




Version 3.1 – July 2016
Scala
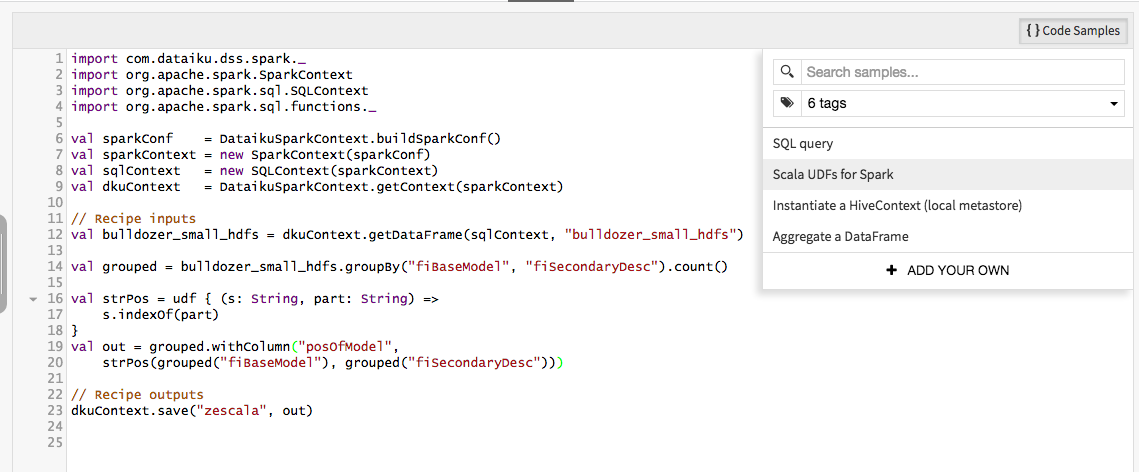
DSS goes Spark-native with the addition of Scala! Scala is the most native language for
the Spark ecosystem. It is the only language in which Spark users can write very fast User-Defined functions to work on Dataframes.
DSS 3.1 includes a Spark-Scala recipe and an interactive notebook. The recipe features automatic code validation.
Version 3.1
H2O (Sparkling Water) integration
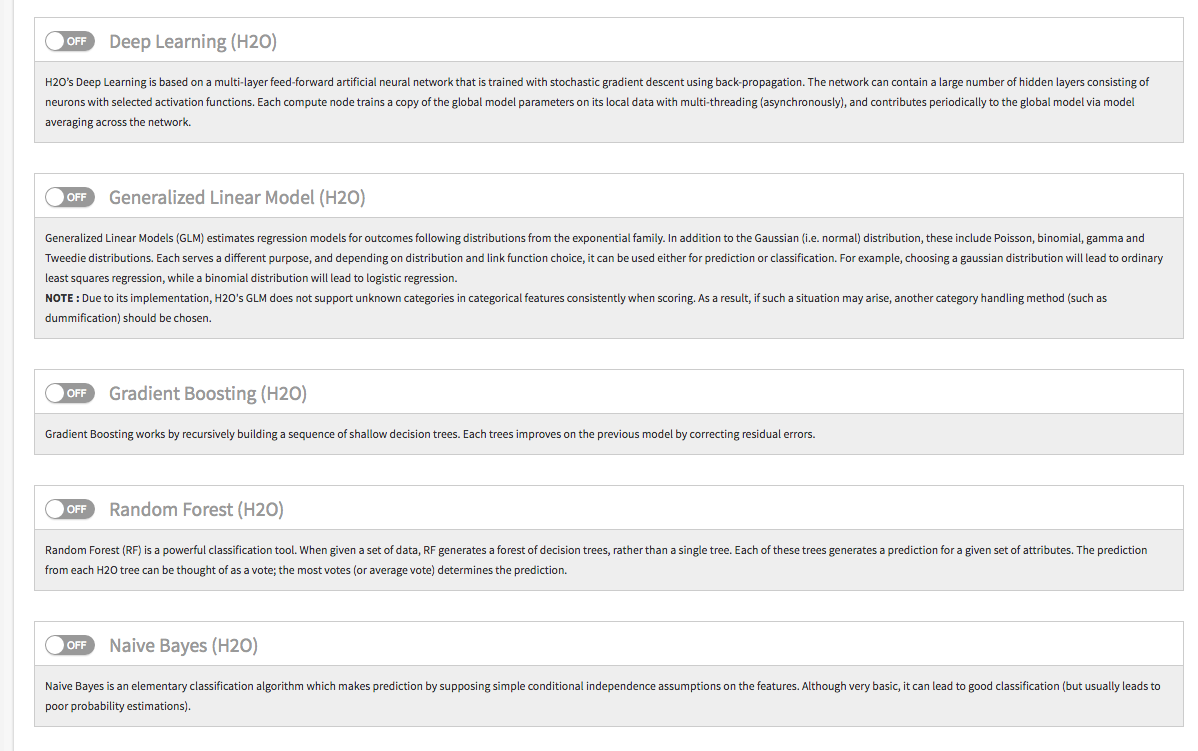
H2O is a distributed machine-learning library, with a wie range of algorithms and methods.
