What’s new in Dataiku
Take organizations one step further in accelerating agentic delivery and moving to high impact use case operationalization in Dataiku 14.5.

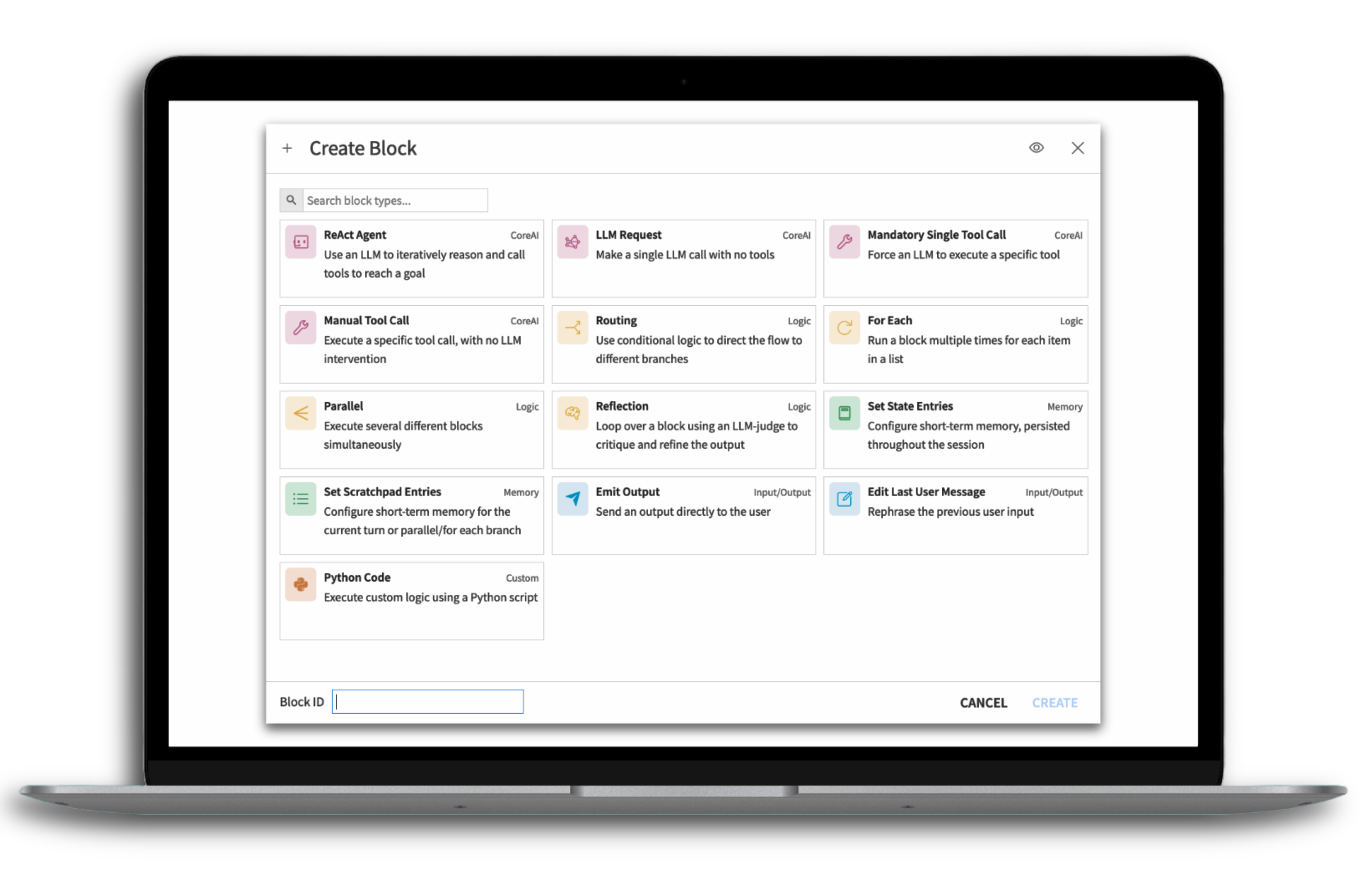
Design deterministic, enterprise-grade agents
Build agentic systems with predictable behavior using visual, rule-based logic and human-in-the-loop controls.
