




Version 4.3 – June 2018
Deploy models in production on the cloud with Kubernetes
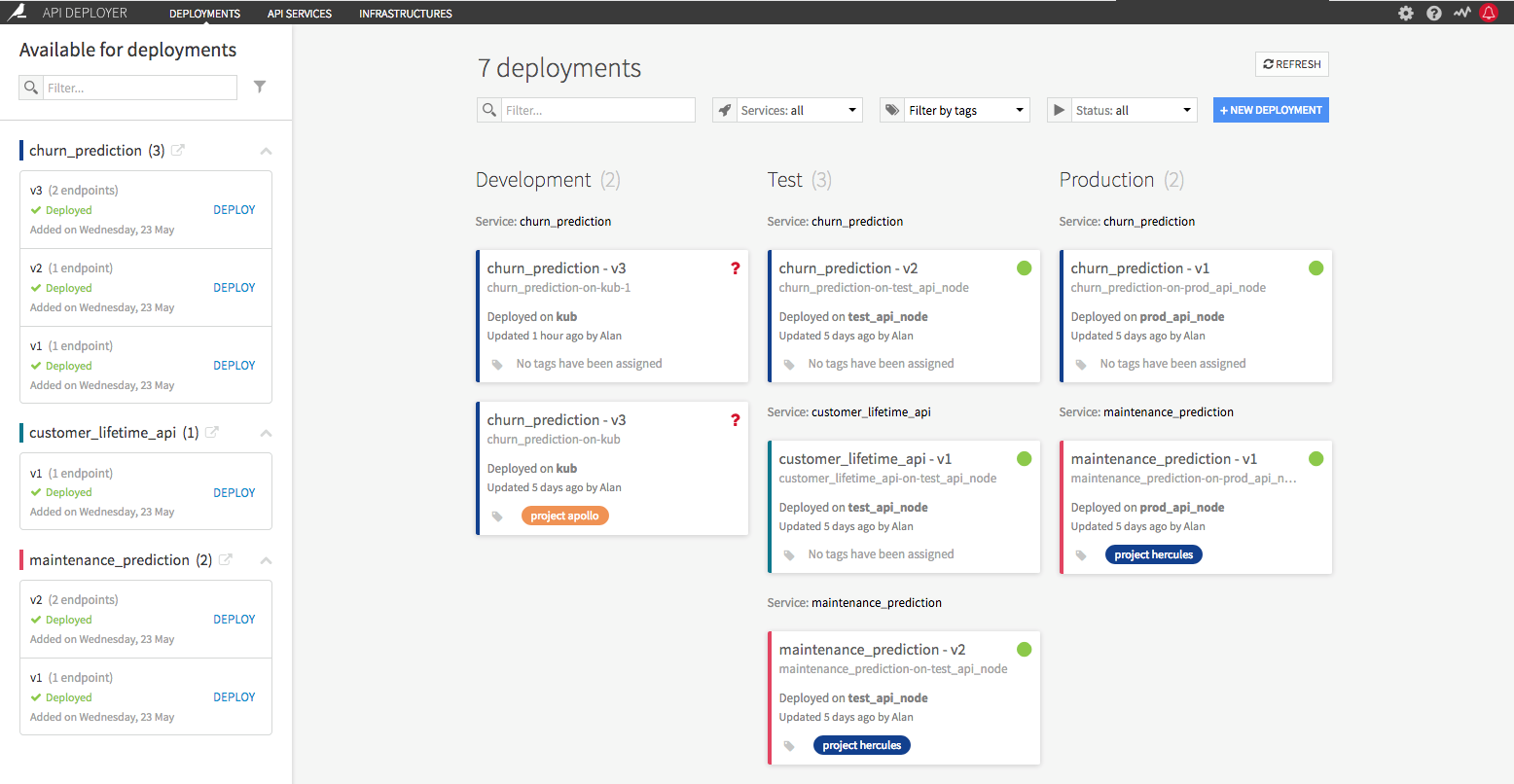
Deploy models as APIs in production in a few clicks. Deploy highly scalable modes, on-premise or on the cloud, using native Kubernetes integration.