DSS now includes full support for H2O (in its “Sparkling Water” variant) in its visual machine learning interface.
You can now create H2O models with absolutely no code required:
- Deep Learning models
- Generalized Linear Models
- Gradient boosting
- Random forests
- Naive Bayes models
DSS 3.1 also includes support for in-database machine learning on Vertica, using Vertica’s Advanced Analytics package
Navigator
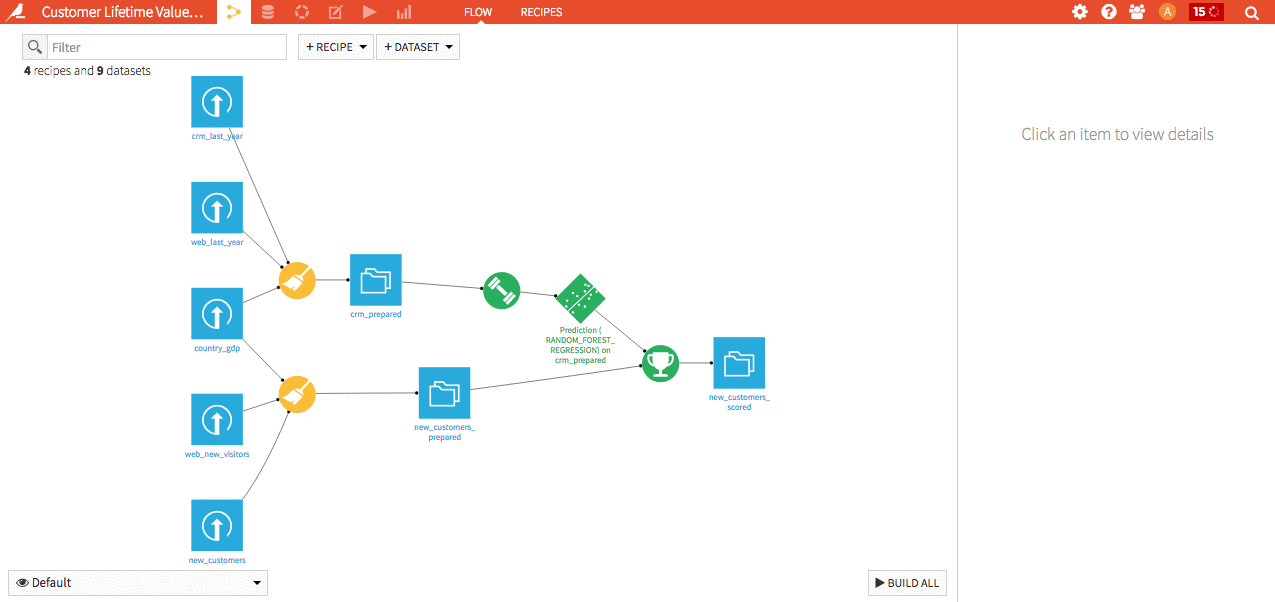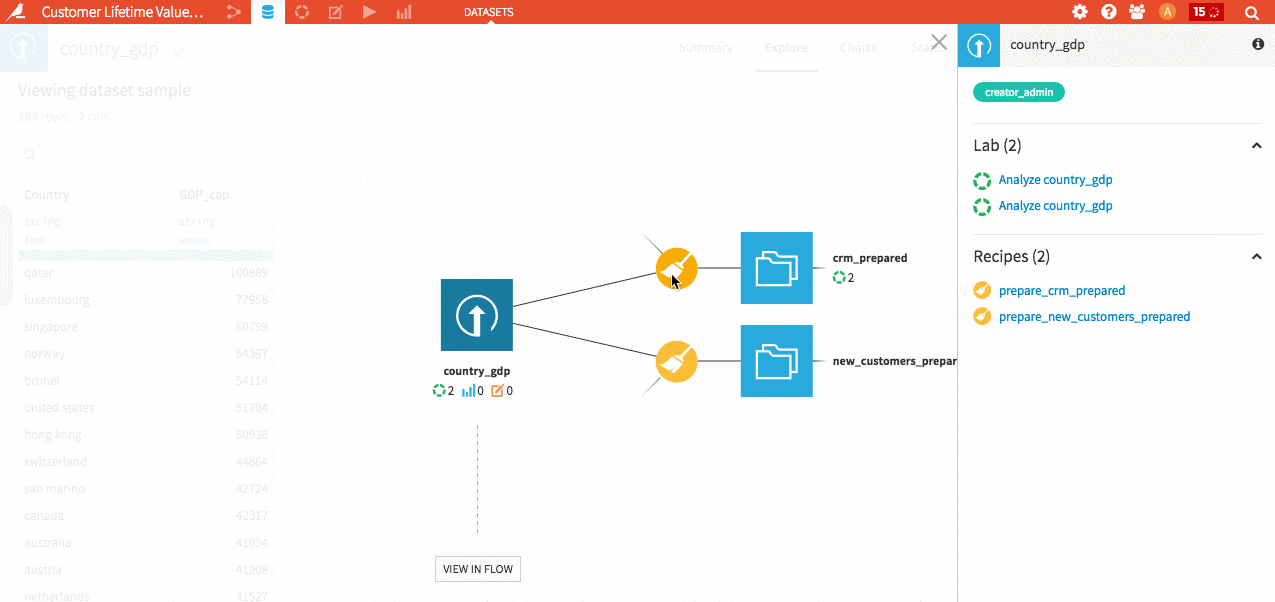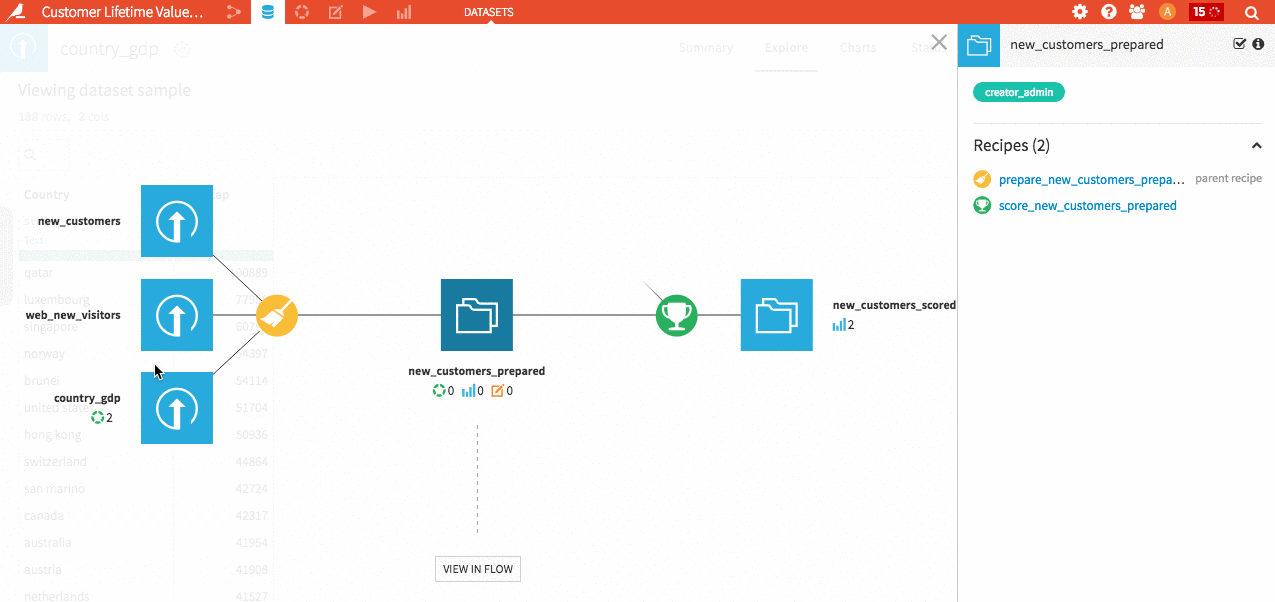