Structured visual agents let teams compose agentic systems visually using ordered blocks and logical branches, including reflection steps and agent handovers.
Builders can require human approvals and enforce tool usage so even complex workflows benefit from strict control.
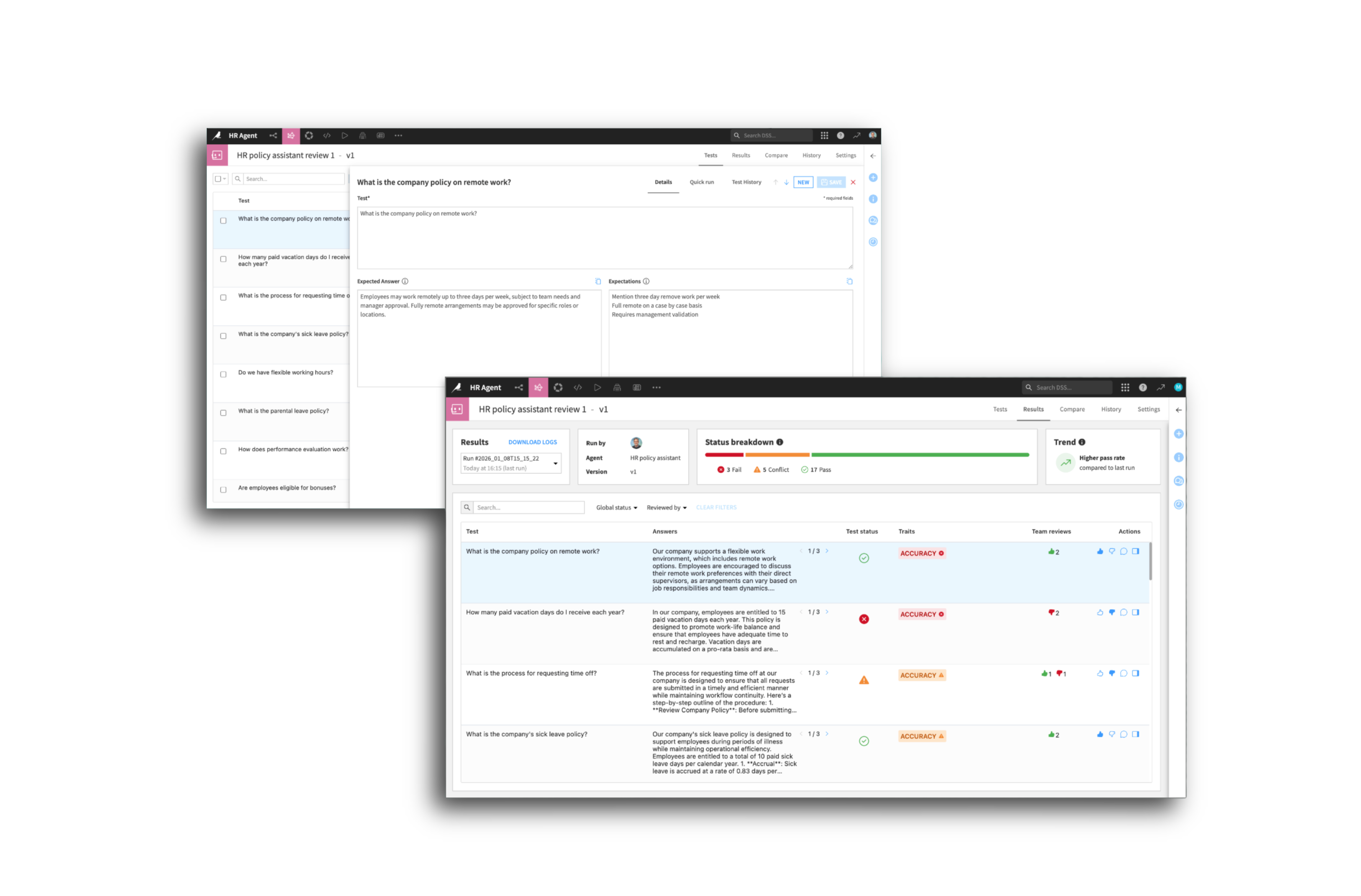
Ground agents in business context
Help agents accurately interpret structured data and business concepts.
Semantic models allow builders to define entities, relationships, glossaries, and SQL instructions, delivering strong business accuracy in data-driven agent interactions.
