Amazon Web Services (AWS) is one of the leading providers for Cloud Infrastructure and Platform Services, and a Dataiku partner.
This plugin enables Dataiku users to leverage aspects of the Amazon SageMaker service within DSS in order to collaboratively build, deploy, and use SageMaker models.
This plugin comes with the following features:
- Prepare datasets specifically for use with Amazon Sagemaker
- Visually create analytics pipelines and applications that use models developed in Sagemaker
- Use Dataiku’s visual interface to train and score models leveraging Amazon Sagemaker
- Collaborate with data scientists through sharing auto-generated Jupyter notebooks
- Easily evaluate pre-trained SageMaker models from Dataiku
- Quickly convert any dataset to the formats required by SageMaker
As the plugin relies on the SageMaker API, any data limitations that apply to SageMaker models are also limitations of the plugin. Specific information on the SageMaker API can be found here.
Plugin Information
| Version | 1.0.0 |
|---|---|
| Author | Dataiku |
| Released | 2020-12 |
| Last updated | 2020-12 |
| License | MIT License |
Requirements
This plugin requires DSS 7.0.0 or higher. The installation setup for this plugin follows the standard Dataiku code environment creation procedure and will install the following libraries:
- boto3==1.14.21
- sagemaker==2.10.0
- scikit-learn==0.23.1
How To Set Up
In order to use the different components of the plugin, a DSS admin needs to set up an AWS configuration preset with AWS credentials and instances settings.
Go to Plugin > Amazon SageMaker > Settings > AWS configuration presets > + Add preset.
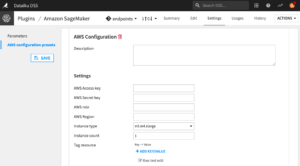
- Enter your AWS credentials (access and secret key), an AWS role that has SageMaker permissions and an AWS region (e.g. “us-east-1”). Before selecting a region, you can confirm that your region has access to SageMaker resources here
- Select an instance type from the dropdown list as well as an instance count. These instances will be used for when scoring or deploying a model. SageMaker Autopilot will automatically select the right instance.
- You can optionally enter tags that will be used to tag any resources that will be launched by SageMaker (training job, scoring job, deployment).
How To Use
This plugin provides 5 visual recipes to convert data, train, score and evaluate Machine Learning models using Amazon SageMaker. Additionally, this plugin adds a macro to deploy and delete SageMaker models as endpoints and a plugin preset enabling AWS SageMaker credentials to be accessible to all users on the Dataiku instance of your organisation.
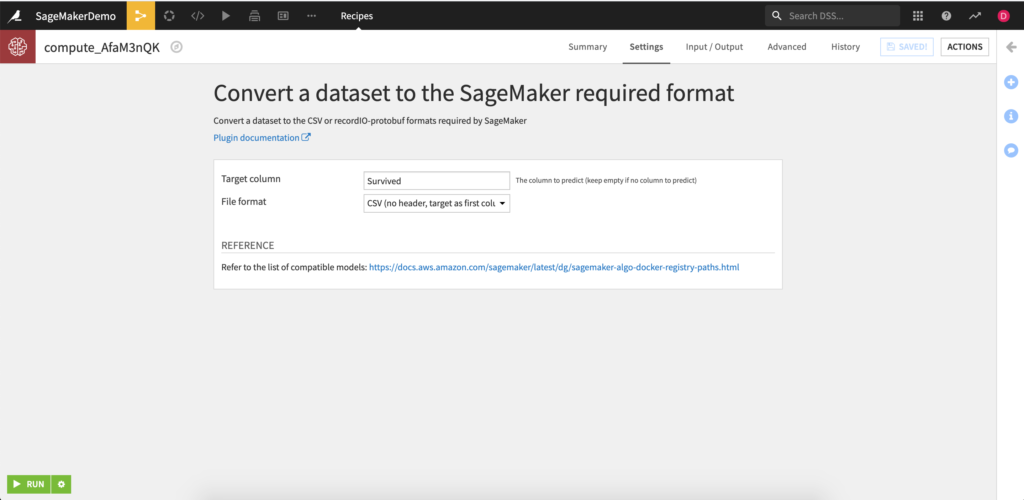
Convert Dataset Recipe
The Convert Dataset Recipe allows Dataiku users to convert and transfer an input dataset to S3 in the required format for training with most built-in SageMaker models. Through this recipe, users can be sure that their data has been prepped, cleaned, and converted to the final format needed for training. The current version of the plugin only supports conversion for SageMaker models that accept numeric columns. Please refer to the SageMaker documentation for more information on model input data requirements.