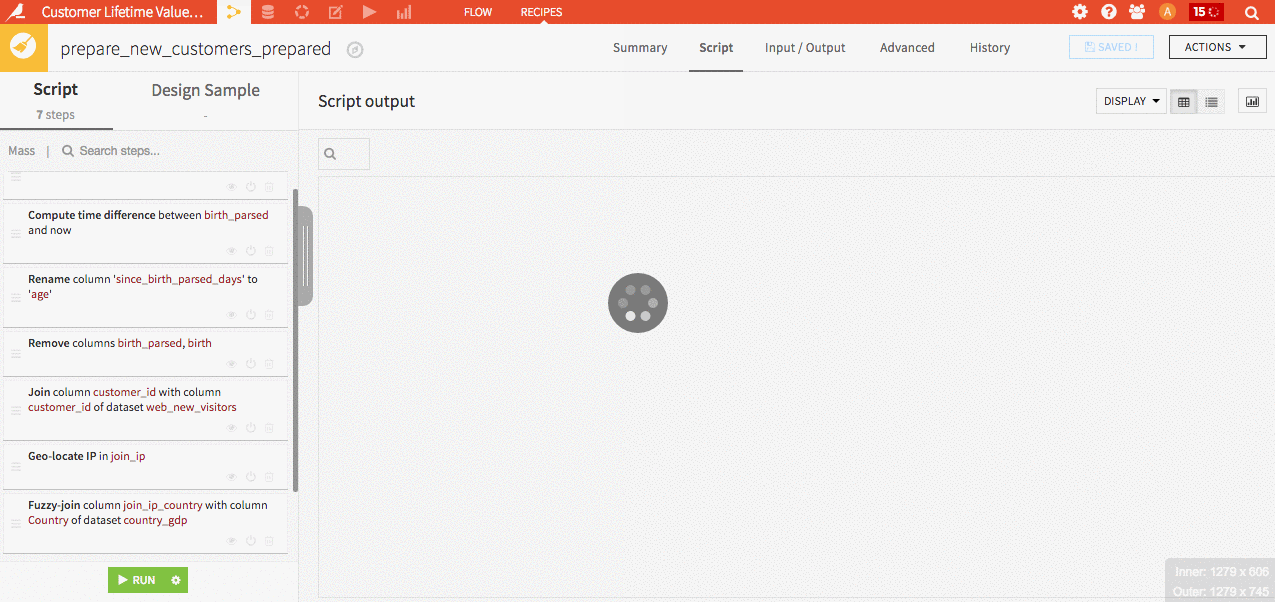
Boost your productivity! You can now very quickly navigate from a DSS object to another (from recipe to dataset to another recipe to model to analysis …).
Hit Shift+A on any screen to enter the navigator.
