




Plugin information
| Version | 1.1.0 |
|---|---|
| Author | Dataiku (Alex Bourret) |
| Released | 2020-09 |
| Last updated | 2023-05 |
| License | Apache Software License |
| Source code | Github |
| Reporting issues | Github |
How to set up
Go to the plugin’s setting page (Dataiku > Plugins > Splunk > Settings > Splunk logins) and add a preset. Complete the access details with the Splunk instance’s URL, an account user name and password.
Note that the Dataiku instance should be allowed to access specific ports on the Splunk instance, notably port 8089.
How to use
Import data from Splunk
- In your Dataiku project flow, select Dataset > Splunk
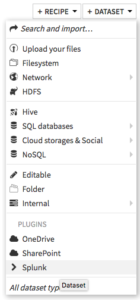
- Click Splunk index
- Select the Splunk login to use and fill in the search string, and index name, then click Test & Get Schema
Export data to Splunk
Dataiku datasets can be exported to Splunk. This will trigger a one-shot indexation of the Dataiku data. Splunk uses a specific data structure:
- By default, each row of the Dataiku dataset will be concatenated into a dictionary and stored into the column called _raw.
- If the exported data has a schema corresponding to Splunk’s data structure, the content of these columns will be stored into corresponding Splunk columns, and not into _raw. As an example, it means you can import a Splunk index, enrich it with Dataiku and send it back to another Splunk index while keeping the original event timestamps in the timestamp column.
Usage:
- Select the dataset to export, then select the Exporter to folder recipe.
- Create an output folder. This folder is necessary but will be kept empty. Then click on Create Recipe.
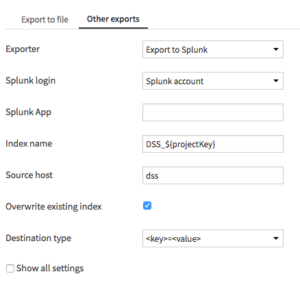
- In the Other exports tab, choose Export to Splunk as exporter, pick the right Splunk account

Setup the exporter recipe - Splunk app
- Index name
- Source host, changes the source host as reported in the Splunk index
- Overwrite existing index
- Destination type the whole dataset schema exported to Splunk will be contained in one Splunk column called _raw. Here, you can pick the encoding used to fit the Dataiku dataset into the _raw column. It can be:
- JSON or
- <key>=<value>
- Press Run.
If the exported dataset is a modified version of an imported Splunk dataset (containing more or less the same columns as a Splunk dataset), they will extracted and used by Splunk for its own indexing. This way, important features such as the timing of the events (contained in the _timing column) will be preserved.
However, some reserved column names will be ignored by Splunk. According to Splunk documentation, there are: _event_status, _indextime, _subsecond, _value, date_hour, date_mday, date_minute, date_month, date_second, date_wday, date_year, date_zone, linecount, timeendpos, timestartpos, metric_timestamp, punct, time, timestamp