




Description
The plugin’s purpose is to ease the labeling task. First, the plugin, through the webapps, offer a powerful annotation tool for various types of data (images, sounds, texts, tabular data). For large datasets or with a limited labeling budget, we also propose an Active Learning recipe and a scenario that transforms the labeling task into an iterative ML-assisted labeling process.
When you need to manually label rows for a machine learning classification problem, active learning can optimize the order in which you process the unlabeled data. The ML-assisted Labeling plugin enables active learning techniques in Dataiku DSS.
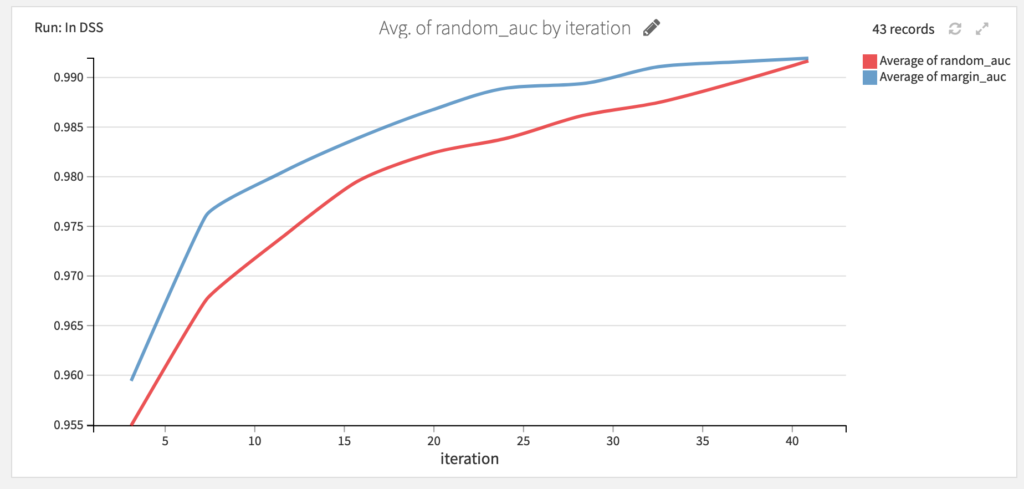
Not all samples bring the same amount of information when it comes to training a model. Labeling a very similar to an already labeled sample might not bring any improvement to the model performance. Active learning aims at estimating how much additional information labeling a sample can bring to a model and select the next sample to label accordingly. As an example, see how active learning performs compare to random sample annotation on a task of predicting wine color:
How to use
This plugin offers a collection of visual webapps to label data (whether tabular, sound, image classification or object detection), a visual recipe to which sample needs to be labeled next, and a scenario trigger to automate the rebuild of the ML model that assists in determining which sample is labeled next.
- Requirements
- Installation
- Data Labeling (webapp)
- Train a model and score unlabeled data with the Active Learning recipe
- Set up a Active Learning scenario (scenario)
- ‘Reformat image annotations’ recipe for DSS Computer vision
For more details on how to use the plugin, use the reference documentation.
Requirements
The plugin will require a python 3.6 code env.
For object detection, you should also have installed the ‘Object detection in images’ plugin (available for CPU and GPU).
Installation
- Install the plugin using the instructions in the right side “Install in DSS”
- Create a python 3.6 code env
- If you use the Dataiku Applications (see details on Labeling Webapp), you should add a code env to the parameters of the plugin, for the specific labeling method you will use.