New machine learning visualizations
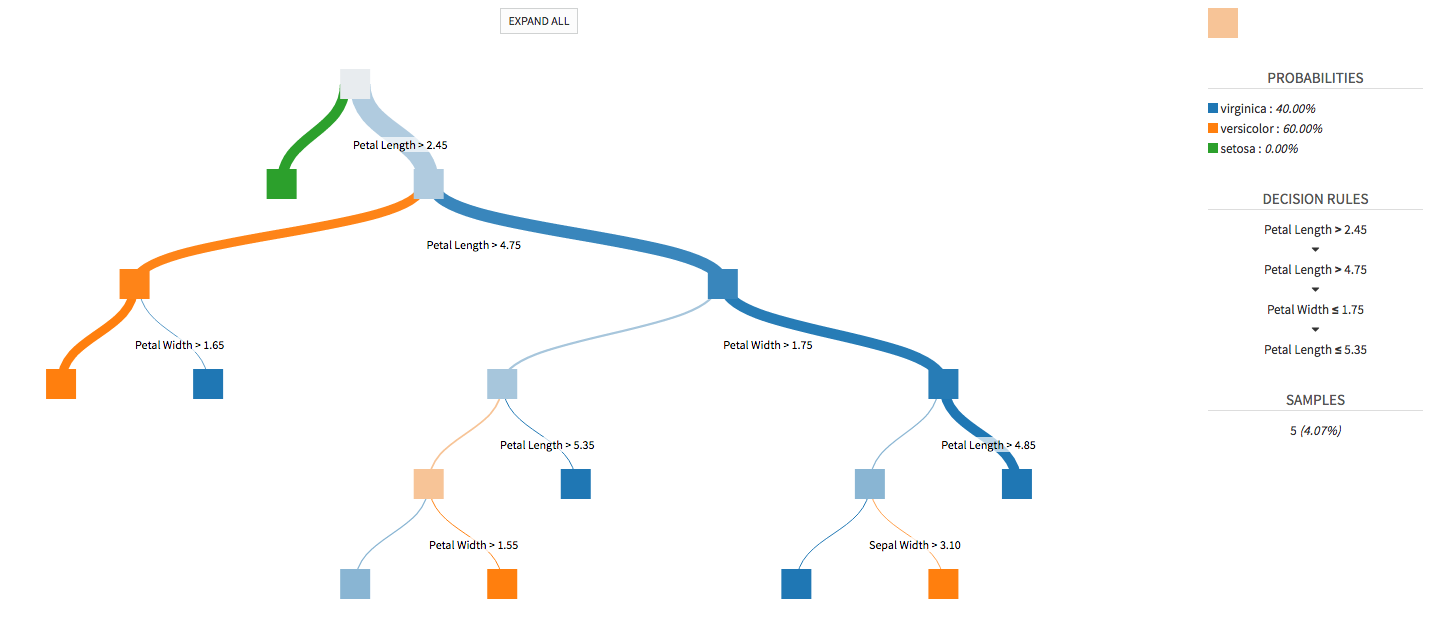
Getter better insights into your models. DSS 3.1 now includes visualization of trees for decision tree, random forest and gradient boosting algorithms.
It also includes visualization of partial dependency plots for gradient boosting algorithms.
And much more …
DSS 3.1 is a tremendous release for DSS. Among the major other new features:
- an improved DSS home page with the ability to define custom project status and workflow
- prebuilt notebook templates with support for PCA, correlations analysis, time series analytics
- support for Netezza, SAP HANA and Google BigQuery
- more support for custom algorithms in machine learning
- better preprocessing options in machine learning
- the ability to read unlimited Excel files
- and many others!
Find all details in our release notes.
V 3.0 – May 2016
Metrics & Checks
You can now track various advanced metrics about datasets, recipes, models and managed folders (size of a dataset, average of a column in a dataset, model performance metrics, …). You can also define custom metrics using Python or SQL.Metrics are historized for deep insights into the evolution of your data flow and can be fully accessed through the DSS APIs.
Then, you can define automatic data checks based on these metrics, that act as automatic sanity tests of your data pipeline. For example, automatically fail a job if the average value of a column has drifted by more than 10% since the previous week.
Version control & activity
- View the history of your project, recipes, scenarios, … from the UI
- Write your own commit messages
- Auto or explicit commit modes
Plus, we’ve added a lot of team activity dashboards to follow what’s going on in your data projects.
And much more …
DSS 3.0 is one of our biggest releases ever. We did not even mention the new public APIs, administrator monitoring dashboards, the new security options, improvements to project export, …
Find all details in our release notes.