




Version 2.3 – February 2016
Visual preparation, reloaded
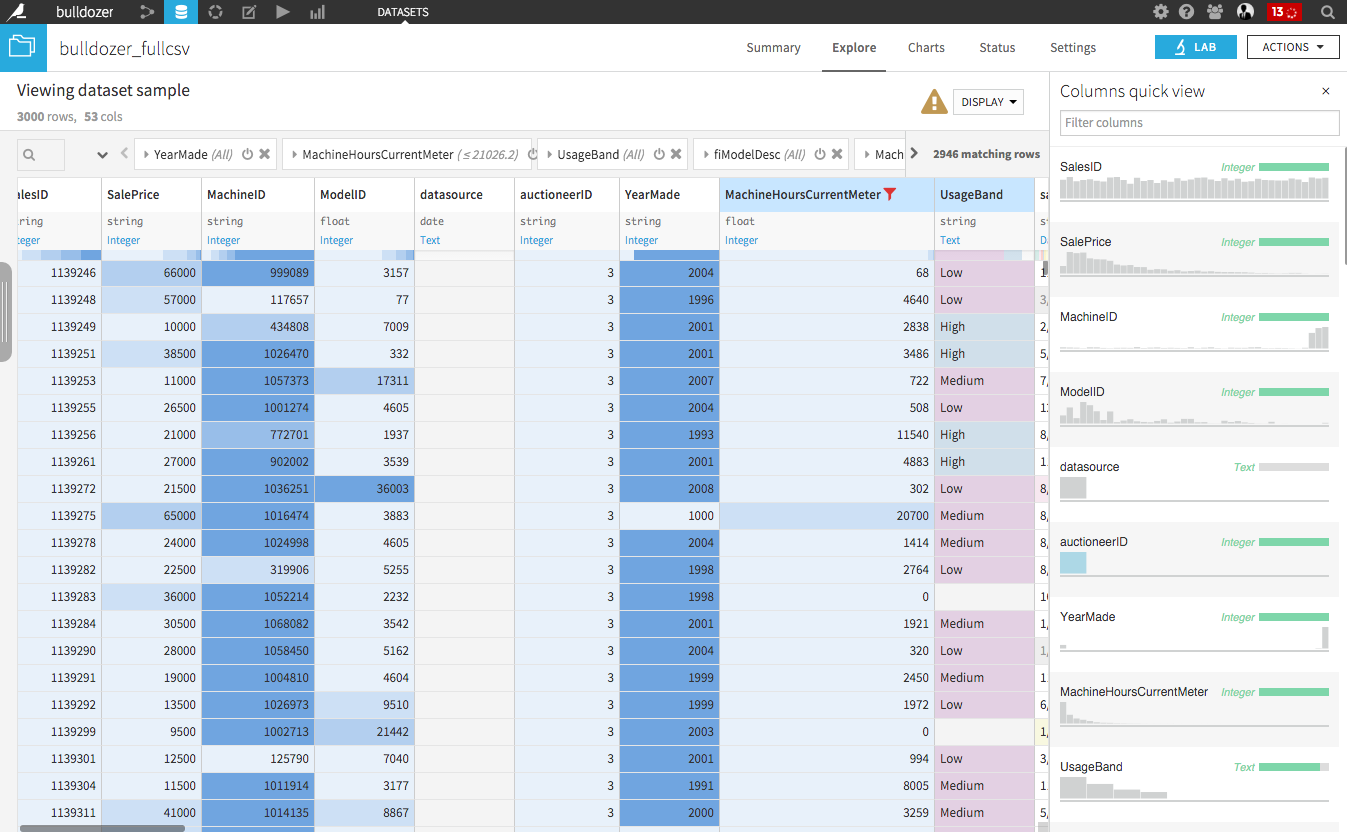
The visual interactive data preparation DSS has received a huge overhaul. It is now even easier and more productive to clean and enrich your datasets.
- Color the cells of the data table: locate co-occurences easily
- Group, color and comment steps
- New Quick Columns View for immediate overview of all your data
- Much improved Formula and Python processors, for more advanced transformations
- Users can now define their own meanings
- And much more, see our release notes.