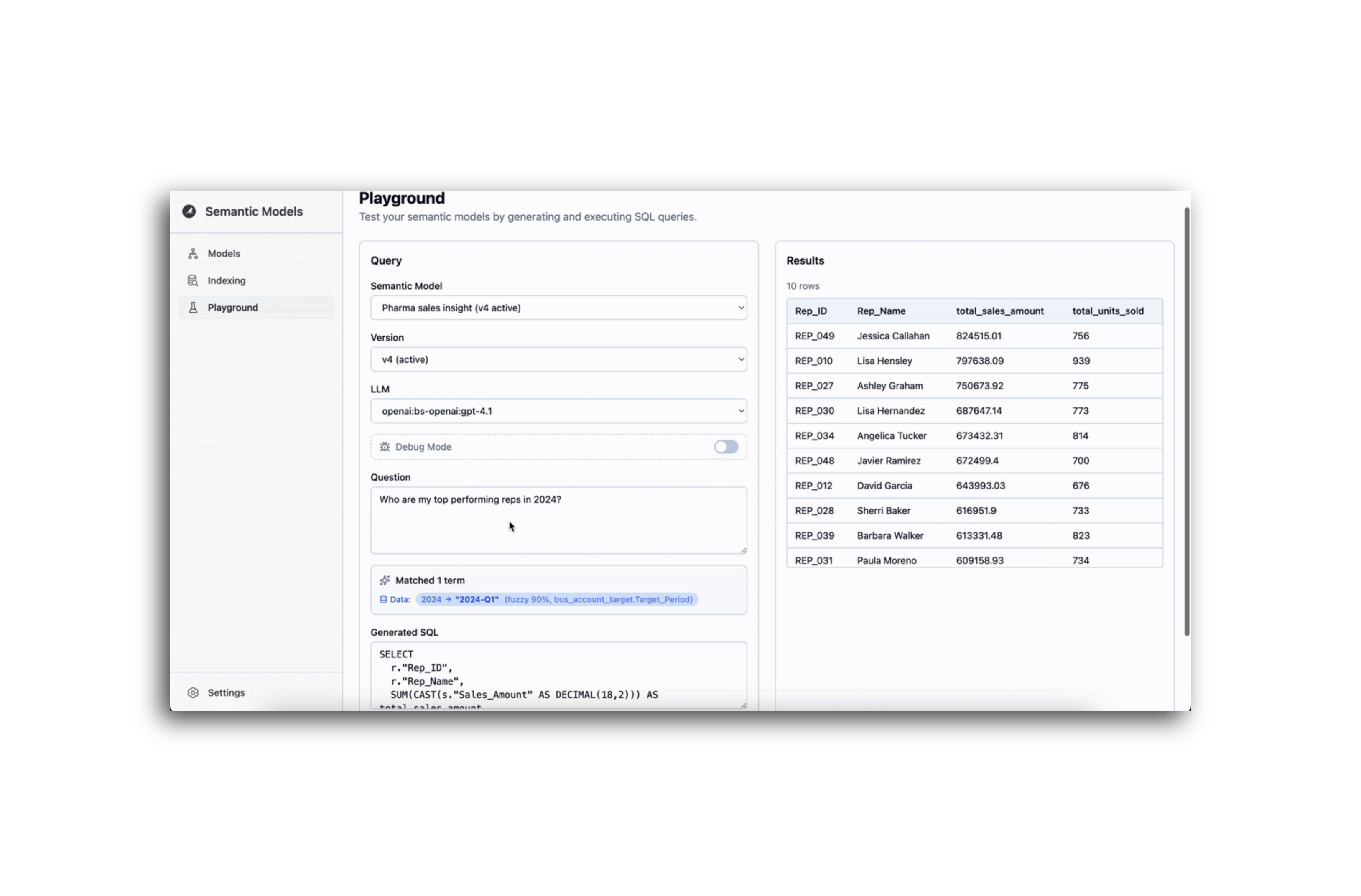
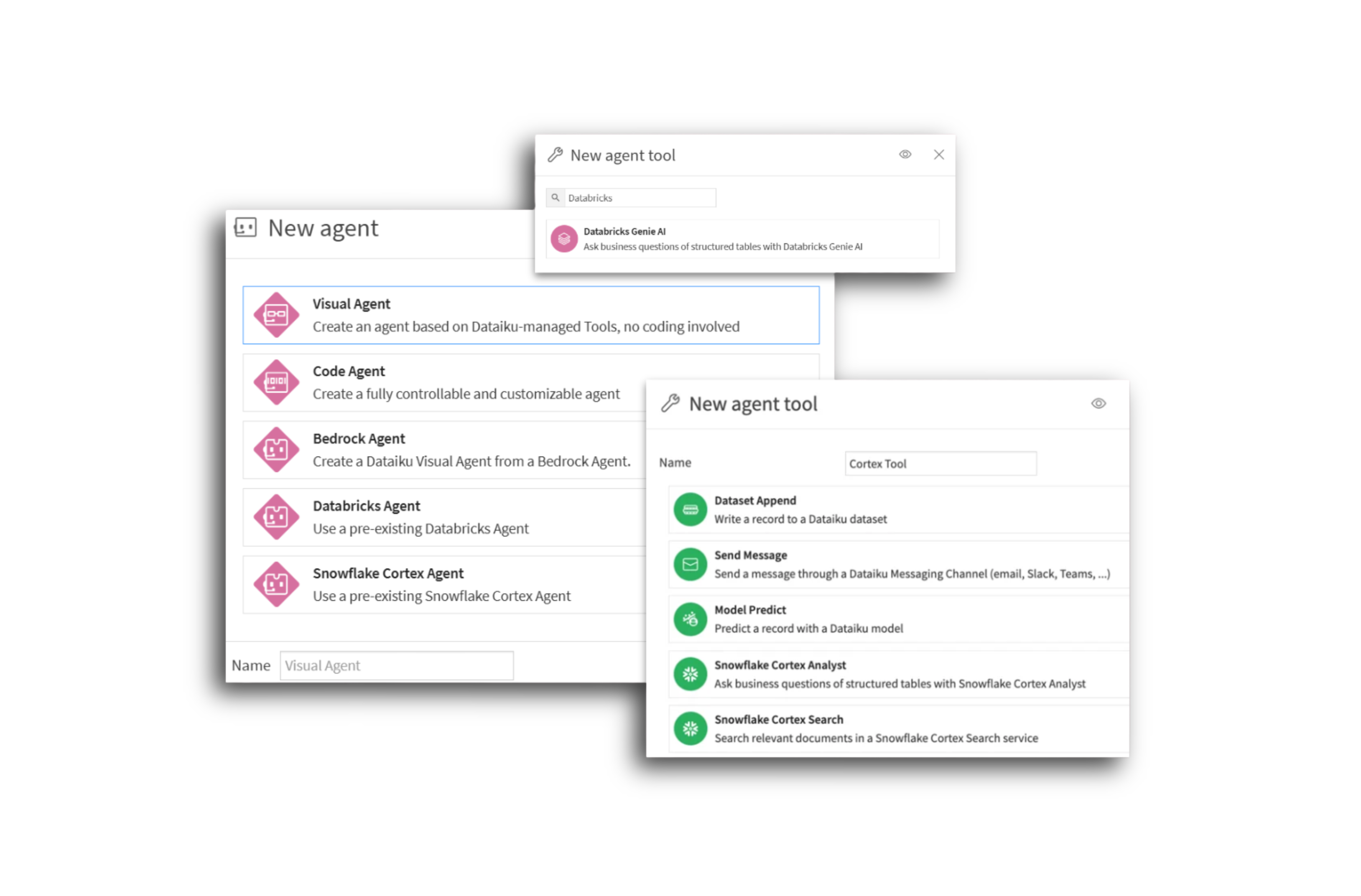
Orchestrate your entire AI ecosystem from one platform
Manage and compose agents across internal assets and third-party platforms like Snowflake Cortex, Databricks, Google Vertex AI, and AWS Bedrock.
External agents become first-class, governed Dataiku agents with centralized testing, monitoring, and orchestration.
Embed trusted agents where business users work
Bridge the gap between technical development and real-world adoption.
