




Version 6.0 – December 2019
Fully Managed Kubernetes
Dataiku 6 enables users to easily spin up and manage Kubernetes clusters (on AWS, Azure, or GCP) from inside the Dataiku platform. This means that non-admin users can now quickly spin up Kubernetes clusters for optimized execution of Spark or in-memory jobs.
SQL Pipelines
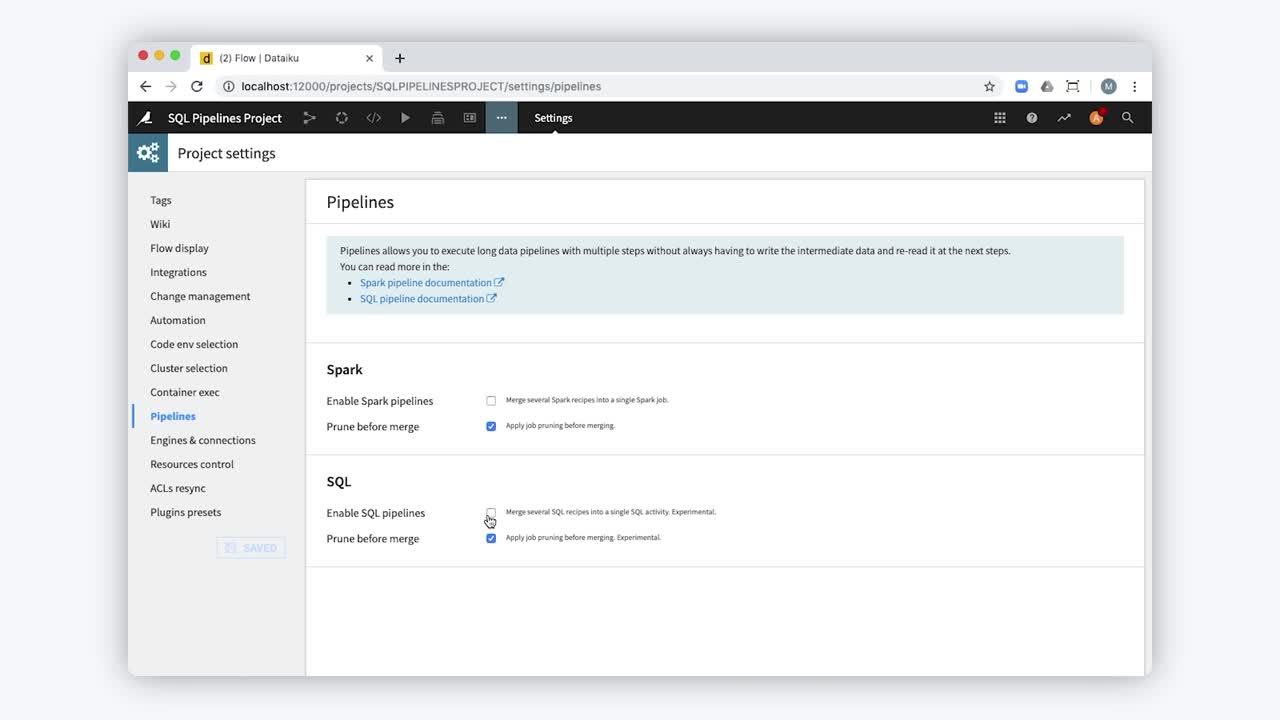
SQL pipelines combine several consecutive SQL-based recipes in a Dataiku DSS Flow. These combined recipes, which can be both visual and “SQL query” recipes, can then be run as a single job activity. Using a SQL pipeline strongly boosts performance by avoiding unnecessary writes and reads of intermediate datasets. SQL pipelines also allow you to optimize the data storage capacity without having to manually re-factor the Dataiku flow (for example, by reducing the number of datasets).