Learn more in our blog post, our product page and in the reference documentation
Deploy dynamic and elastic EMR clusters
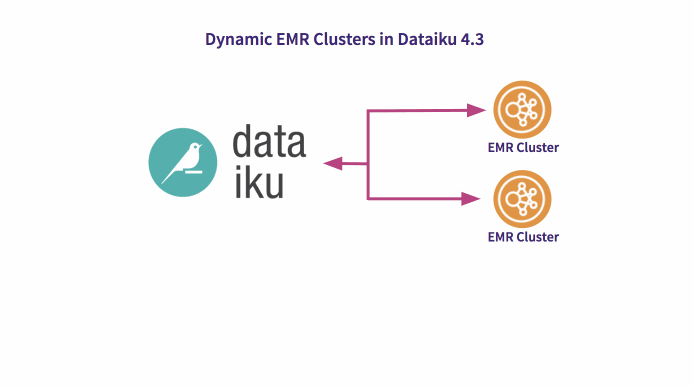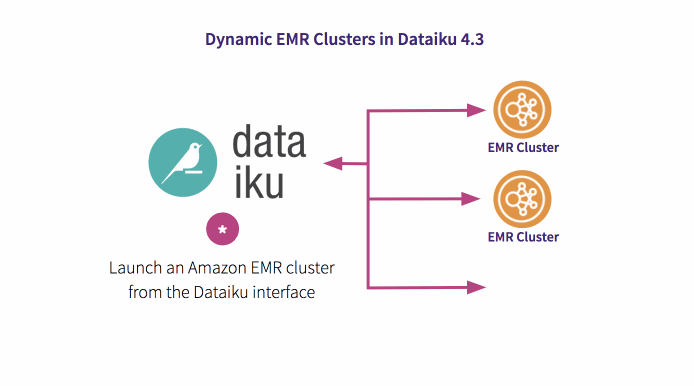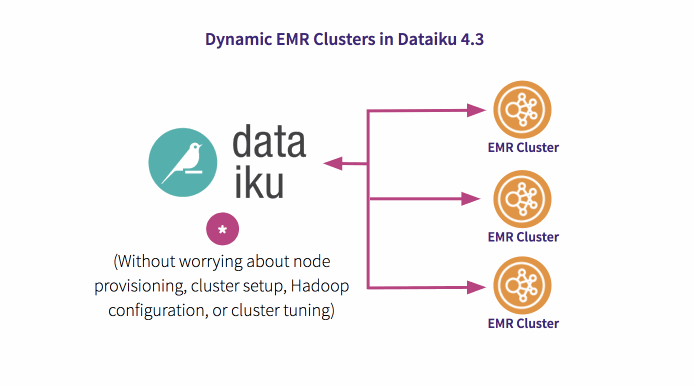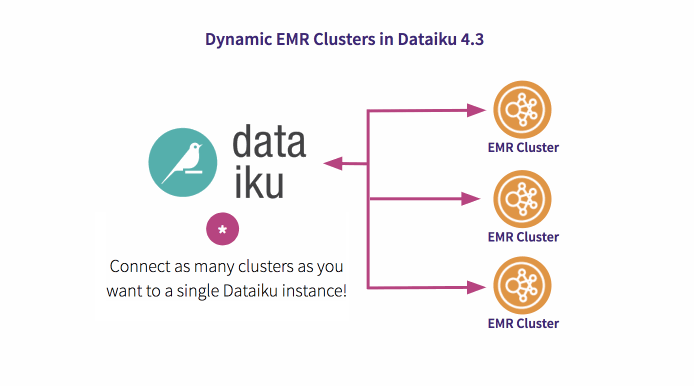
Launch an Amazon EMR cluster from the Dataiku interface in minutes. You don’t need to worry about node provisioning, cluster setup, Hadoop configuration, or cluster tuning. Dataiku together with Amazon EMR take care of these tasks so you can focus on analysis.
Request power only when you need it and stop being dependant of your IT folks. You can now provision one, hundreds, or thousands of compute instances to process data at any scale that will become immediately available for your data team.
Learn more in our blog post and in the reference documentation
And much more …
Dataiku DSS 4.3 also brings the following:
- Fast scoring and more options for XGBoost algorithm
- Reorder columns visually in the prepare recipe
- New fast sync for options AWS and Azure
- New productivity options for the Flow
- and many others!
Find all details in our release notes.
Version 4.2 – March 2018
New Homepage for Automation Monitoring and Scheduling
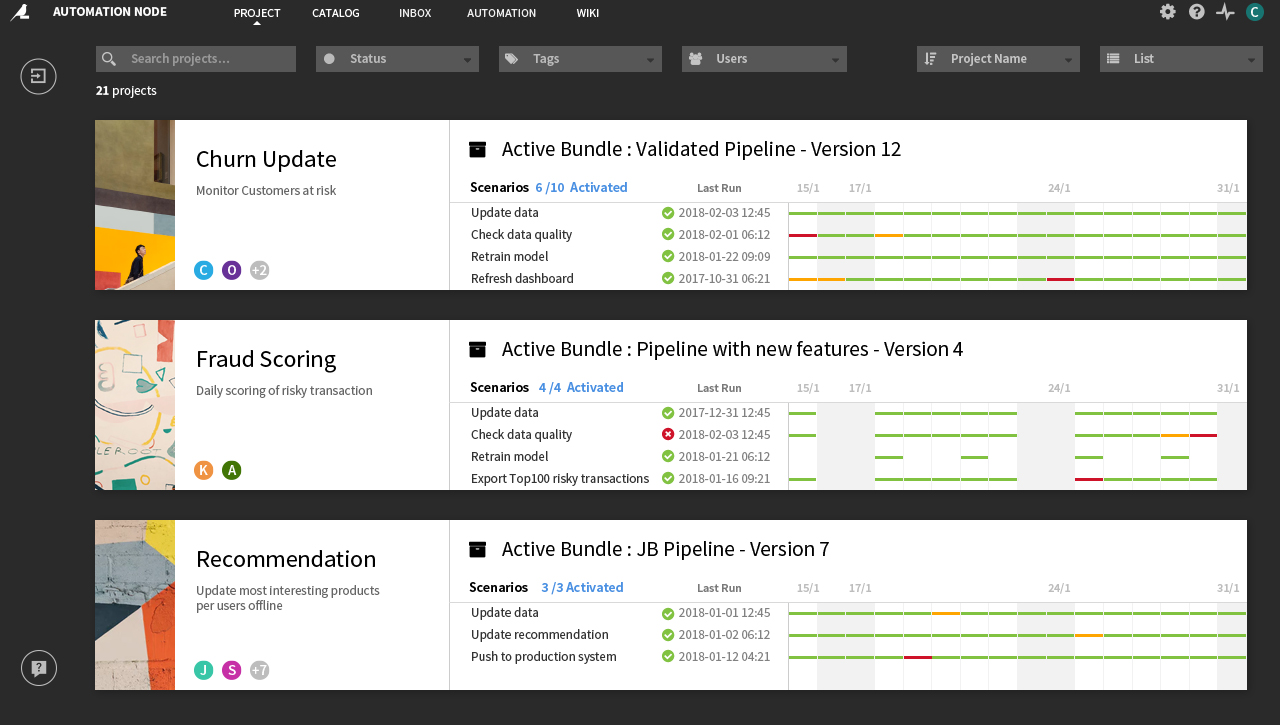
Schedule and monitor analytics pipelines and follow the evolution of models and datasets using metrics.