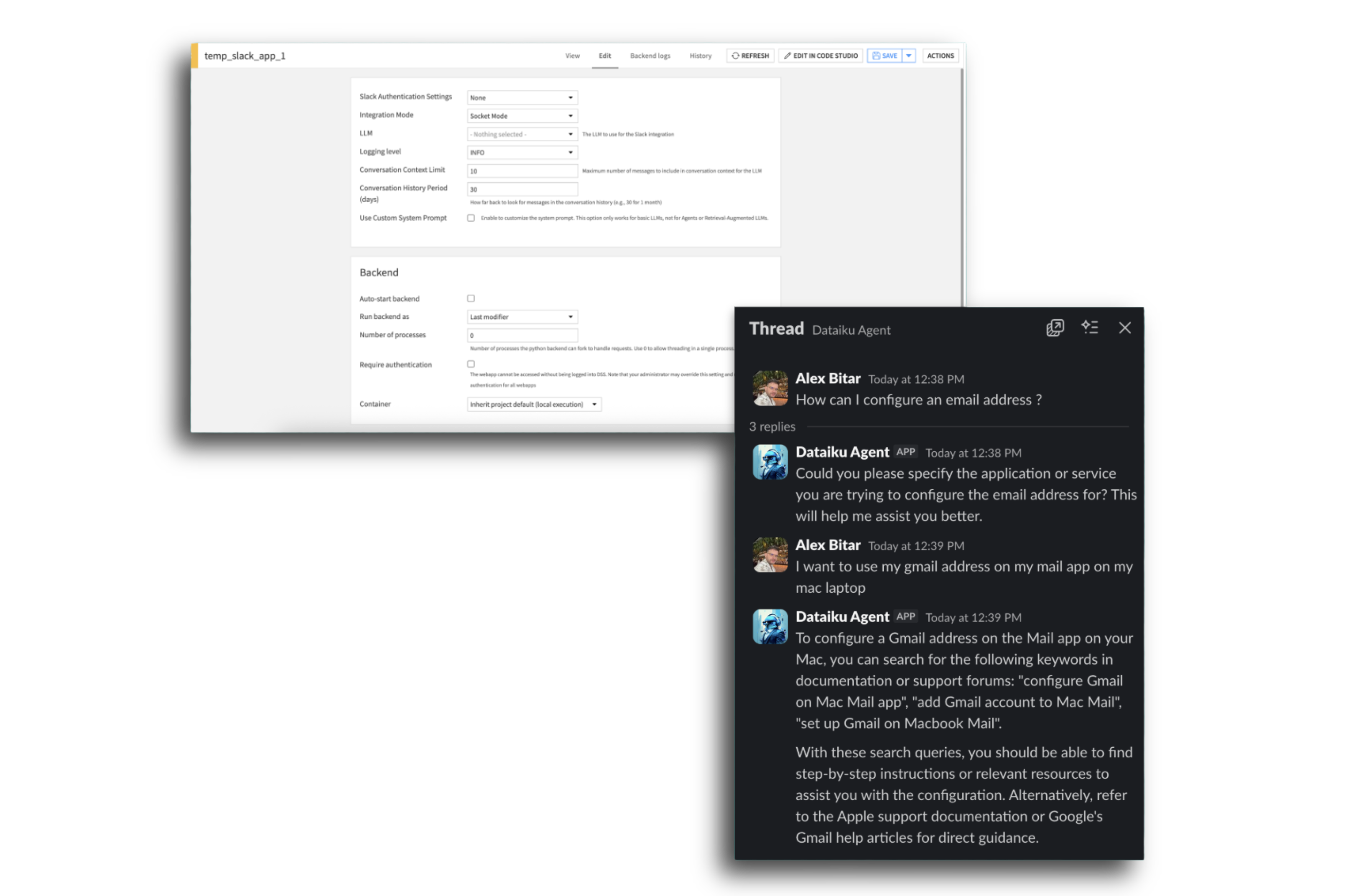
Deploy approved agents directly into Slack, allowing business users to discover and interact with AI agents safely within their existing workflows.
Accelerate everyday data work with AI-assisted workflows
Team up with AI to speed up the entire analytics lifecycle, while preserving transparency and control.