Go on you plugin page : Plugins > ML-Assisted-Labeling > Settings, on the left column choose the labeling method you will use and add a new Code env called ‘ml-assisted-labeling-visual-ml-python-36’, that should link to a python 3.6 env that you have already created (here’s a link describing how to create a new code environment in DSS)

- For object detection only : also install the ‘Object detection in images’ plugin (either CPU or GPU) and create the python 3.6 code env for that plugin
Data labeling (Webapp)
This plugin offers labeling webapps for multiple use cases :
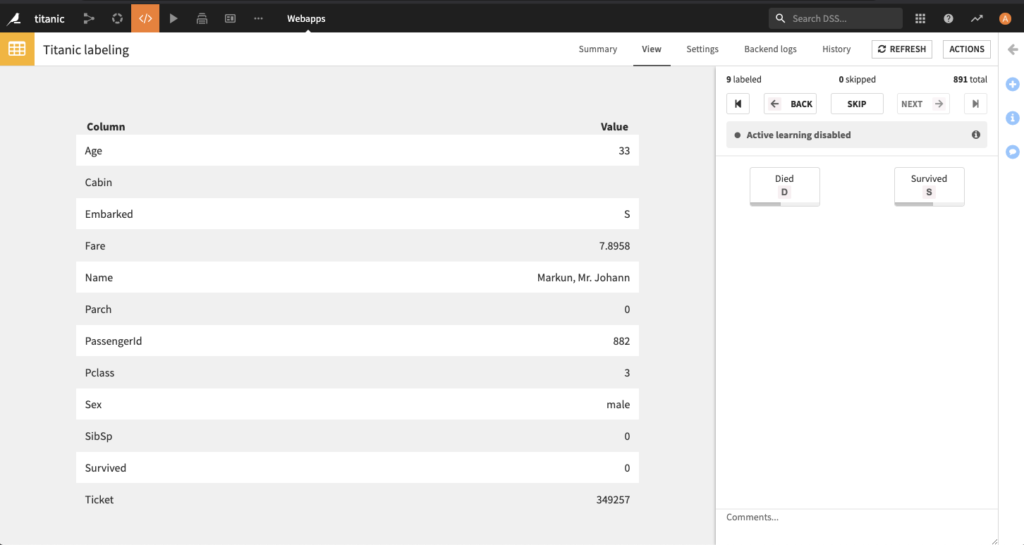
| Tabluar data classification | Images classification |
 |
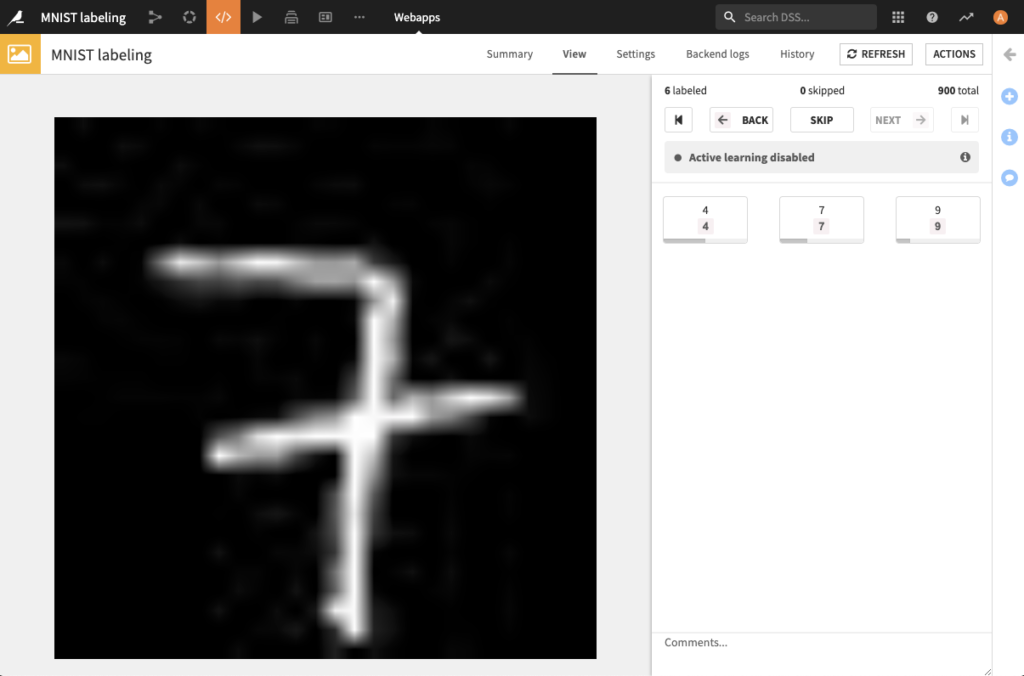 |
| Object detection on images | Sound labeling |
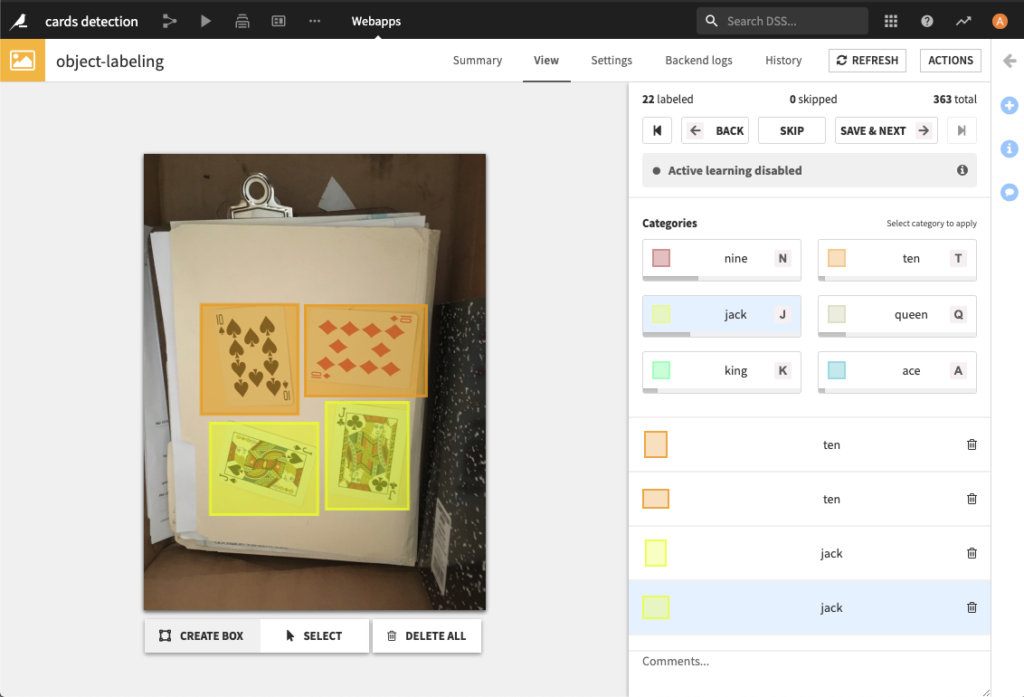 |
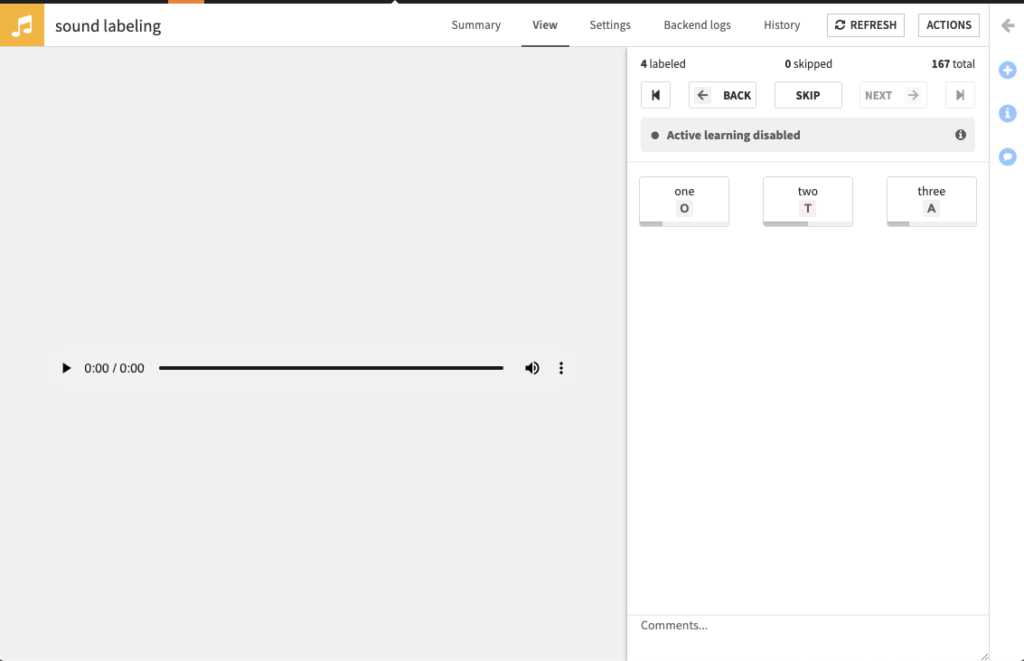 |
| Text assisted labelling | |
 |
1. Create the webapp


If you have a Missing code env error when creating a Dataiku Application, make sure you added the python code env in the parameters of your plugin (see more details).