Flow Views
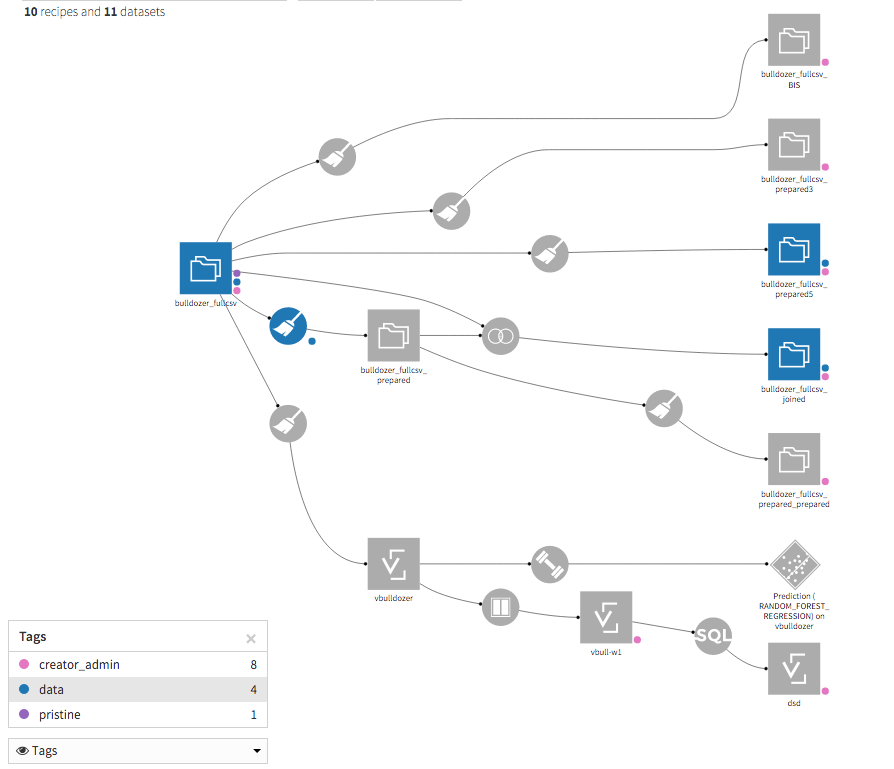
The Flow views system is an advanced productivity tool, especially designed for large projects. It provides additional “layers” onto the Flow
- Color by tag and propagate tags
- Recursively check and propagate schema changes accorss a Flow
- Check the consistency of datasets and recipes accorss a project
Data Catalog
Since the very first versions, DSS let you search within your project.
Thanks to the new Data Catalog, you now have an extremely powerful instance-wide search. Even if you have dozens of projects, you’ll be able to find easily all DSS objects, with deep search (search a dataset by column name, a recipe by comments in the code, …).
New SQL / Hive / Impala notebook
The SQL / Hive / Impala notebook now features a “multi-cells” mechanism that lets you work on several queries at once, without having to juggle several notebooks or search endlessly in the history.
You can also now add comments and descriptions, to transform your SQL notebooks into real data stories.
Version 2.2 – November 2015
Prediction API server
DSS now features a real-time API server for predictions.
Using the REST API of the DSS API node, you can request predictions for new previously-unseen records in real time.
The DSS API node provides high availability and scalability for scoring of records.
Thanks to its advanced features, the DSS API node is at the heart of the feedback and improvement loop of your predictive models
Window analytics recipe
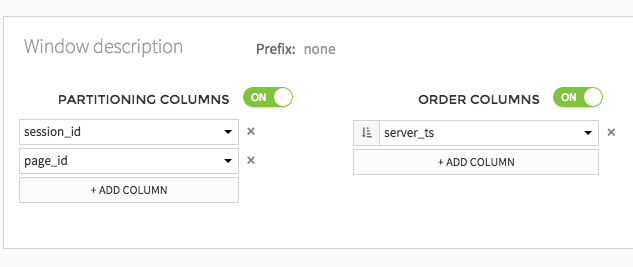
Window functions are one of the most powerful features of SQL (and SQL-like: Hive, Impala, Spark, …) databases. They are also one of the least known and most tricky to use when using the SQL language.