Sample weights for training and optimization
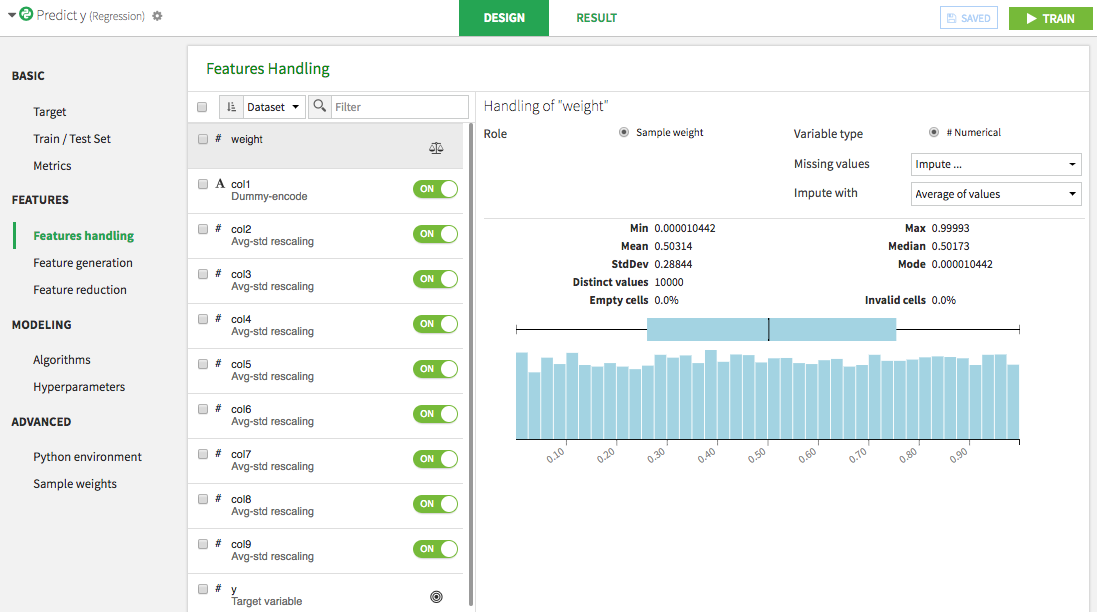
Use weights so that rows you consider more important account for more in the training and optimization of models.
And much more …
Dataiku DSS 4.2 is not a small release! Some other major new features include:
- support for writing in BigQuery, including in visual recipes
- generating of models via a public API
- SQL impersonation on Oracle and SQL Server
- download plugins from Git repositories
- and many others!
Find all details in our release notes.
Version 4.1 – November 2017
Live Model Competition
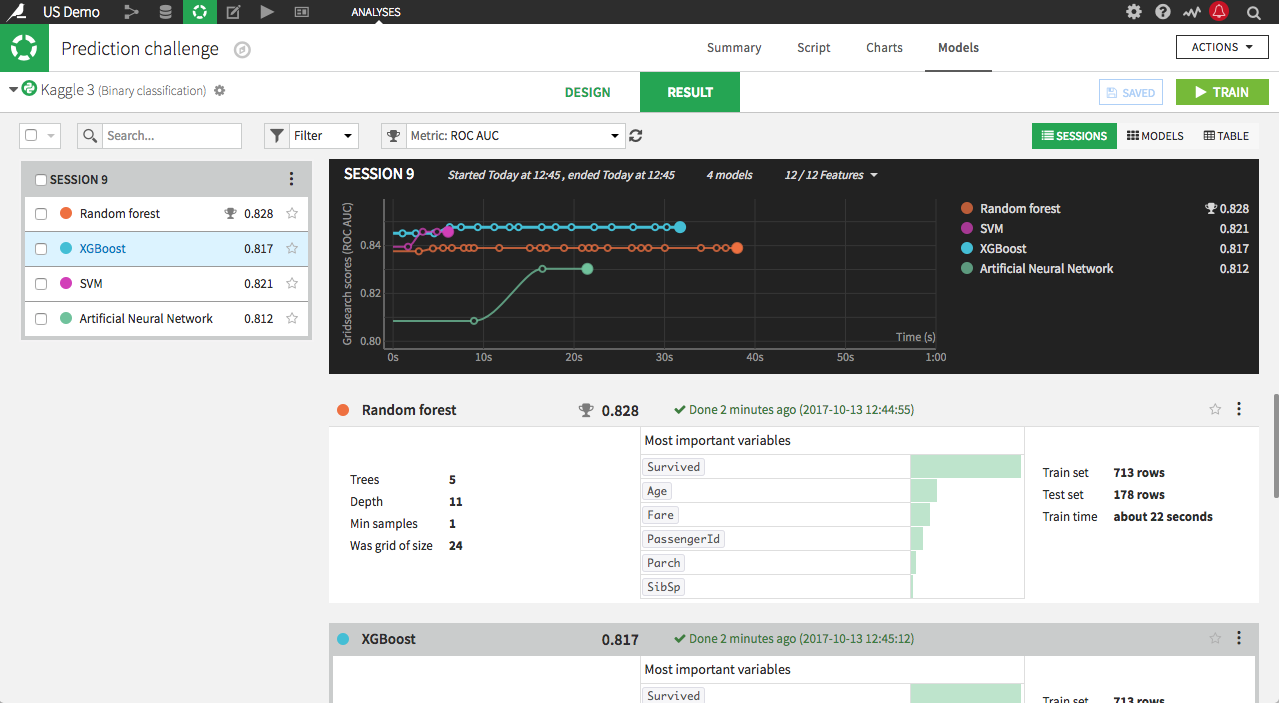
Watch in real time as different machine learning models compete,
and save time and resources by picking winners and losers before
training is complete.