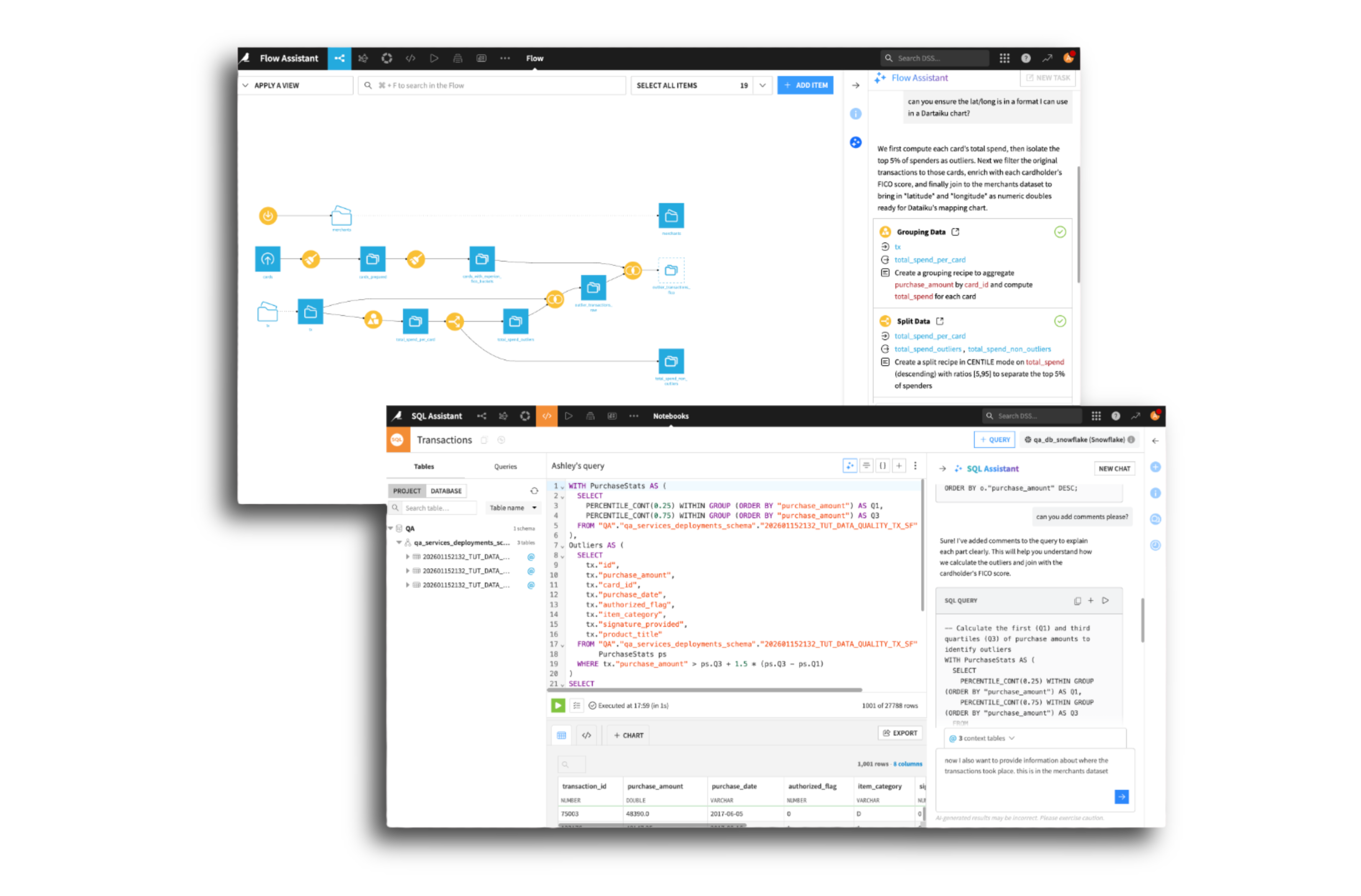
Use Flow Assistant to design pipelines in natural language, AI Search to quickly find relevant datasets, and the SQL Notebook Assistant to build and debug queries faster while retaining full visual interface capabilities for full control.
Enhance AI coding experience
Build and debug AI systems faster with improvements to Code Studio.