The Window visual recipe in DSS makes it extremely easy to leverage these features. Thanks to this, you’ll be able to do things like:
- Filter rows by order of appearance within a group
- Compute moving averages, cumulative sums, …
- Compute the number of events occured in the 7 days prior to another event
This recipe makes it easy to create your window functions without writing code, and also brings
advanced productivity for advanced users (mass actions, multiple windows, pre and post filters, …)
And much more in DSS 2.2 !
In addition to these major features, DSS 2.2 improves virtually every module of DSS:
- The plugins system has been vastly enhanced
- A new system for long-running tasks, improving reliability
- Better support for dates without timezones
- New APIs let you automate even more parts of DSS
Read our Release notes for more information.
V2.1 – September 2015
Spark (SparkSQL, MLLib, PySpark and SparkR)
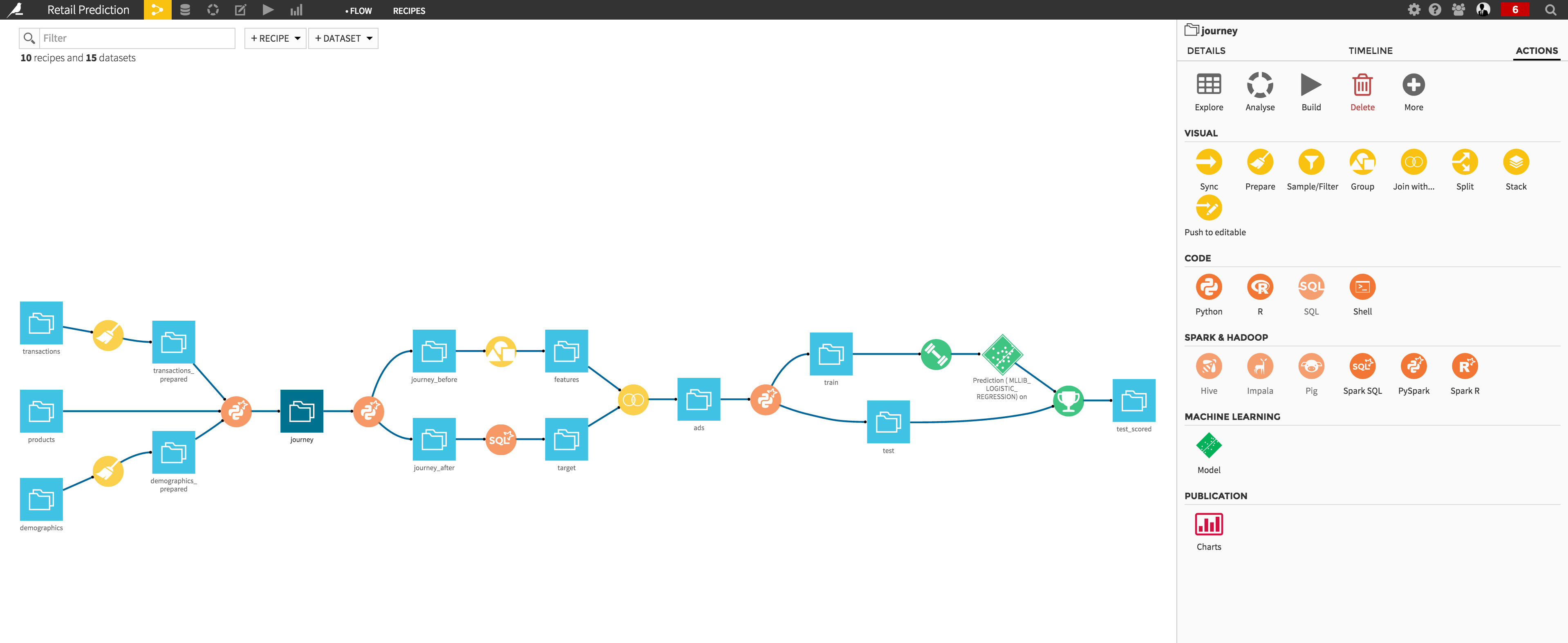
DSS now includes full integration with Apache Spark, the next-generation distributed analytic framework. Spark brings blazingly fast in-memory processing to all kind of data.
