




US Patents bulk datasets are made available as XML file from Google
This connector retrieves that data
Since these XML files are not well-formed, this connector provides built-in cleansing and parsing. The resulting dataset contains one “patent” column (JSON) containing the patent metadata, abstract, description and claims
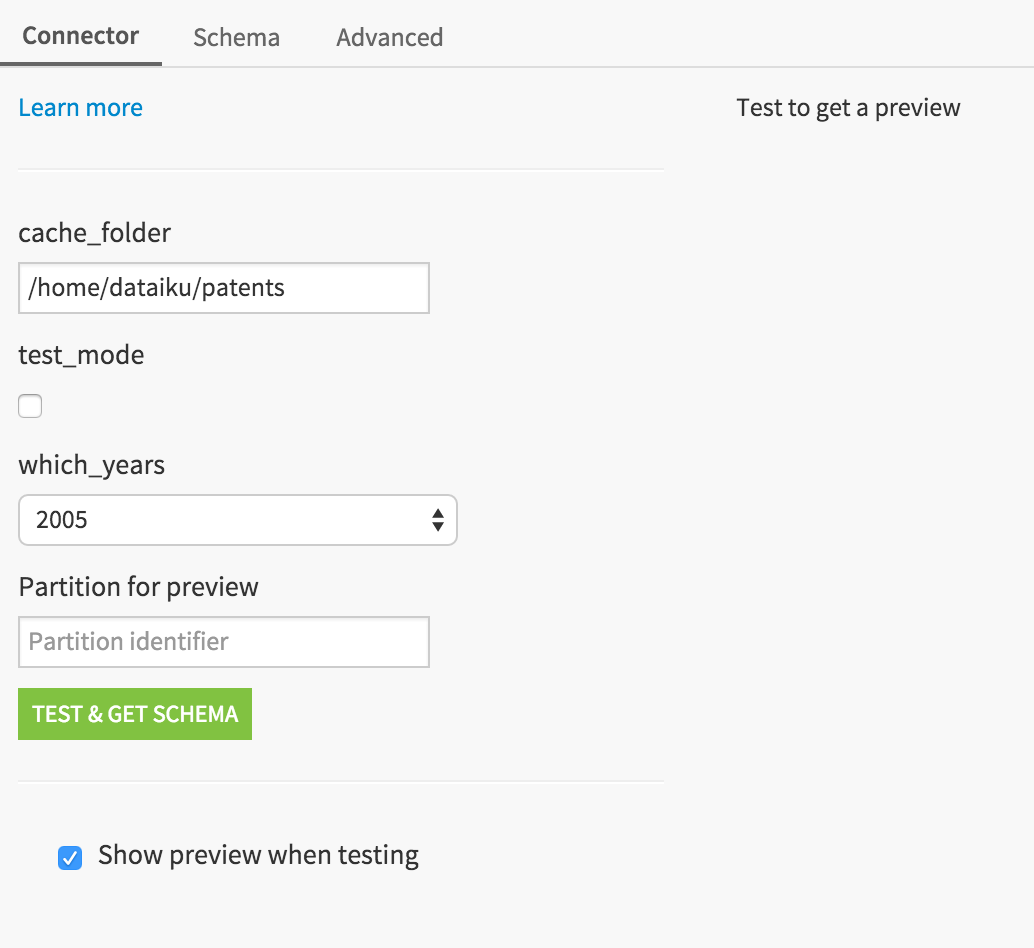
The connector enables a local folder cache to simplify your developments. You can choose to retrieve the whole patent database (beware it’s big : 40GB) or any year between 2005 and 2015
Plugin Information
| Version | 0.0.3 |
|---|---|
| Author | Dataiku |
| Released | 2015-11-15 |
| Last updated | 2015-11-15 |
| License | Apache Software License |
| Source code | Github |
| Reporting issues | Github |
How To Use
You need to install the dependencies of the plugin. Go to the Administration > Plugins page to get the command-line to install dependencies
The dataset is partitioned by year if you select to.