Learn more in the reference documentation
IDE Integration: VSCode
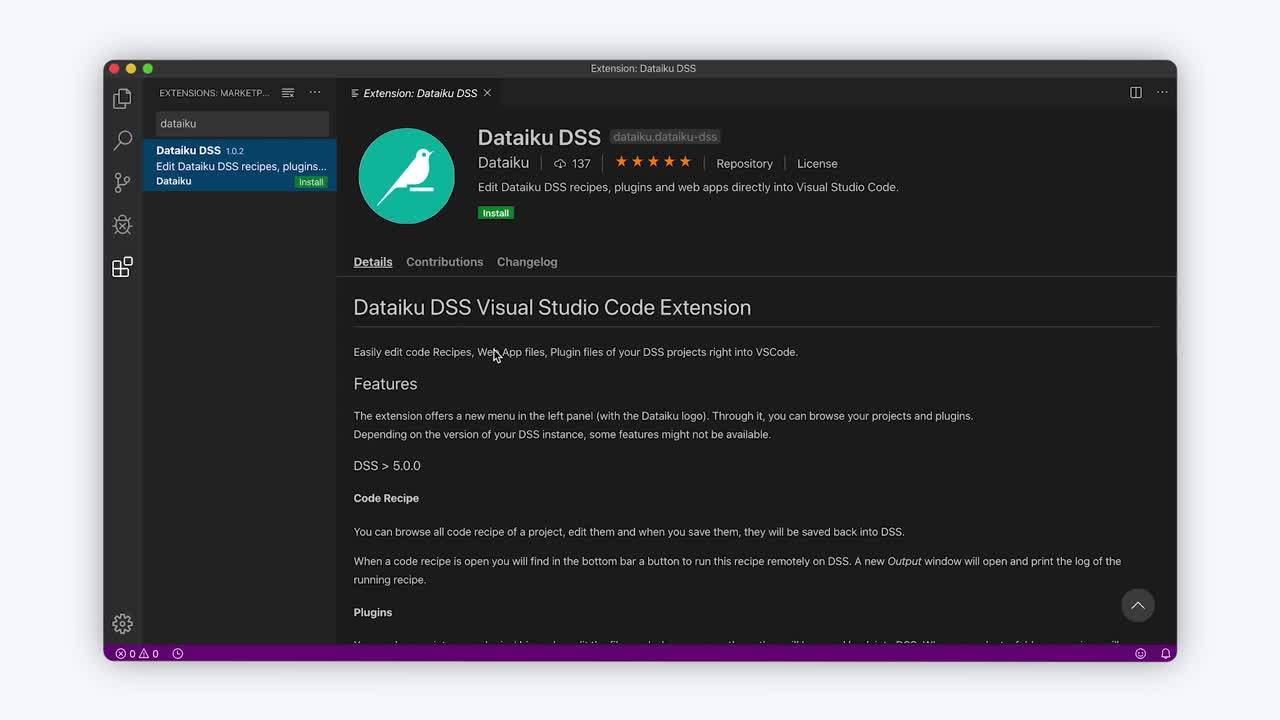
Though Jupyter notebooks are integrated into the Dataiku interface, many developers use VSCode. Dataiku offers several integration points with VSCode.
Improved Plugin Store
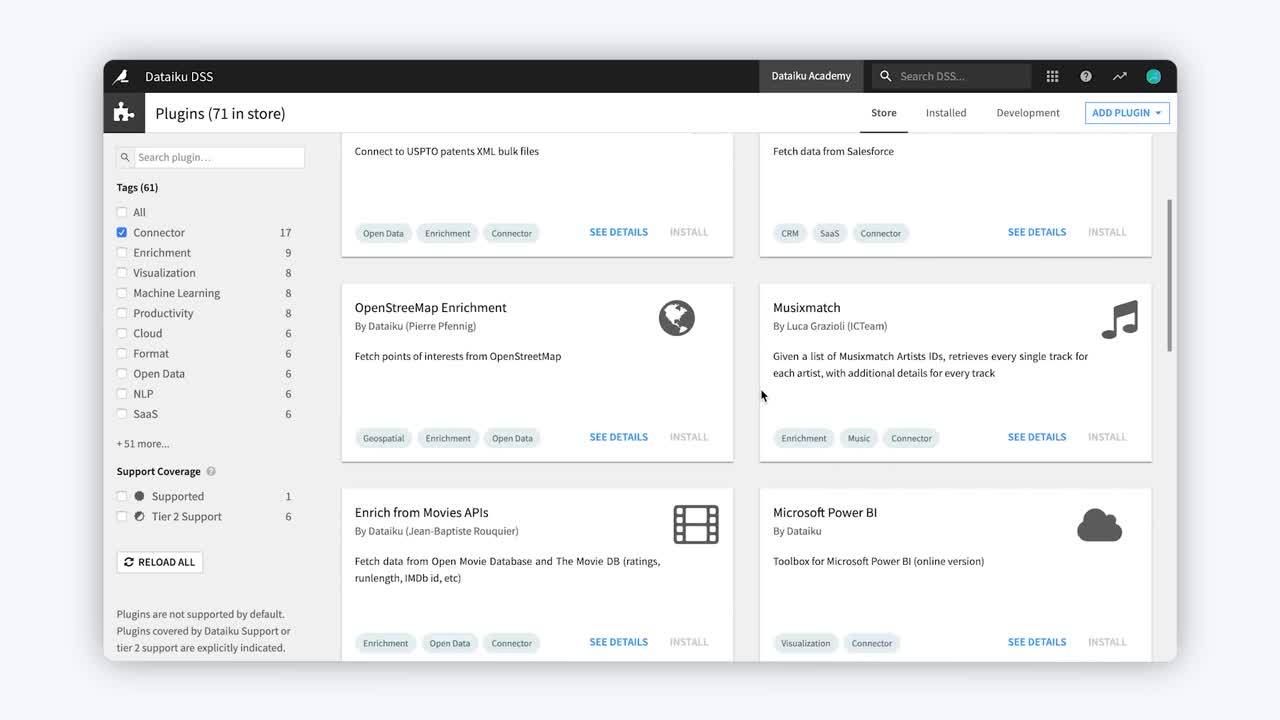
The Plugin Store is now visible to non-administrative users, which allows them to see which plugins are installed, and which are available. Learn more in the reference documentation.