The integration of Spark in DSS 2.1 is pervasive and extends to all of the following features, which are now Spark-enabled:
- Visual data preparation
- “VisualSQL” recipes (Grouping, Joining, Stacking)
- Guided machine learning in analysis
- Training and prediction in Flow
- PySpark recipe
- SparkR recipe
- SparkSQL recipe
- PySpark-enabled notebook
- SparkR-enabled notebook
All DSS data sources can be handled using Spark. As always in DSS, you can mix technologies freely, both Spark-enabled and traditional
Plugins
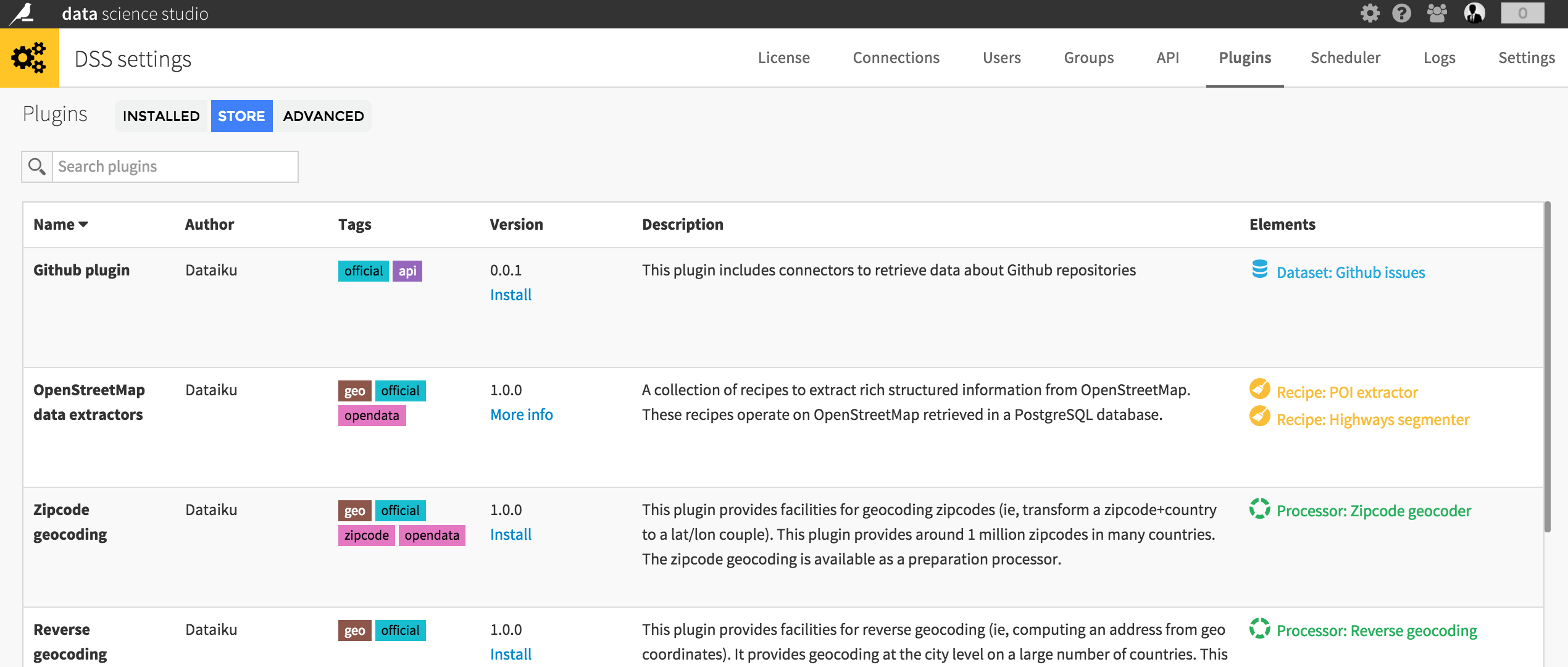
Plugins let you extend the features of DSS. You can add new kinds of datasets, recipes, visual preparation processors, custom formula functions, and more.
Plugins can be downloaded from the official Dataiku community site, or created by you and shared with your team.