New Point-and-Click Data Prep
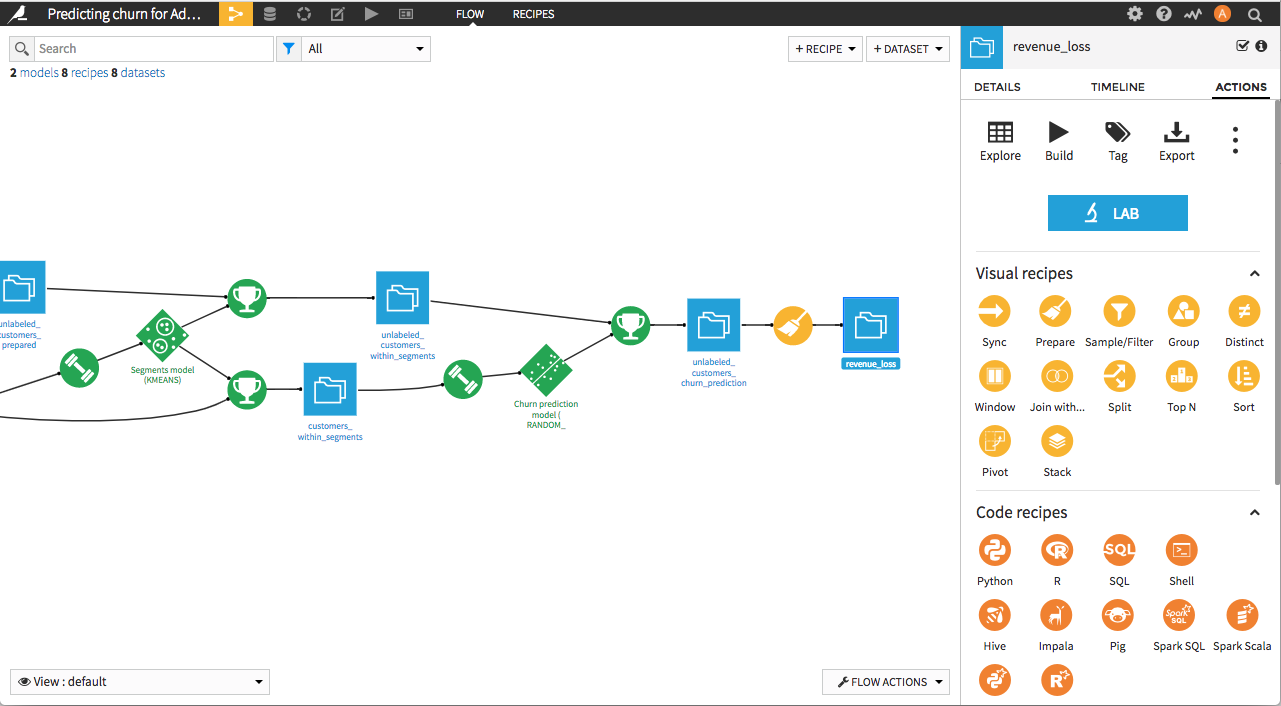
Dataiku DSS 4.1 introduces new visual recipes that bring
powerful analytical functionalities to non-coders, including
pivoting, sorting, and splitting datasets.
