployment.
Step 1
Inventory existing models, GenAI applications, and agents, and assign risk tiers. Anchor tiers to regulatory exposure.
Tier 1 covers high-risk uses under the EU AI Act and SR 26-2: credit decisioning, AML, trading at scale, and insurance pricing — whether those decisions are made by a traditional model, a GenAI system, or an automated agent. Tier 2 covers material but not customer-facing systems. Tier 3 covers internal analytics. The deliverable is a registry with risk classifications signed off by Line 2.
Step 2
Match the explainability technique to each system type and risk tier.
Tier 1 ML models get SHAP plus counterfactuals plus an interpretable challenger model run in parallel for adverse-action defensibility. Tier 2 models get SHAP or LIME based on model class and latency. Tier 3 gets standard feature importance and drift monitoring.
For GenAI applications in customer-facing roles, technique selection shifts to output logging, prompt attribution, and retrieval-source tracing for retrieval-augmented generation (RAG) applications.
Dataiku Visual ML and built-in explainability modules keep technique selection inside the same environment as training, so each explanation is reproducible from the lineage that produced the prediction.
Step 3
Build human oversight loops and audit logging infrastructure.
This is the auditability step. Name the gates: production approval, threshold-change approval, exception review, and re-approval at major retrain. For agents, add action-trace logging that captures every tool call, reasoning step, and output alongside the decision timestamp and reviewer identity.
Audit logs for models capture inputs used, model version, explanation method, reviewer identity, and decision timestamp. For GenAI systems, logs capture the prompt version, retrieved sources, and output alongside any human review step.
Dataiku Govern's lineage and audit trail give compliance officers a record aligned with SR 26-2 and the EU AI Act that they can show an examiner without translation. Dataiku's unified monitoring tracks post-deployment performance so anomalous decision clusters can be correlated with model degradation periods and surfaced via automated alerts.
Step 4
Validate explanations with stakeholder personas.
Model validation runs on two tracks: technical (performance to baseline, benchmarking, data checks) and governance (qualification, approvals, documentation). Together, they answer whether every regulatory requirement was met and whether the model's outputs and aggregate performance can be explained. Compliance officers, internal auditors, business users, and consumers should each be able to act on the explanation, not just read it.
This is also where operationalization happens: Define who owns explainability review across the three lines of defense, what team structure supports ongoing validation, and how to train non-technical stakeholders to interpret SHAP plots, counterfactuals, and agent decision traces.
Step 5
Document methodology and monitor for drift and ongoing compliance.
Determine your review period for each use case; some require monthly or weekly cadences, others annual. Drift triggers re-explanation, not only retraining, because input shifts move both predictions and the features driving the explanation.
For agents, behavioral drift — changes in the topics agents engage with or the actions they take — requires separate monitoring from model prediction drift. High-risk systems require continuous monitoring across all three system types.
Dataiku embeds explainability into the ML lifecycle as an integral part of model development and deployment, with governance controls extending across GenAI and agent workflows on the same platform.
A framework addresses the technical architecture; the harder work is assigning review, approval, and audit responsibilities so explanations are actually used, not just rendered.
Building auditable AI workflows in financial services
Explainability tells you why a decision was made. Auditability tells you how to prove it. The five-step framework above covers the technical mechanics. What it does not cover is what an auditable AI workflow looks like from a compliance officer's vantage point during a review.
In practice, auditability means being able to answer five questions without reconstructing anything under pressure: which system version made this decision, on which data, with which human sign-off, at what timestamp, and with what explanation on record.
Dataiku Govern provides the model registry, approval workflows, audit logs, and lineage tracking that make those answers available on demand, with the platform's broader governance infrastructure extending the same controls to GenAI and agent deployments.