Improved charts
- Scatterplots
- Horizonal bar charts
- Pie and donuts charts
- Boxplots
- Pivot tables (text view)
- Geo scatter map
- Geo grid map
- 2D distribution chart
- A brand new user experience
- New drill-down and exclude features
Managed Folder and editable dataset
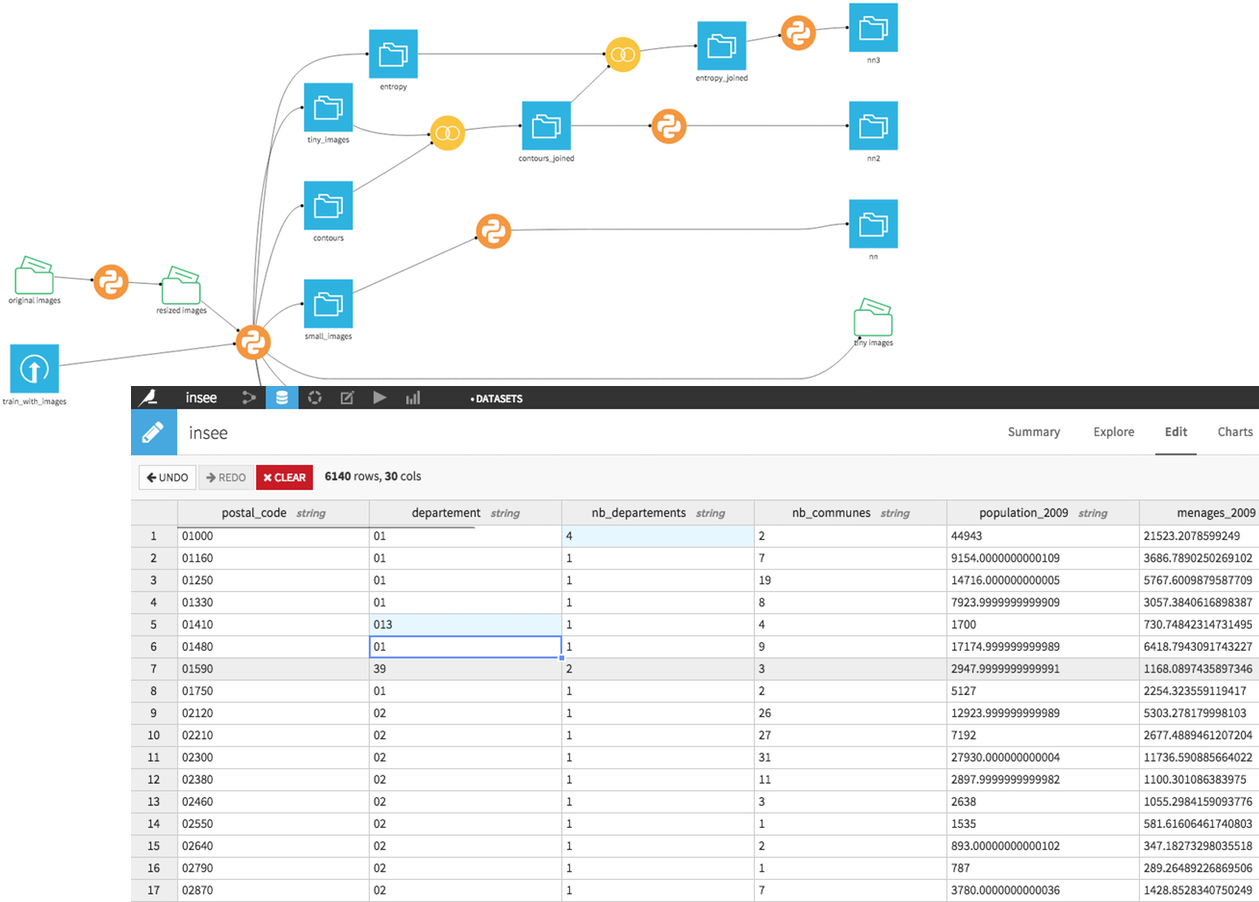
DSS comes with a large number of supported formats, machine learning engines, … But sometimes you want to do more.
DSS code recipes (Python and R) can now read and write from “Managed Folders”, handles on filesystem-hosted folders, where you can store any kind of data.
Editable datasets are a new kind of dataset in DSS, which you can directly create and modify in the DSS UI, ala Excel or Google Spreadsheets.