Time Series Preparation Plugin
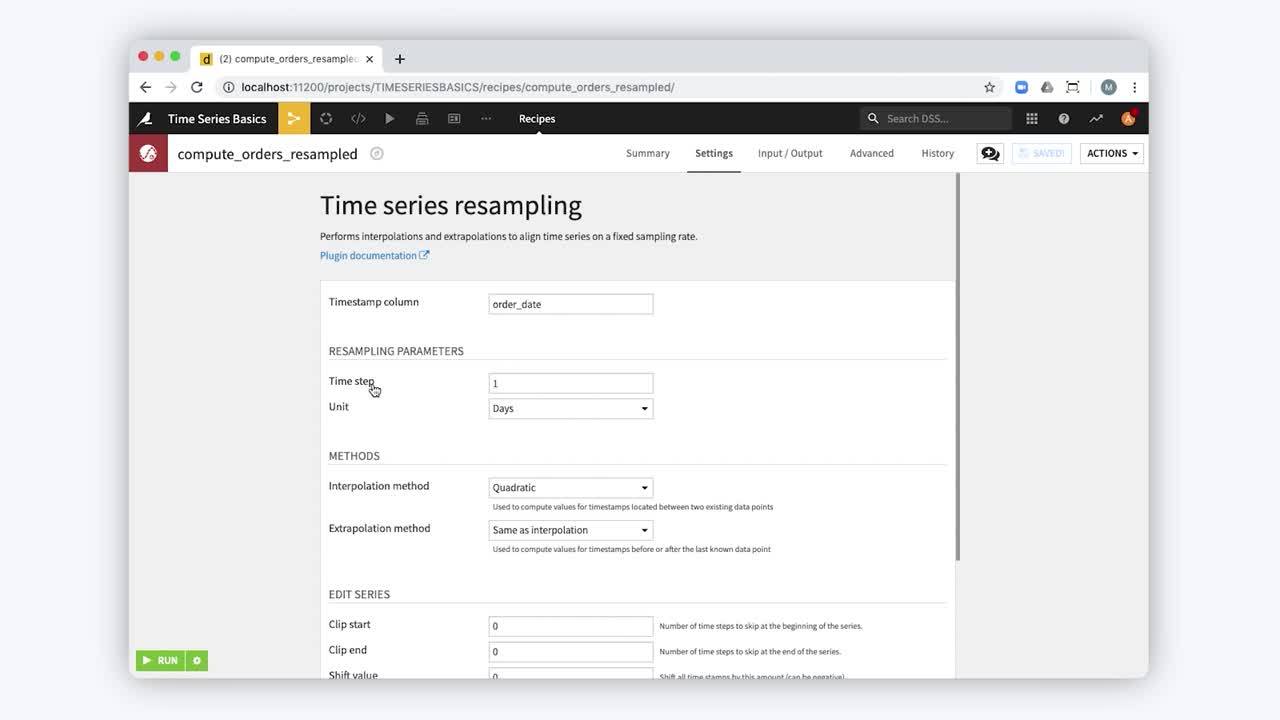
DSS 6.0 introduces the first fully-supported plugin, which provides visual recipes for preparing time series data. Learn more in our tutorial and in the reference documentation.