2. Configure the webapp
General settings
All labeling webapps offer the same settings. Here is an example of the settings page for the image labeling webapp:
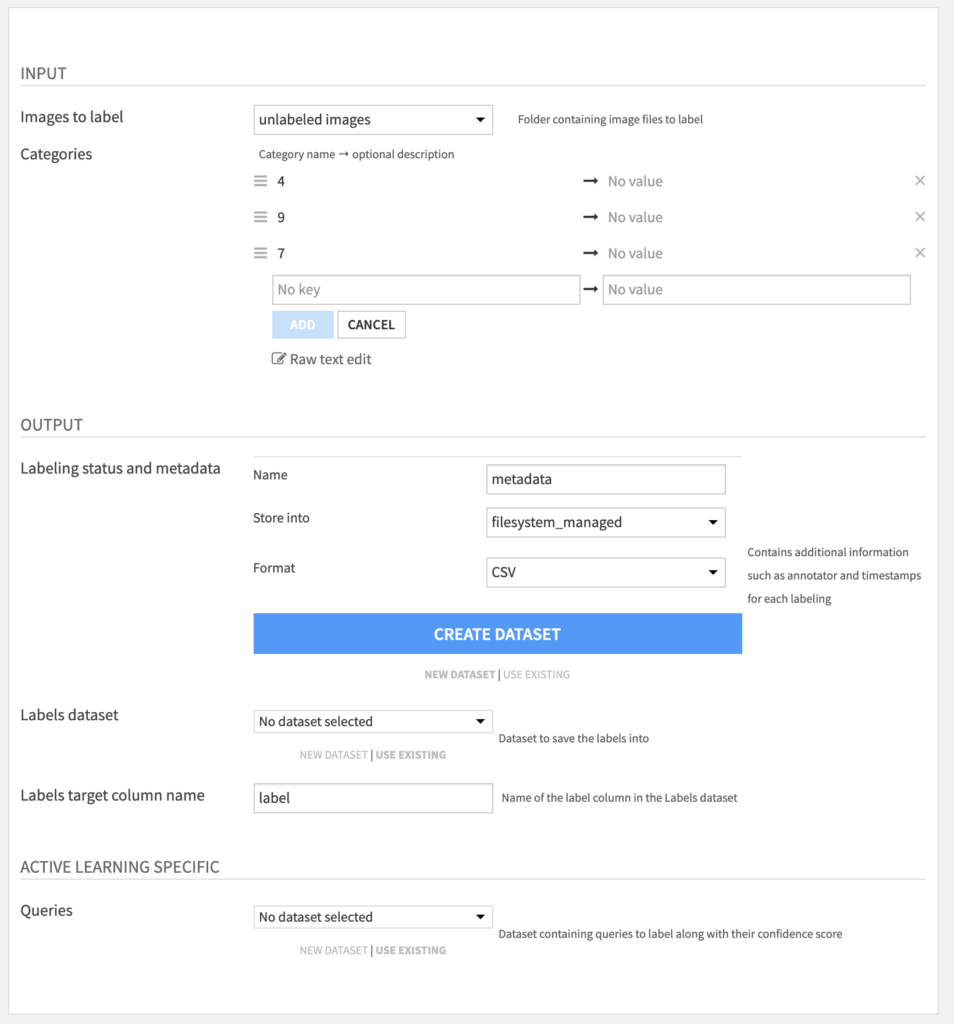
Images to label– managed folder containing unlabeled images.Categories– set of labels to be assigned to images.Labeling status and metadata– dataset name for the labeling metadata.Labels dataset– dataset to save the labels into.Label column name– column name under which the manual labels will be stored.Queries(optional) – dataset containing the unlabeled data with an associated uncertainty score.