Operationalizing explainability: change management, team structure, and adoption
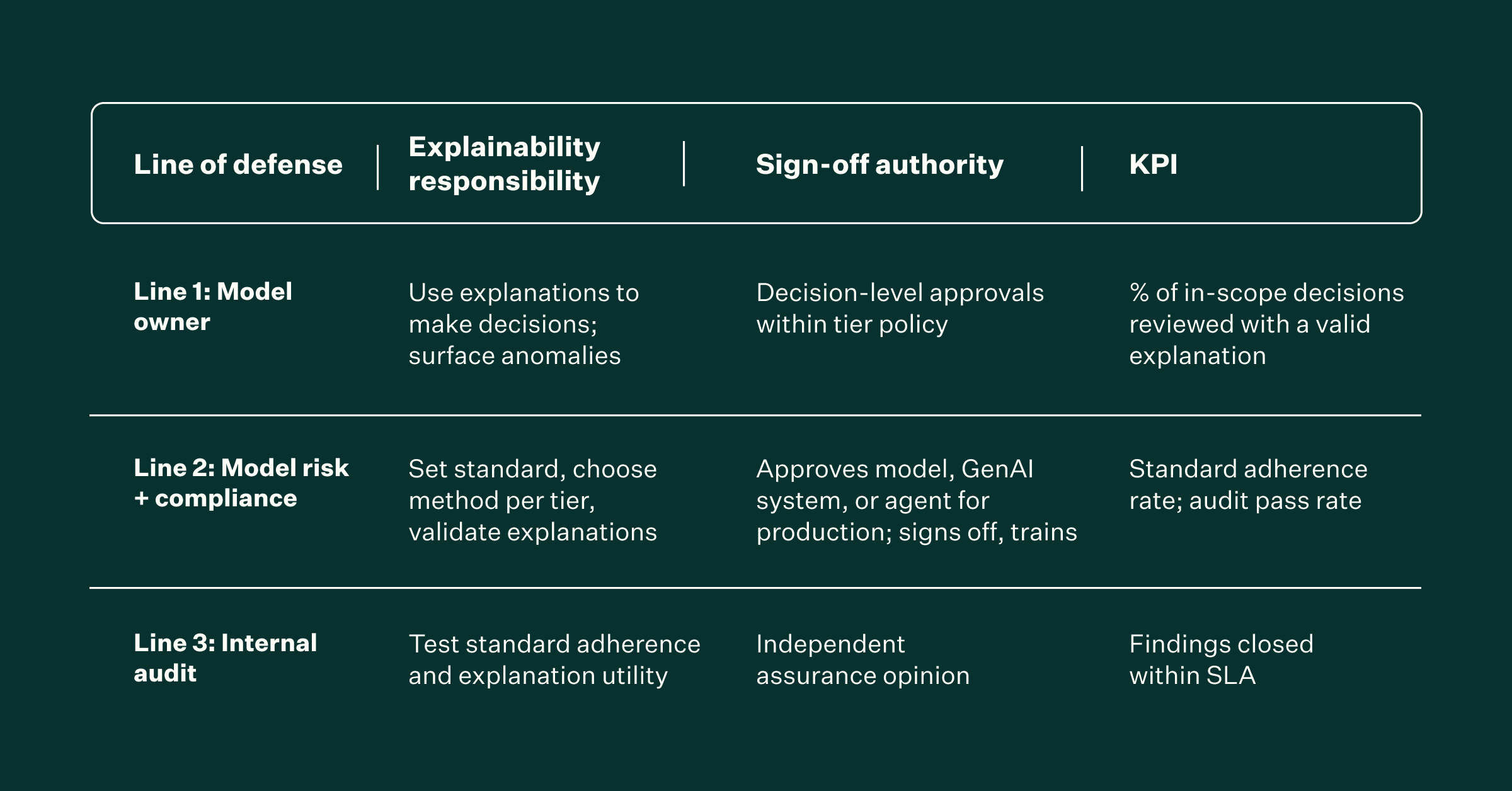
Tooling does not create explainability. Clear ownership does. Institutions that pass audits without panic share three traits: defined roles across the three lines of defense, a single pane of glass that centralizes governance activities, and a deliberate adoption program.
Team structure across the three lines of defense:
-
Line 1 includes model owners in the business who use explanations to make defensible day-to-day decisions.
-
Line 2 — model risk and compliance — owns the standard: which method per tier, what the explanation must contain, and when it must be regenerated. Name an explainability lead inside Line 2 (typically a model risk manager or compliance technology lead) who carries the standard across credit, fraud, AML, and trading.
-
Line 3, internal audit, tests whether the standard is followed and whether explanations actually shape decisions.
Click on the image above to zoom into full PDF
Tooling governance
Most institutions already have six or more disparate point tools, each hosting relevant information toward a central governance initiative. The gap is rarely the tools themselves; it is the connecting layer that ties development, explainability, lineage, and audit logging into a single coherent record.
Per-model SHAP scripts in notebooks do not survive an audit because they are not versioned, lineage-tracked, or reproducible the way a regulator expects. A governance layer that connects those tools can.