SageMaker Autopilot
Using the Autopilot recipe, Dataiku users can trigger the training of model via SageMaker autopilot without having to leave the DSS interface or set up training infrastructure.
Inputs:
- Train dataset (must have at least 1000 rows).
Outputs:
- Folder stored in S3 containing ML trained models (a new subfolder is created each time the recipe is run).
- Dataset containing a summary of all ML training jobs.
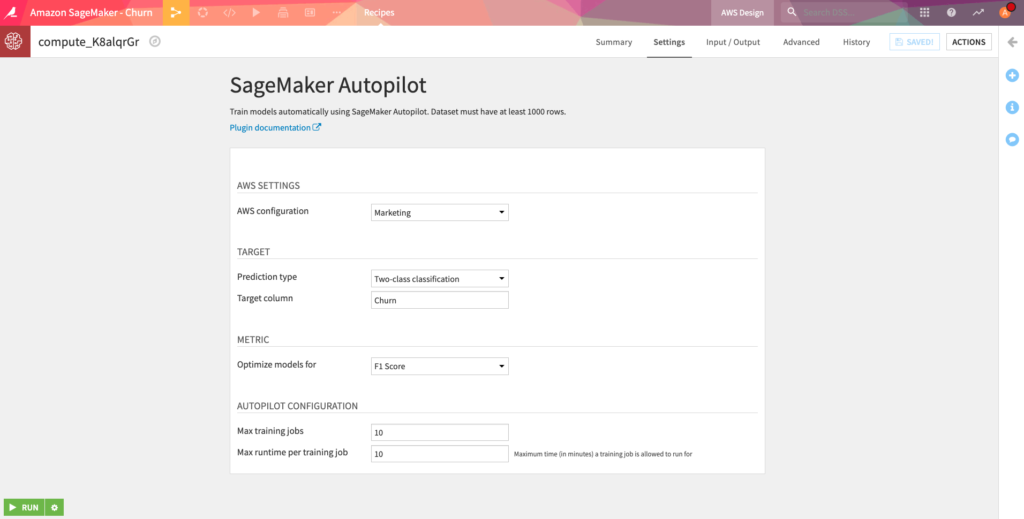
Prediction Type:
- Two-class classification – target column must be 0 or 1
- Multiclass classification – target column must have values in [0, num_class)
- Regression – target column must be between 0 and 1
The output managed folder includes subfolders for every run of the recipe. Within these subfolders, information about the autopilot training job (e.g. training and validation), preprocessed data, auto-generated jupyter notebooks, and more can be found.
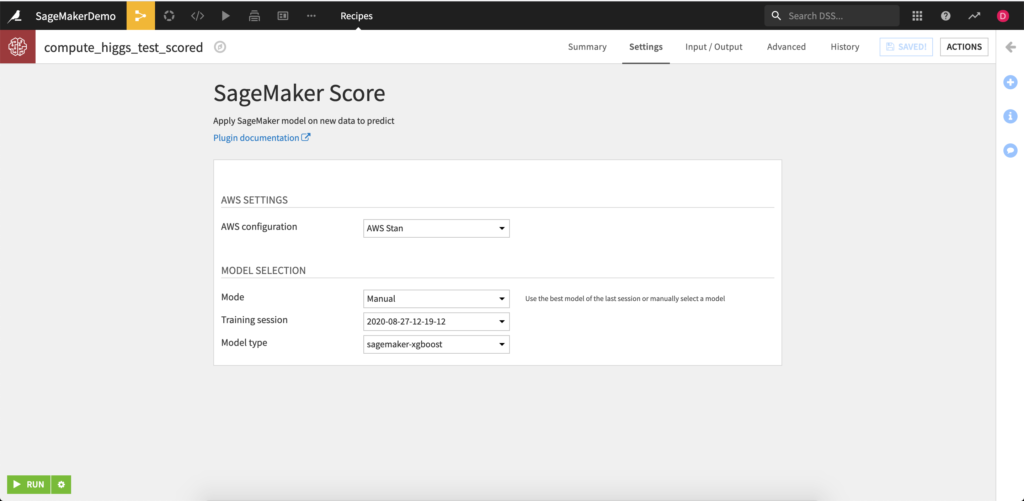
SageMaker Score
The SageMaker Score recipe can be used to batch score unlabeled data after a model has been training. This recipe will work for all SageMaker ML models so long as it is provided with the model artifact in a managed S3 folder.