Shareable code snippets
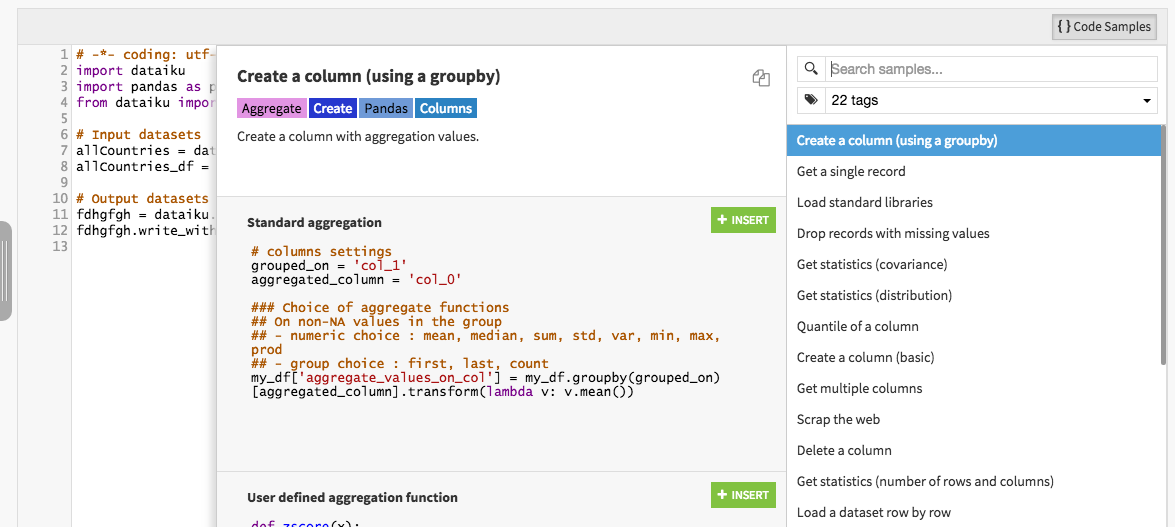
In all modules of DSS where you can write code, you now have the ability to insert code snippets. DSS comes builtin with lots of useful snippets, and you can also write your own and share them with your team.
And much more in DSS 2.1 !
DSS 2.1 is a truly amazing release, and we have only started to cover what’s new:
- A REST public API
- New Jupyter notebook and R API
- Impala recipe
- Shell recipe
See our Release notes.
Version 2.0 – May 2015
New User Experience
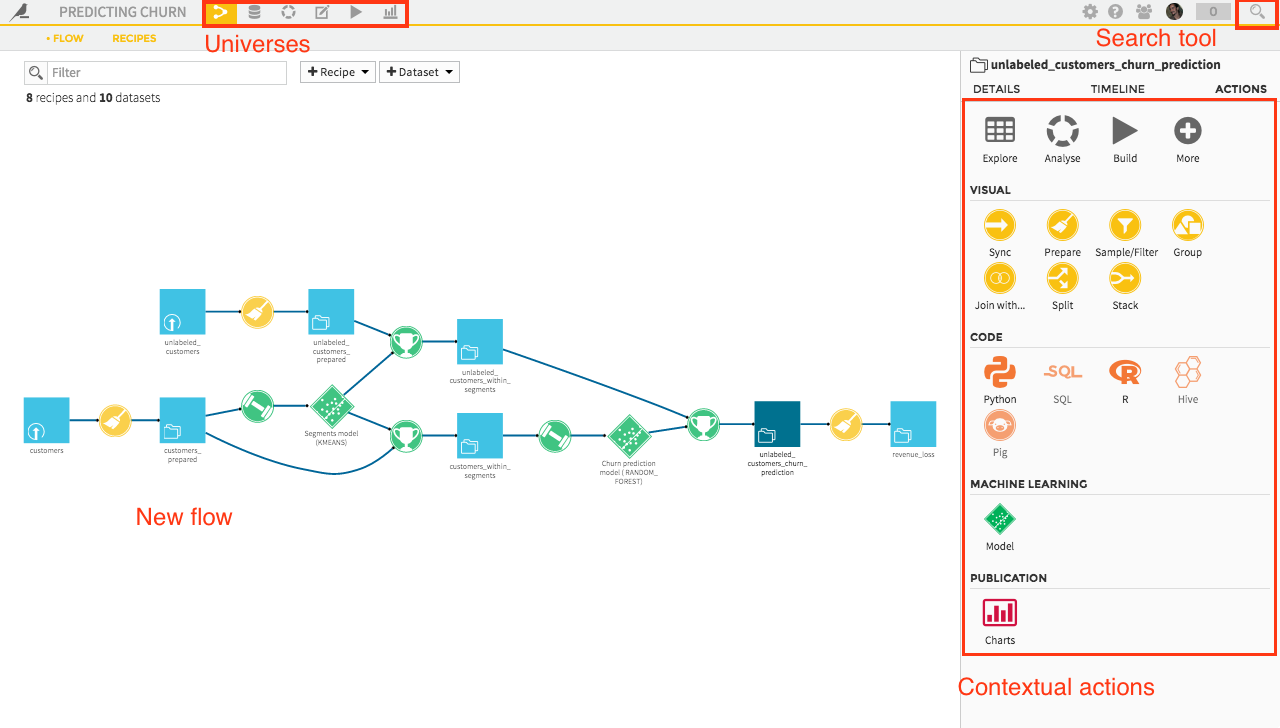
The user experience of DSS has been redesigned and new helper tools added.