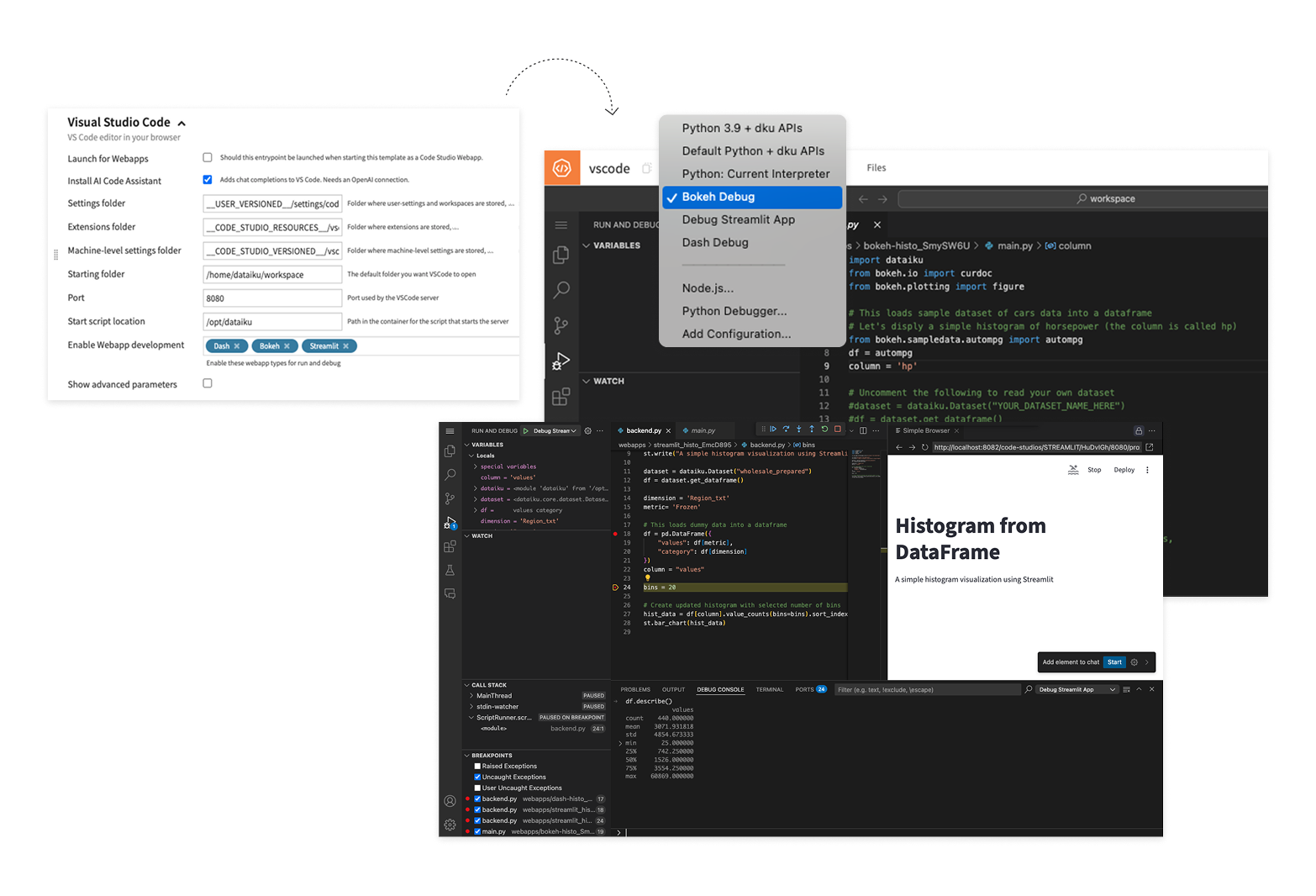
Developers can now debug managed webapps with breakpoints, test and version code agents more easily, and leverage additional AI coding assistants like Claude Code.