Inputs:
- Test dataset with same schema as the dataset used for training
- Managed S3 folder containing a trained model(s).
Outputs:
- Output dataset for the recipe to write the newly scored data using the SageMaker model.
SageMaker Evaluate
The Evaluate recipe can be used to test a SageMaker model against labeled data to confirm the robustness, strength, and accuracy of a model.
Inputs:
- Test dataset with same schema as the dataset used for training. It must contain the target column to be compatible with the Evaluate recipe.
- Managed S3 folder containing a trained model(s).
Outputs:
- Output dataset for the recipe to write the newly scored data using the SageMaker model.
- Output dataset for writing the evaluation metrics.
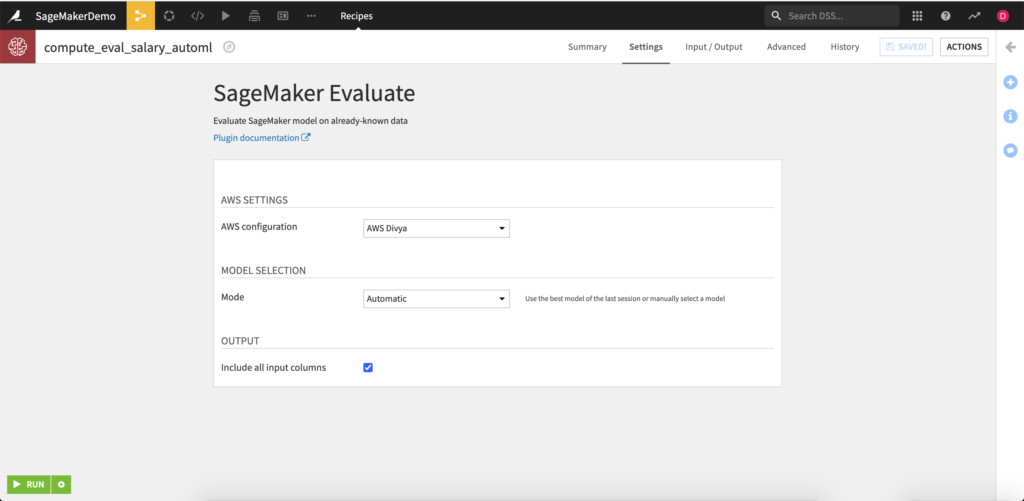
Model Selection:
- Automatic: if you want to select the best model of the last session based on the optimisation metric.
- Manual: if you want to select the model yourself (by selection a training session and a model type).