Reproducible Environments
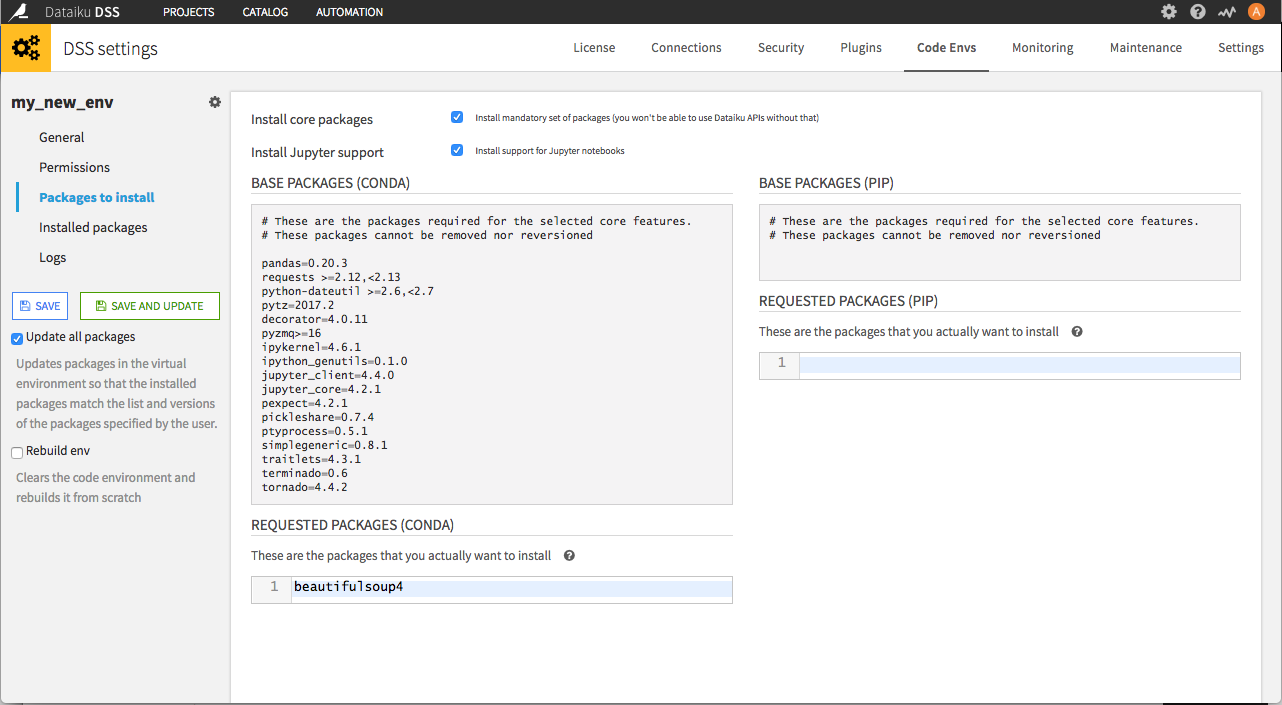
Dataiku DSS 4.1 now supports virtual code environments. Take a
snapshot of the packages used for each project so you don’t have
to worry about upgrades impacting existing or deployed projects.
Expanded End-to-End Capabilities
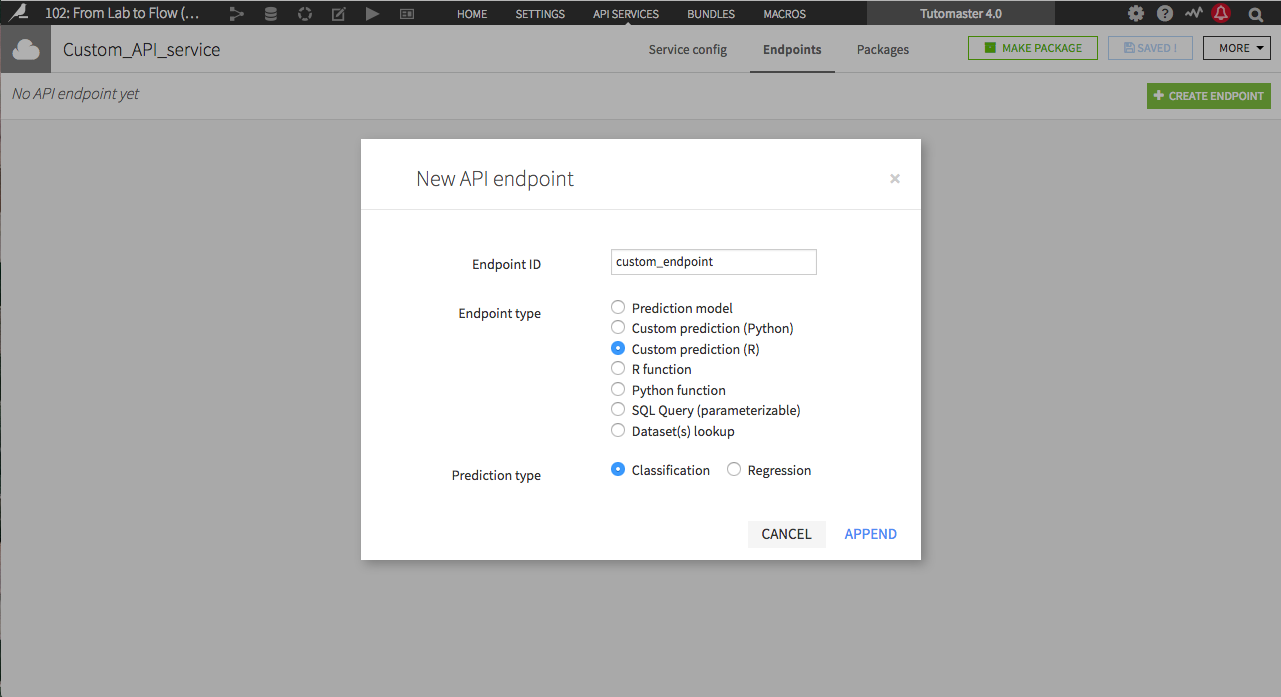
Dataiku DSS 4.1 significantly strengthens the API node. In addition to
scoring Dataiku-created, Python and R models, it can also run
any function coded in these languages. It also allows for
parameterized SQL queries and database lookups.
