




Plugin Information
| Version | 1.6.0 |
|---|---|
| Author | Dataiku (Alex COMBESSIE, Hicham EL BOUKKOURI) |
| Released | 2018-07 |
| Last updated | 2023-04 |
| License | BSD 3-Clause License |
| Source code | Github |
| Reporting issues | Github |
With this plugin, you will be able to estimate the sentiment polarity (positive/negative) of text data in English.
Table of contents
How to set up
Right after installing the plugin, you need to build its code environment.
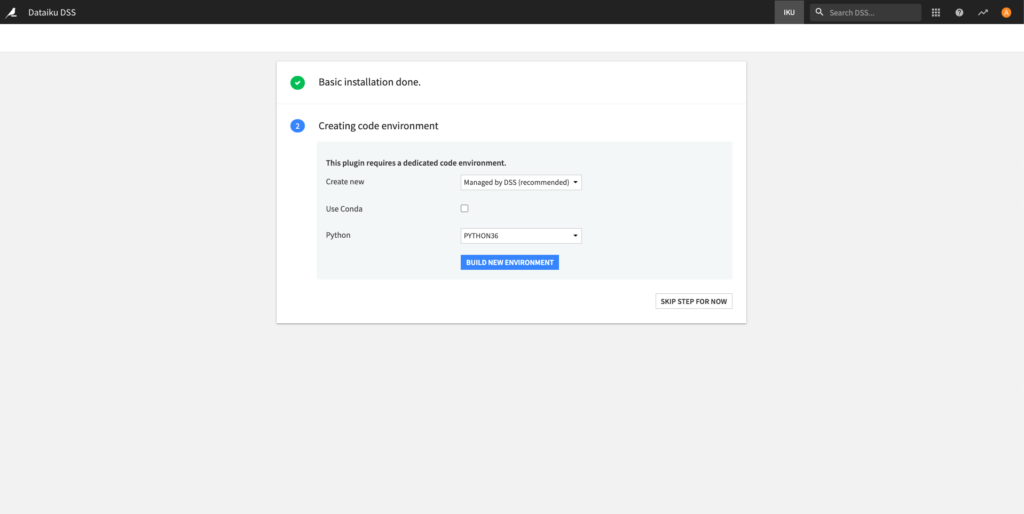
This plugin requires Python version 2.7, 3.6, or 3.7 to be installed on the machine hosting DSS.
How to use
Let’s assume that you have a Dataiku DSS project with a dataset containing text data in English. This text data must be stored in a dataset, inside a text column, with one row for each document.
Navigate to the Flow, click on the + RECIPE button and access the Natural Language Processing menu. If your dataset is selected, you can directly find the plugin on the right panel.
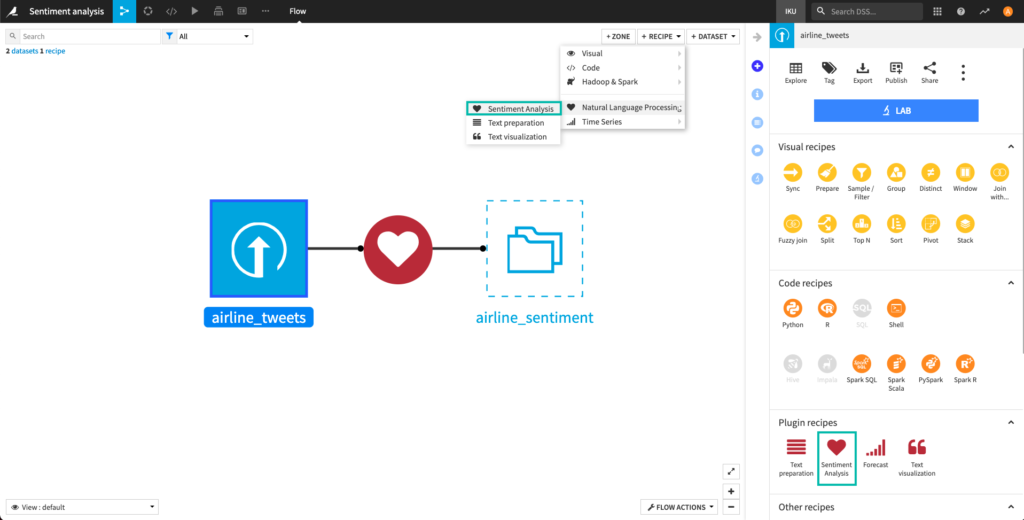
Sentiment analysis recipe
Estimate the sentiment polarity (positive/negative) of text data in English
Input
- Text dataset: Dataset with a text column (in English)
Settings
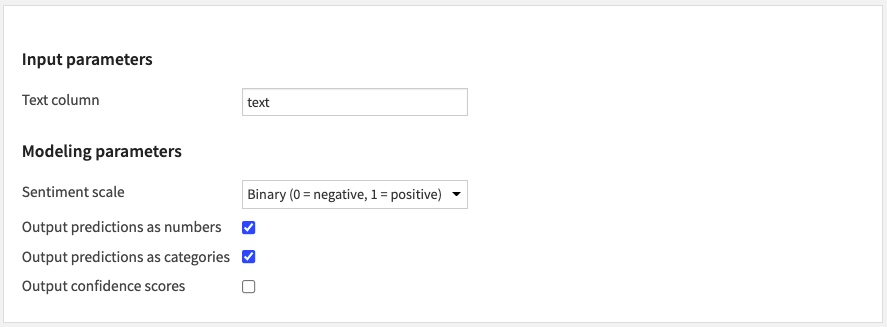
- Fill Input parameters
- The Text column parameter lets you choose the column of your input dataset containing text data.
- Choose Model parameters
- Choose your Sentiment scale.
- Either binary (0 = negative, 1 = positive) or 1 to 5 (1 = highly negative, 5 = highly positive).
- Default is binary.
- Choose whether to Output predictions as numbers and/or Output predictions as categories.
- These parameters depend on the chosen Sentiment scale.
- Default is yes to both.
- Choose whether to Output confidence scores for the predicted sentiment polarity.
- Confidence scores are from 0 to 1.
- Default is false.
- Choose your Sentiment scale.
Output
- Output dataset: Copy of the input dataset with additional columns on predicted sentiment polarity
Troubleshooting
- When installing / setting up the plugin’s code environment, getting an error
Unsupported compiler -- at least C++11 support is needed: installing thepython3-devsystem package may help, see here. - When installing / setting up the plugin’s code environment, getting a
fatal error: Python.h: No such file or directory: installing thepython3-devsystem package may help, see here.
Happy natural language processing!