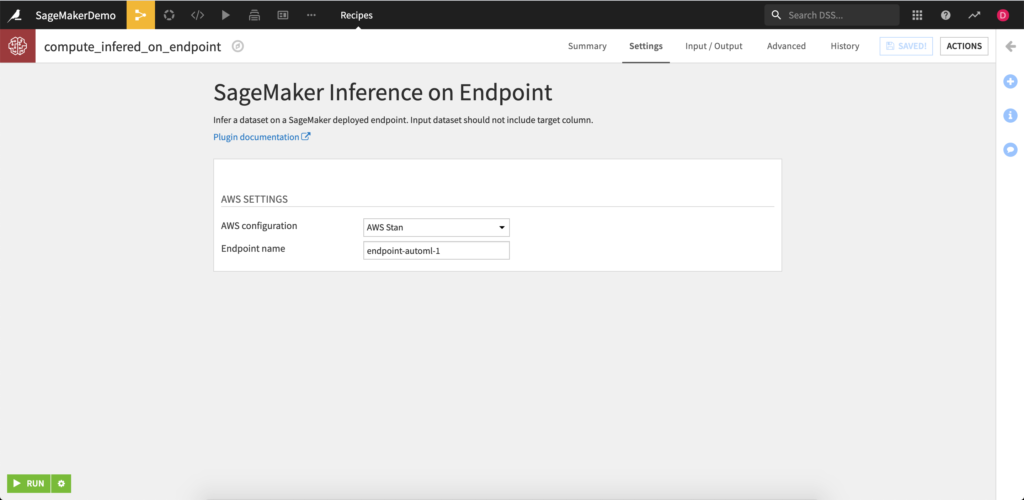
SageMaker Endpoint Scoring
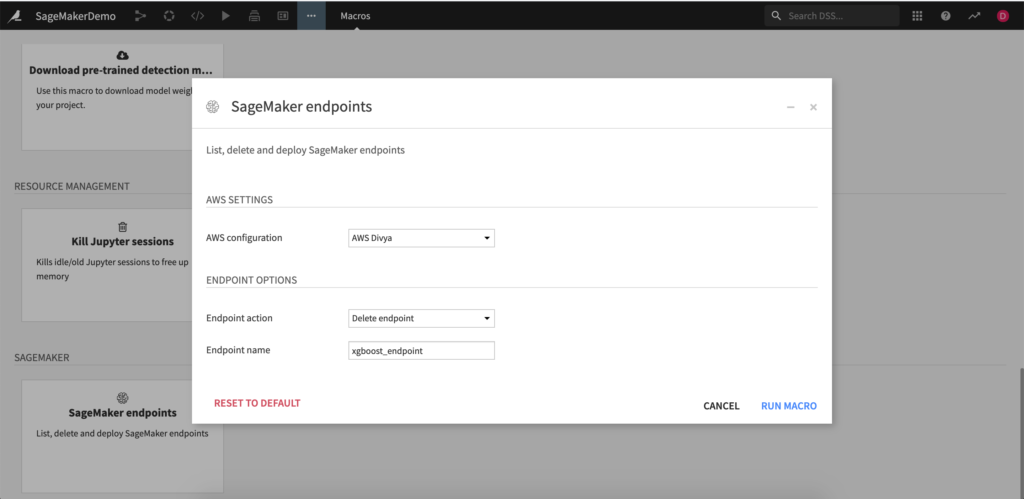
If you don’t already have a SageMaker Endpoint deployed, this plugin includes a macro that will enable deployment SageMaker Endpoints. Simply select an existing AWS SageMaker preset, enter the model job name (this can be retrieved from the SageMaker UI or from the output folder of the Autopilot recipe), name the endpoint, and run.
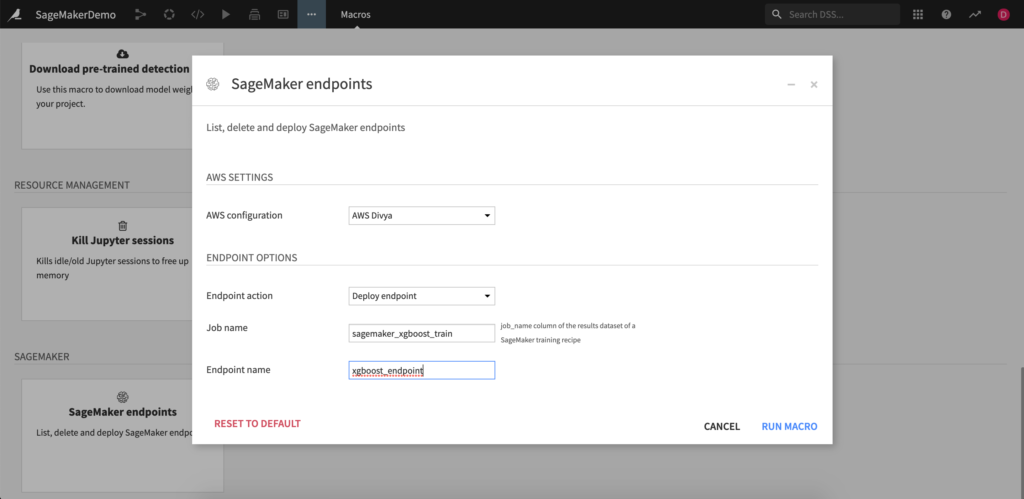
This macro can also be used to list all existing endpoints available and delete any existing endpoint.
Once you have a deployed SageMaker endpoint, the Endpoint Scoring recipe can be used. It is compatible with all SageMaker endpoints (even those not created and deployed using the macro) so long as the input data requirements are met.
Inputs:
- Unlabeled dataset for scoring with same schema as the dataset used for training
Outputs:
- Output dataset for the recipe to write the newly scored data using the SageMaker model endpoint.