Stratified (Partitioned) Models
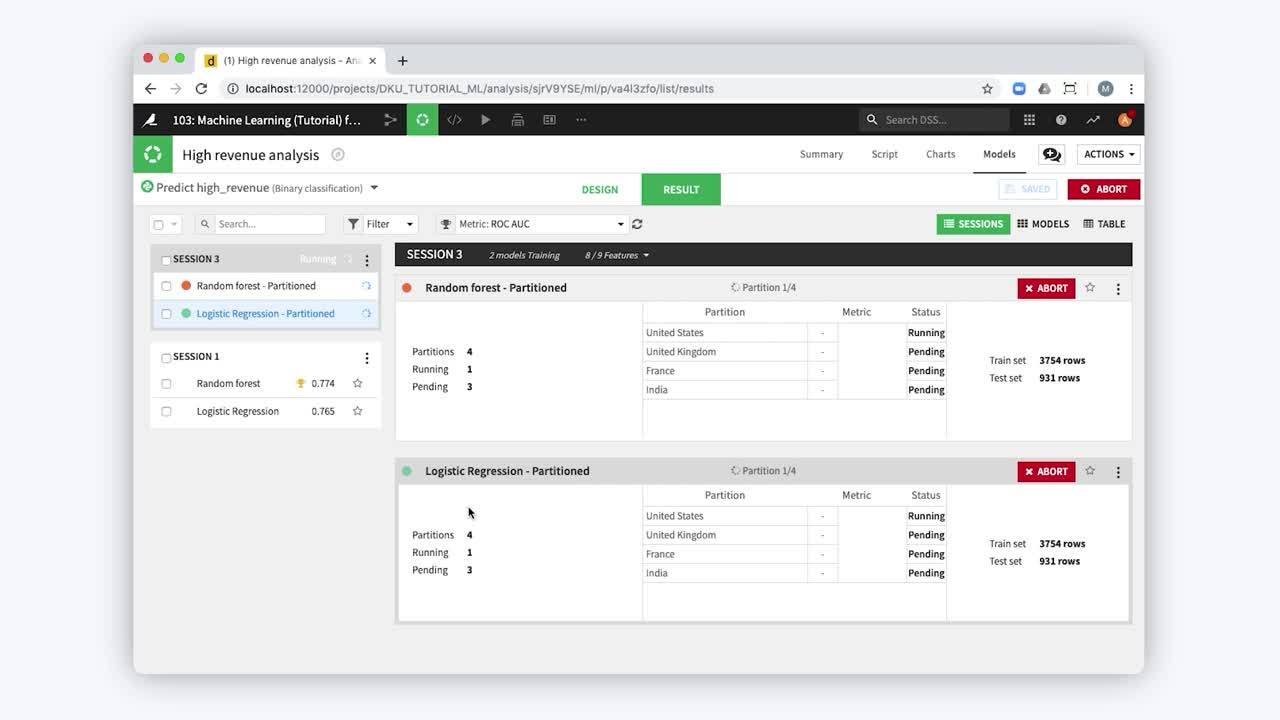
Learn more in the reference documentation.
Usability Improvements
Improved Project Folders
Learn more in the reference documentation.
Microsoft Teams Scenario Reporter