Bring Process Mining into your AI strategy
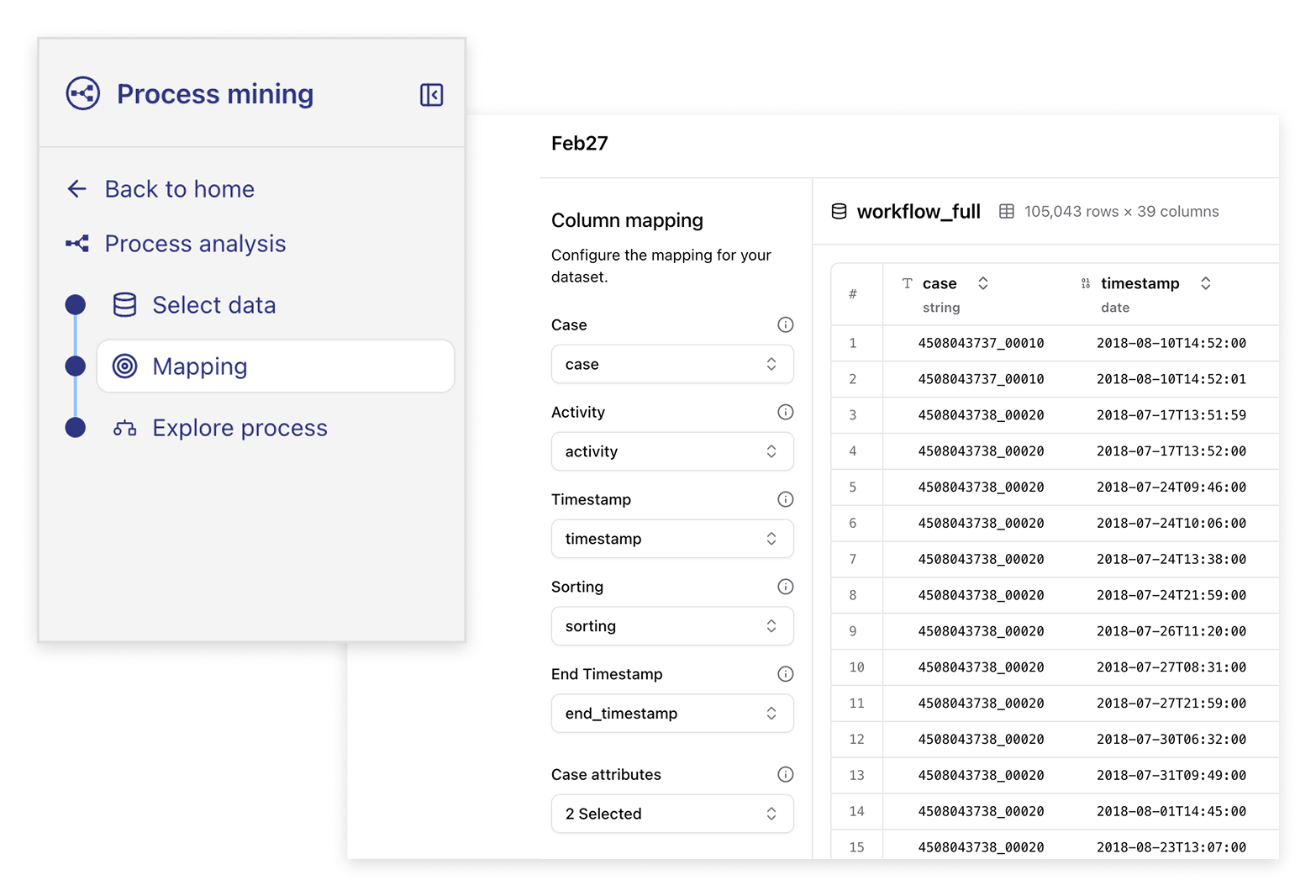
Allow all process owners to turn process data into process insights.
Uncover inefficiencies, unplanned step sequences and conformance gaps, and take action.
Explore previous Dataiku releases
Explore Dataiku 14.5
New features include Agent Chat, Extract Fields recipe, Process Mining application, code agents and webapp testing & debugging in Code Studios, and Claude Code in Code Studios.
Explore Dataiku 14.4
New features include Structured Visual Agent & Human Approval, Agent Review, Semantic Models for Agents, Interact with agent on Slack, Flow Assistant, & AI Search.
Explore Dataiku 14.3
New features include Agent Evaluation, Agent Diagram, and Agent Hub enhancements.
Explore Dataiku 14.2
New features include Agent Hub, connect agents to tools like Gmail, Jira, or Slack, Governance Policies and AI Portfolio Badges.
Explore Dataiku 14.1
New features include Ask Dataiku, Project Standards, and a streamlined Agent Testing interface.
Explore Dataiku 14.0
New features include a new Dataiku homepage, Python tools for Visual Agents, alerting in Unified Monitoring, and theming in Charts, Dashboards and Stories.
Start your Dataiku 14-day trial
Excited about the new features? Start exploring the trial.