New Capabilities for Coders
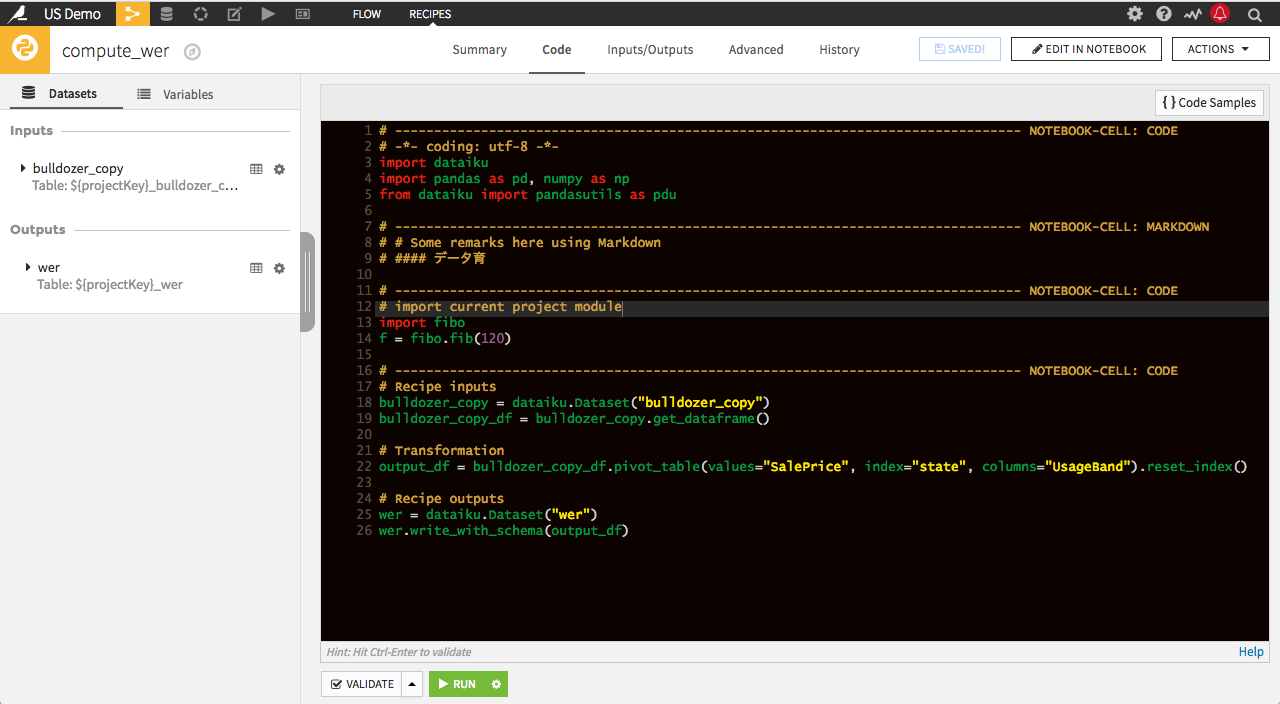
The latest release brings advanced visualization
libraries like RShiny and Bokeh for rapidly creating engaging
interactive web applications within dashboards. Additionally,
RMarkdown reports let users easily share their results outside
of Dataiku. Other features include the support of Python 3, as
well as a brand new code editor.
More Powerful Charts
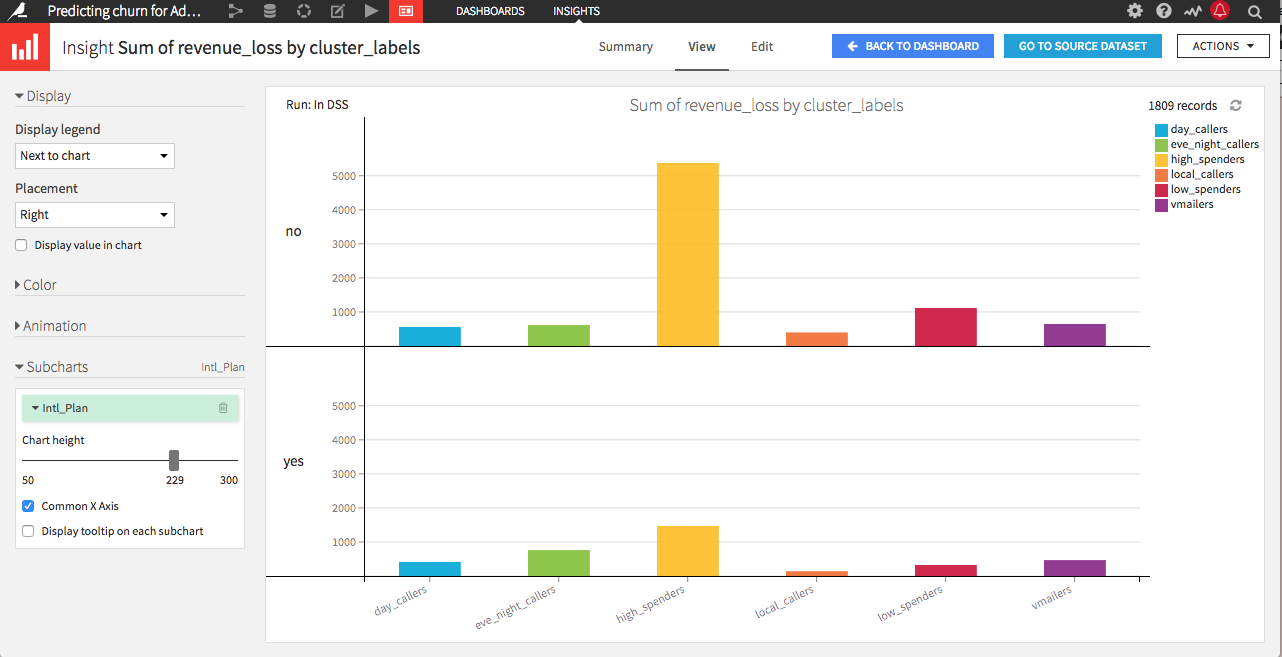
Dataiku DSS 4.1 introduces additional dimensions in its chart engine.