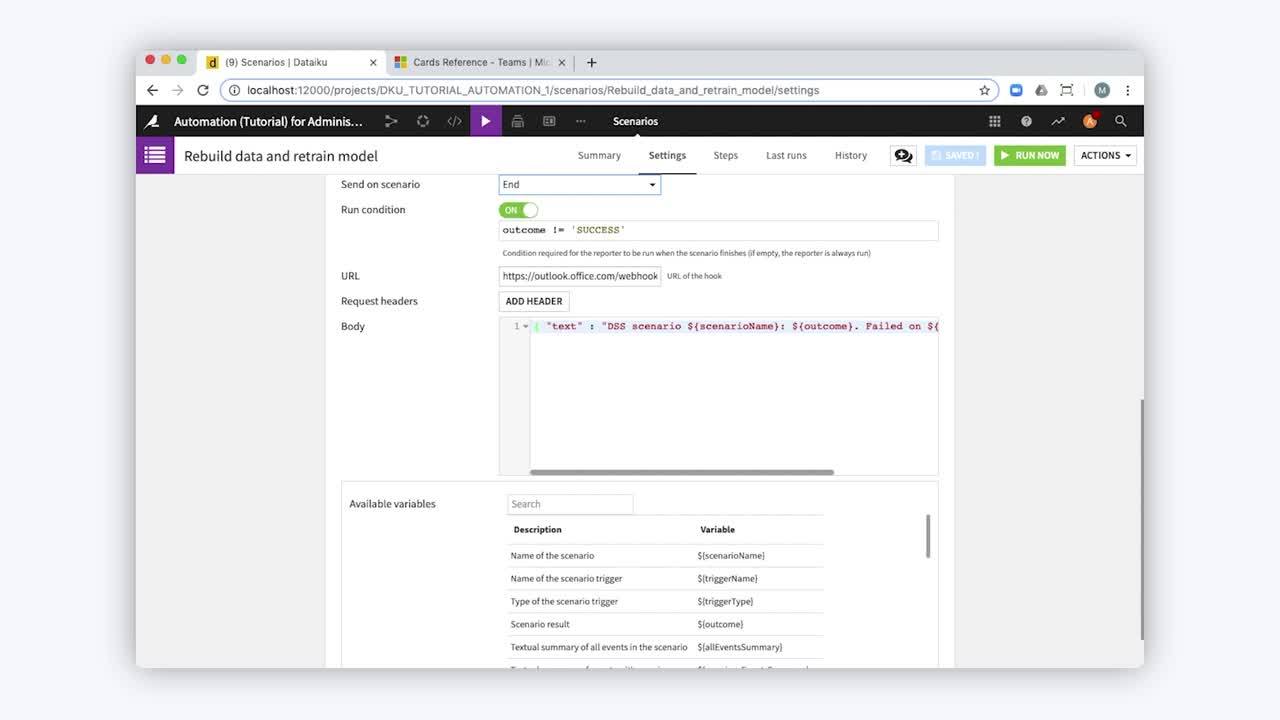
Learn more in our tutorial and in the reference documentation.
Improved Right Panel
Global Search
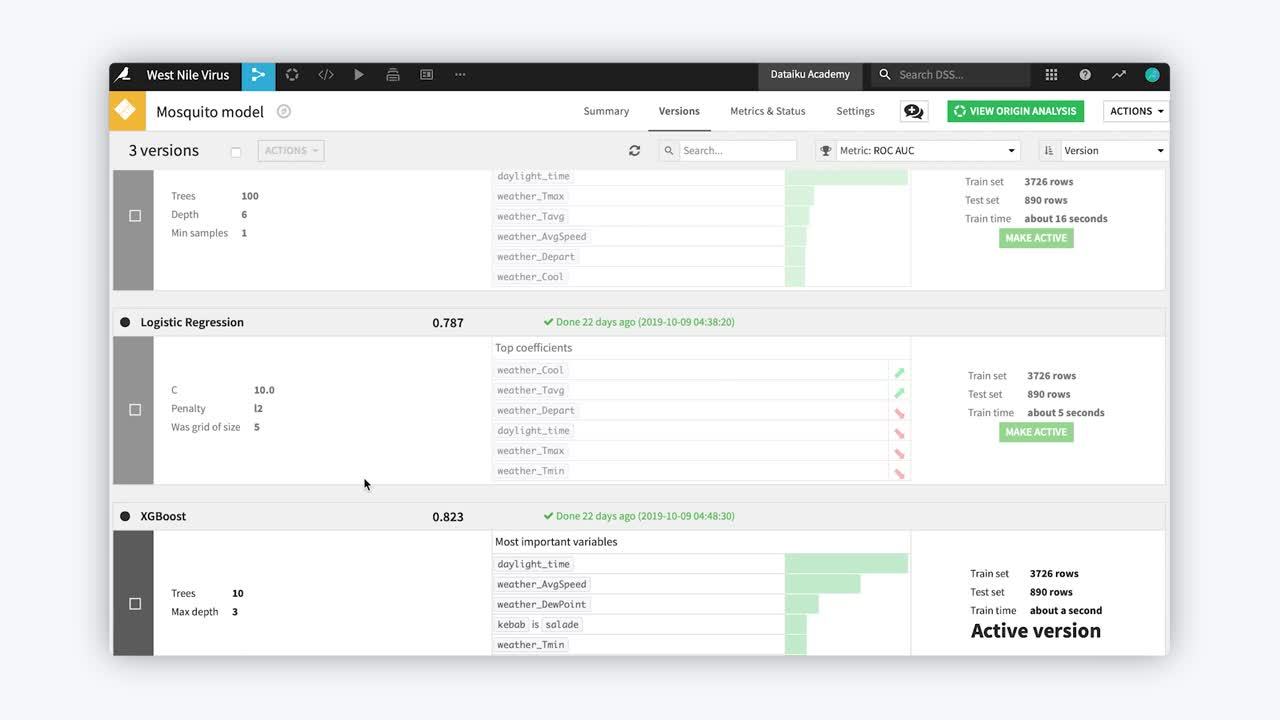
Model Drift Plugin
Subpopulation Analysis
Find all details in our release notes.