- Thanks to the organization in universes, you’ll always find what you need at your fingertips.
- The new sidebar gives you immediate access to all actions in context.
- A redesigned search that gives you immediate access to your recent items and contextually-relevant objects
- The streamlined Flow lets you focus on what matters most and reduces visual clutter
- Use checklists to organize your collaborative work in projects
Vastly improved machine learning
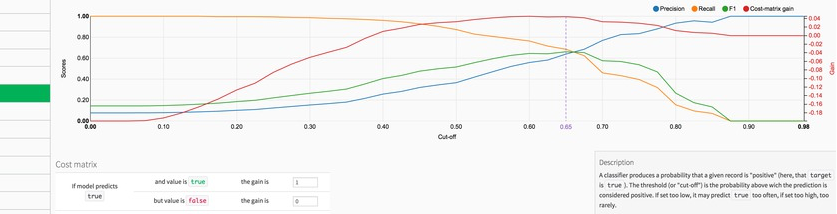
DSS 2.0 brings a completely redesigned machine learning interface, that will let you create both highly performing supervised and unsupervised models. Major enhancements include:
- tight integration with data preparation: the modeling process being highly iterative, DSS lets you now automatically take into account new variables created in a data preparation Script in your Models
- more algorithms: Decision Trees and Gradient Boosted Trees for classification. You can keep on using your own custom models as long as they have an scikit-learn compatible API.
- advanced cross validation: use several strategies to train your models on one dataset and test them on another one
- enhanced features preprocessing : Feature hashing for high cardinality categorical features. Binarization and quantile-cut for numerical features. Hashing, vectorization and TF/IDF for text features
- vastly improved results screens: DSS now offers more helpers to interpret the results of your models, including coefficients of linear models. A new Decision Chart view has been added (an “expanded” view of the confusion matrix for different probability cut-offs), as well as a Density Chart to explore the probability distribution of your mode
- easier deployment process: models can be easily used inside a workflow to score new records, and they can also be retrained on the fly, as your datasets are evolving. DSS will let you see the history of trained models, and select which version should be used in your workflow.
New visual recipes
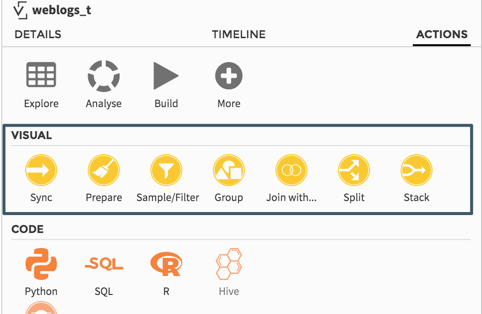
Because writing long SQL code can be tedious and sometimes error prone, and also because not everybody wants to even write code, DSS comes with 5 new visual “recipes” that will help you prepare your data faster.
- Group: quickly generate summarized statistics from the columns of your dataset according to one or several grouping keys (a.k.a group by operations in SQL). No more need to write long and error prone queries: define your grouping keys, your aggregations (including custom expressions), and DSS will generate the underlying code for you, eventually pushing it down to your database or Hadoop cluster.
- Join: an exciting new feature of DSS that helps you merge two or more datasets together. DSS will take you through the steps of visually defining your joins: input data, joining keys, type of join (inner, left…), list of columns to fetch, and even complex conditions such as fuzzy lookups
- Split: create several datasets from an initial dataset, splitting it depending on the value of a column. Need to create one dataset per year ? Need to split a large log file storing different types of events ? Think about this recipe !