You can now use another property to split your chart into multiple
subcharts, or even create an animated version of the chart!
And much more …
Dataiku DSS 4.1 is one of our largest releases ever. Some other major new features include:
- a “magical flow” with UX improvements in our visual representation of project workflows
- an expanded toolkit for creating plug-ins within Dataiku DSS
- a wide assortment of color palettes for data visualization
- a new type of chart to display geometries
- the creation of an ensemble model using multiple trained models
- the capability to gridsearch MLLib models
- indexation of external databases into a central catalog
- plugin edition for all users
- and many others!
Find all details in our release notes.
Version 4.0 – February 2017
Interactive dashboards
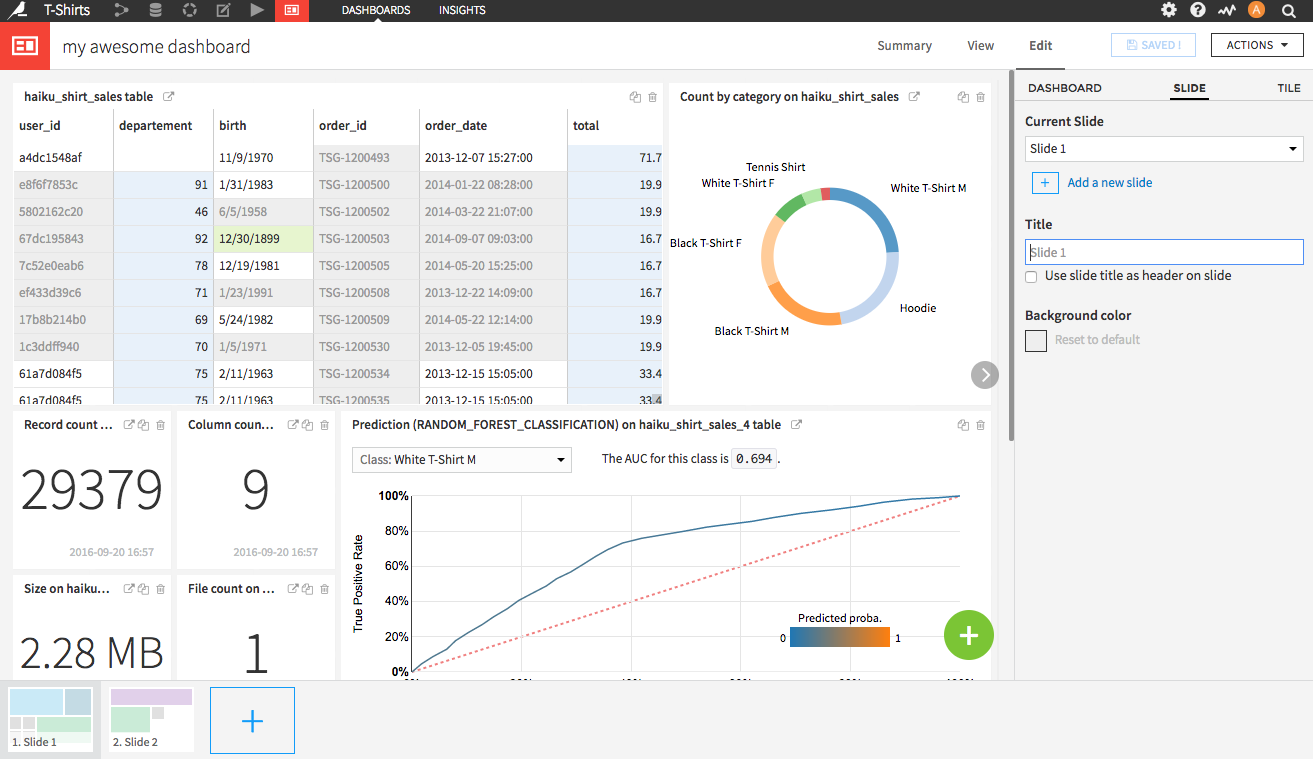
Dataiku DSS 4.0 features new, user-built, interactive dashboards, which allow users to create and customize dashboards with charts, metrics, text and images — and also with models and scenarios, so that dashboard users can dive deeper into the analysis than ever before.