Dataiku connects model development, explainability, governance, and audit logging, so compliance, model risk, and data science use the same model record rather than reconciling outputs across notebooks, spreadsheets, and PDFs.
The same applies to GenAI and agent outputs: logs, prompt versions, and action traces all sit within the same governed environment.
Adoption levers that decide whether explainability sticks. Four levers matter:
Explanation literacy: Train compliance officers and front-line decision-makers to read SHAP plots, counterfactuals, and reason codes the way they read a credit report.
Examiner readiness drills: Rehearse the audit-question checklist quarterly; treat it as a fire drill rather than a slide deck.
An explanation style guide: Standardize the narrative across models, GenAI outputs, and agent traces so reviewers are not relearning the format on every audit.
Adoption KPIs: Track the share of in-scope decisions with a valid explanation rendered and acknowledged.
Change-management failure modes to watch
-
Explanations rendered but never read
-
Compliance cut out of model approval workflows
-
Data scientists owning explainability with no business-facing translation layer
-
Explanations that diverge from the adverse-action notice language consumers receive
-
Each can create enforcement exposure, and each is fixable with defined ownership and approval gates rather than another tool
Even with clear ownership in place, three categories of practical challenge slow most institutional rollouts and need to be addressed directly.
Explainable AI challenges, trade-offs, and best practices for financial institutions
Three categories of hurdles slow most operational rollouts, with a fourth emerging specifically from GenAI and agent deployments.
Technical: real-time inference latency
SHAP on high-dimensional models can exceed the latency budget for fraud and trading decisions made in tens of milliseconds. Mitigations include approximate Shapley methods, pre-computed reason codes for common decision paths, model surrogates, or pushing full SHAP to an asynchronous audit channel while a lightweight explanation surfaces at decision time.
Dataiku's approach to real-time explainability for fraud detection addresses this directly, separating the speed of the decision from the completeness of the audit record.
Regulatory complexity: differing jurisdictional standards
Multi-jurisdictional institutions operate under overlapping obligations: EU AI Act high-risk rules, SR 26-2 governance, ECOA reason codes, GDPR Article 22, DORA, and APAC frameworks.
Map the strictest applicable regulation per use case as a starting ceiling rather than splitting controls per market. Then run an alignment exercise across all applicable frameworks: the strictest standard does not automatically subsume every requirement, and timing obligations and reporting structures vary by jurisdiction.
UX and user fatigue: explanation overload
Too many explanations dilute the few that matter. Use selective disclosure (full explanation on adverse outcomes, summary on approvals), targeted stakeholder training, and an explanation style guide, so reviewers see the same shape each time.
GenAI and agent-specific explainability: a distinct challenge
Chain-of-thought is not an audit trail. Attention weights are not explanations. Prompt-based reasoning is not reproducible across sessions. These are not limitations of current tools. They are structural properties of how generative models and autonomous agents work.
The defensible posture for regulated finance is to restrict GenAI to use cases where output is reviewed before action, and where source citation and retrieval lineage are captured with every output.
For agents, require action-trace logging at every step and human-in-the-loop checkpoints for any decision with regulatory consequences. Maintaining audit trails at scale, version-controlling GenAI prompts and agent configurations, and ensuring logs are complete enough to satisfy regulators are the three operational challenges institutions face most often when extending explainability beyond traditional models.
Best practice and regulatory readiness converge in the same place: the compliance officer's approval and audit process. Working through those hurdles positions explainability as a control that reduces audit work, rather than another audit liability.
Make explainability your compliance advantage
Examiner expectations changed across 2025 and 2026. Adverse-action specificity, model documentation, lineage, and explanation validation are baseline requirements, not optional audit requests. The cost of opacity surfaces on every cycle — and that cost now extends to GenAI outputs and agent decisions, not just traditional model predictions.
Institutions that build explainability and auditability infrastructure before deployment, rather than reconstructing it under examiner pressure, spend less time on each audit cycle and carry less regulatory exposure as their AI footprint grows.
The five-step framework, plus clear ownership, gives compliance teams a practical path to cover all three system types. Dataiku Govern and Dataiku Visual ML provide the model records, lineage, explainability, and audit trails needed across credit, fraud, AML, insurance, and trading — and extend that governance to GenAI applications and agent deployments running on the same platform.
.png?width=928&height=620&name=Thumbnail%20link%20(2).png)