- Stack: the opposite operation to Split. It will let you vertically concatenate multiple datasets. Don’t worry if the columns are not in the same order in the datasets, or even if you have different columns: DSS will make both schemas consistent.
- Sample/Filter: select records matching user-defined rules, from the simplest filters to the most complex patterns (including regular expressions). It also provides different ways to sample the records from the dataset, hence making the process of data exploration quicker and easier.
Column-oriented view in preparation
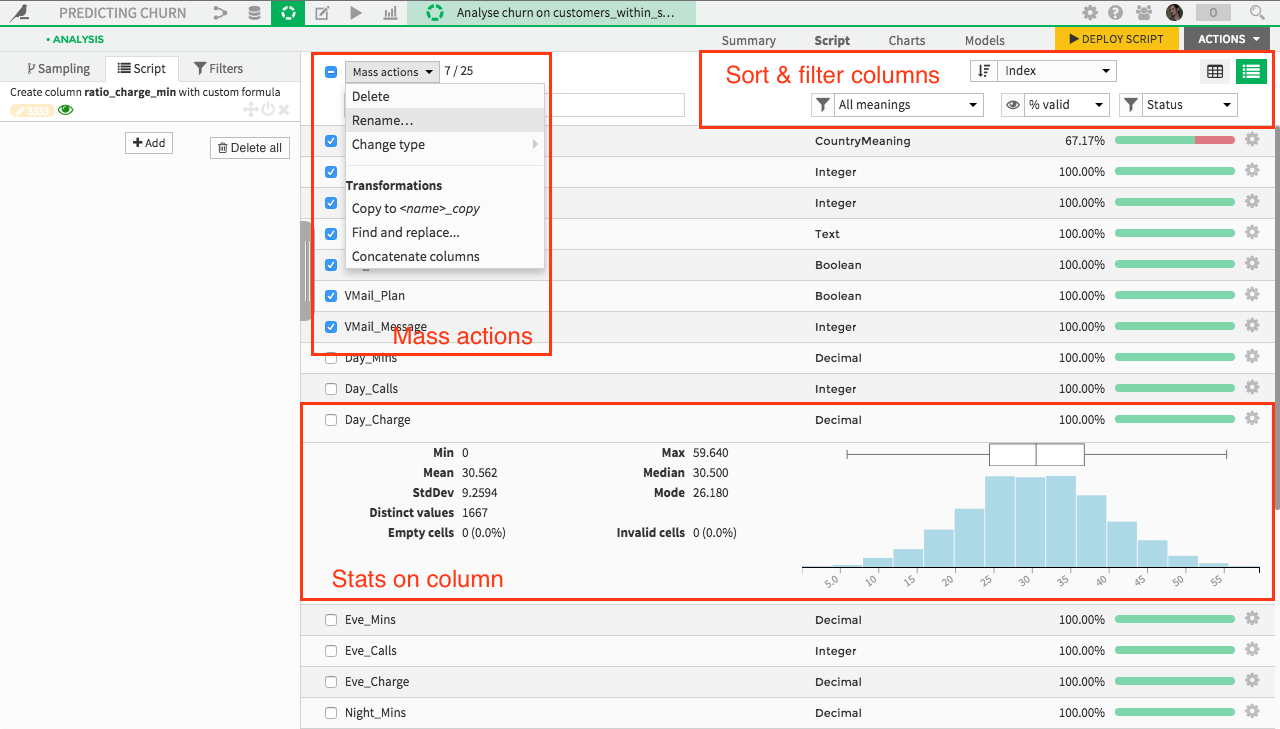
Column-oriented view to understand and apply mass actions to your datasets more intuitively.
Diagnostics
DSS 2.0 lets you easily access to the logs of the server, providing a way to quickly debug your workflows and identify potential issues. It may be super useful for yourself but also when you are interacting with Dataiku’s support team.
To find this tool, go to the Administration menu, and click on the Logs tab. You will easily be able to browse and download the last 1000 records of the backend log file for instance, or use the complete Diagnostic tool to include checks on the configuration of the server hosting DSS.
And much more in DSS 2.0 !
See our Release notes.