




The US Census Bureau provides thousands of variables describing the population of the USA. This plugins offers the capability to build and use the US Census data directly from Dataiku Data Science Studio. It leverages the large volume of data at a low geographical level to try to increase predictive models performance.
US Census Plugin Key Capabilities
- Build the US Census data with regards to a specific input target variable, with feature selection.
- Build the US Census as a DSS custom Dataset, based on specific settings : Census vintage, geographical level and variables list.
- Two additional helpers are provided: collecting Census metadata and States formats.
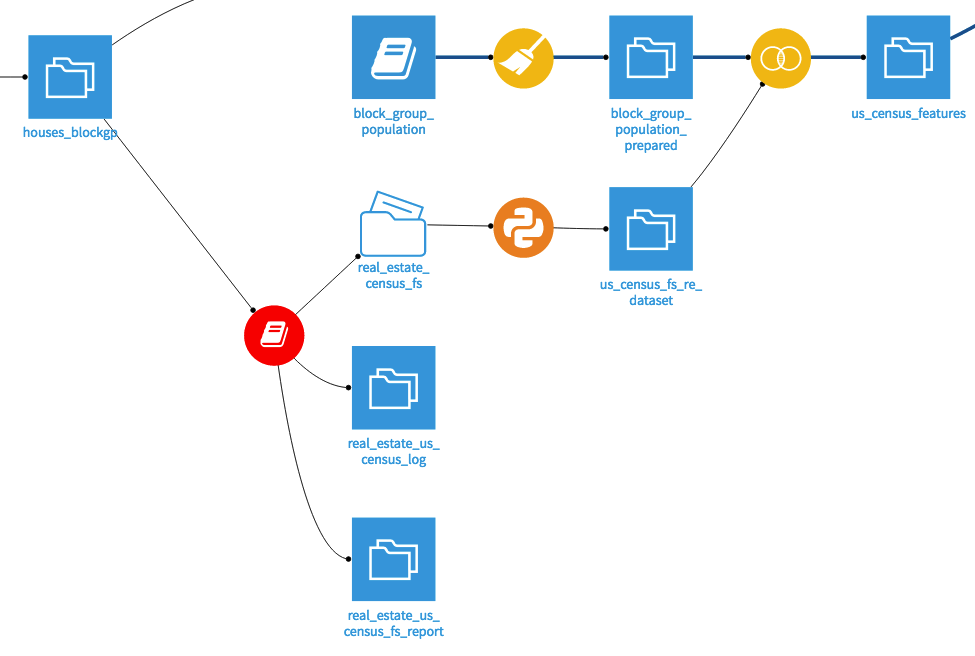
Dataiku Flow with the US Census plugin
Building The US Census With Feature Selection
This feature can be accessed via: New Recipe > Census USA > Build US Census with feature selection
How to use?
- Fill the fields corresponding to the State(s) to build and the geographical level from your input dataset. The plugin offers the capability to chose the US State format (two letters, two digits, text) corresponding to the US Census norm (The custom dataset « US Census states resources » can help to check the format).
- Select the US Census content and the geographical level to build.
- Feature selection:
- the field corresponding to the target in the input dataset, the algorithm
- the number fields max to be returned by the plugin (-1 : All. Beware, it can be 100 or 10,000 !)
- Standard rescaling of the US Census features (only used for feature selection, the plugin only output raw data)
- Imputation strategy: depending on the census level to build, some of the fields can be 100% empty, or for instance just 20% missing. In this second case, the plugin offers the capability to impute the variable with a strategy for considering it in the feature selection process. Important! This feature strategy is only applied for the feature selection, the plugin delivers raw data.
- Output: the plugin output is a DSS managed folder. This set of option is defining how the content will be exported (.csv) into the folder.
- Number of fields max per file. For instance, 600 columns selected, 200 columns max = 3 files.
- All states in one output : If 5 states are in the input dataset, the user may only want only one file.
- Only keep census level matching input: this option generates the census only for your geographical level values: if a state contains 1,000 tracts and your input dataset 300, the plugin only output 300 tracts. By default the plugin generates all the values.
- US Census sources: the plugin doesn’t contain US Census data, it’ll download the sources from the Census systems. The user will have the possibility to keep the temporary data (delete = No) for reusing it later (use previous resources = Yes). All the data are stored into the dss data-dir tmp folder prefixed by « tmp_census_us_ »
Building The US Census With Custom Settings
This feature can be accessed via: New Dataset > Census USA > US Census dataset.
The settings are similar to the feature selection Recipe described above, except for the algorithm and output parts.
Additional Comments
- The Dataiku datasets joined with US Census data require to have a column holding the same geographical “key”. For that purpose, the recipe “Get US census block group from lat lon” provides helper functions to transform initial latitude/longitude coordinates into a US Census “Block” (along with several other levels such as block group, tract, county…).
- This plugin is retrieving data from various US Census systems (FTP, API, Webpage). In case these services are unavailable, please retry the process later.
- This plugin provides raw data from the US Census without any modification.
- The feature selection process is performed State by State. The final output contains the union (distinct) of all the features selected.
Plugin Information
| Version | 0.5.0 |
|---|---|
| Author | Dataiku |
| Released | 2017-03-16 |
| Last updated | 2023-05-05 |
| License | Apache Software License |
| Source code | Github |
| Reporting issues | Github |