Dataiku users can also now create multiple dashboards per project.
Spark pipelines
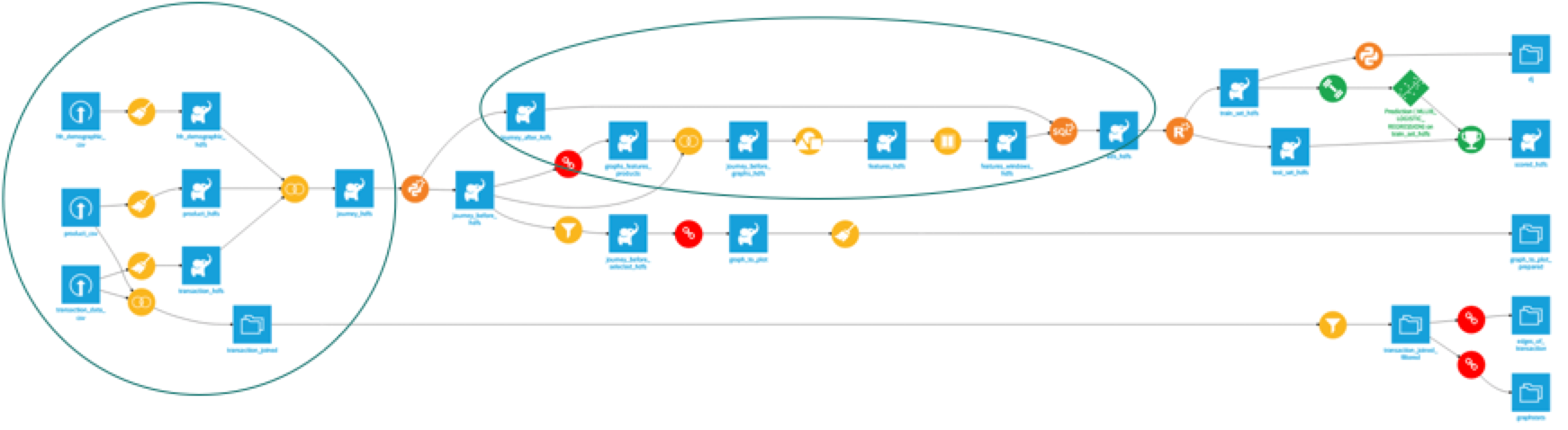
With Dataiku 4.0, run consecutive Spark recipes in a single Spark job and avoid writing intermediate datasets, thus dramatically improving run-time performance.
In a regular data pipeline, we would have to load the full dataset at the beginning of each new calculation, but in Dataiku 4.0, we are able to run all the calculations in-memory, meaning we skip a whole lot of re-loading data.
Dataiku 4.0 also features support for Spark 2.
Interactive hierarchical clustering
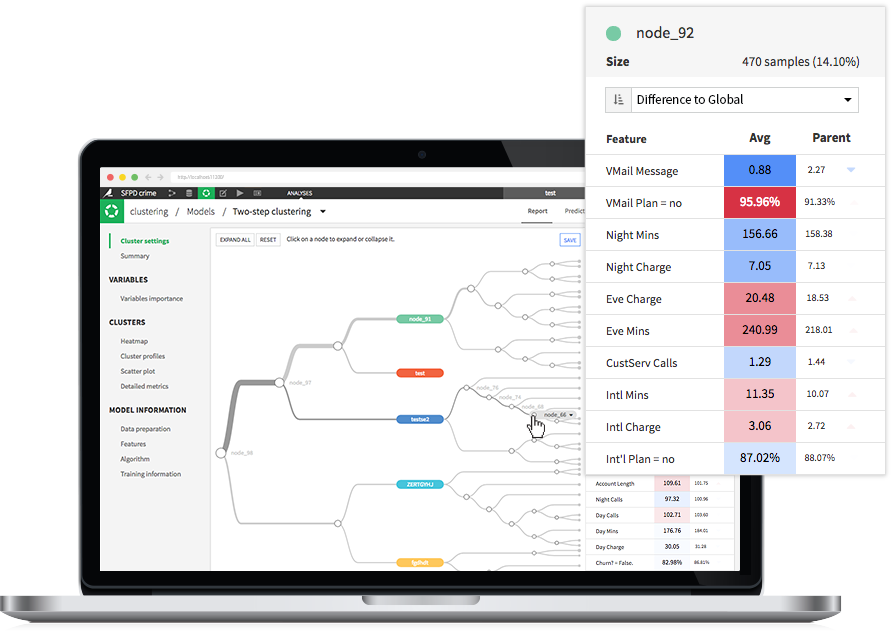
With Dataiku 4.0, you can say goodbye to the often long and labor-intensive process involved in cluster analysis. With a new “hierarchical clustering” feature, you can interactively define your clusters by digging deeper into some clusters than others.
And much more …
Dataiku 4.0 is by far the largest Dataiku DSS release ever. Among the other major new features:
- Hadoop multi-user setup for secure collaboration
- Quick machine learning models according to user-specified requirements
- Controllable notifications, including integration with Slack, Hipchat, and Github
- New sampling methods (exact random, stratified, class rebalancing, last records)
- The ability to sort and analyze the entire data set while exploring data
- and many others!
Find all details in our release notes.