Note that the latter queries dataset is optional as labeling can always be done without Active Learning. In this case the user will be offered to label samples in a random order.
Settings specific for Text Labeling
When you need to label entities in text, you can use the webapp Text Assisting Labeling. On this webapp, there are some extra parameters that will make your labeling easier and faster.

The available inputs are the following :
Activate prelabeling– whether you want prelabeling to be activated. Prelabeling will suggest labels on unlabeled data based on what you already labeled. It can highly speed up the process as you won’t have to relabel data that you already assigned. The current prelabeling engine will suggest prelabels based on what you already labeled. For example, if you labeled “John Snow” as a character, the next time you will see “John Snow”, it will be prelabeled as a character.Language– set here the language of the samples you want to label:- If all sample share the same language, choose one of the language proposed. If you do not see the language you are looking for, it is not yet supported, try to use the option
Custom... - If samples do not share the same language, you can add a column to your dataset containing the language of the sample. Languages must be written using ISO 639-1 language code. Once the column created, select the option
Detect language columnand select in the new field the column containing the languages - If you do not know the languages of sample, you can still select the option
Custom...`. It will display two new fields:
- If all sample share the same language, choose one of the language proposed. If you do not see the language you are looking for, it is not yet supported, try to use the option
Text direction– Specifies whether your text is a left-to-right language (Latin, Cyrillic, Greek…) or right-to-left (Arabic, Hebrew, Syriac…).Tokenization– Specifies how you want your text to be split out. Split over white space for white-space based languages (Latin, Cyrillic, Arabic…) or character when the language does not have any tokenization (Chinese, Japanese…)
3. Annotation process
After the webapp has started, the annotation process can start.
Note: For implementation purpose, in order to distinguish labeled samples from unlabeled in the tabular case, the webapp adds a column — called label_id by default — to the output dataset. This feature should not be used in any model.
For more details on the annotation WebApp, refer to the documentation.
Active Learning Recipe
When a sufficient number of samples has been labeled, a classifier from the DSS Visual Machine Learning interface can be trained to predict the labels, and be deployed in the project’s flow. In order to later used the Active Learning plugin, it’s required to use a python3 environment to train the model. Here’s a link describing how to create a new code environment in DSS . Make sure that it’s based on python3.
1. How to do Active Learning
Basically, here are the steps to do Active Learning :
- Train a classifier model on your already labeled dataset
- Thanks to the model you’ve just trained, get the uncertainty level for sample to label, using the Query Sampler recipe (+ Recipe > ML-assisted Labeling > Query sampler)
- Use the output dataset of the Query Sampler recipe in the
Queriesparameter of your Labeling Webapp. The samples with the higher uncertainty level will be displayed first in the Webapp.
For Active Learning on classification problem (on label per sample), you can use the following tutorial.
For Active Learning on object detection problem, you can use the following tutorial.
Active Learning is not available for Text Labeling.
2. Details on the Query Sampler methods
From the plugin, after the Query Sampler recipe is selected, the proposed inputs are:
Classifier Model– deployed classifier model.Unlabeled Data– dataset containing the raw unlabeled data.Data to be labeled– dataset containing the unlabeled data with an associated uncertainty score.
There is only one setting to choose from, the Active Learning strategy.
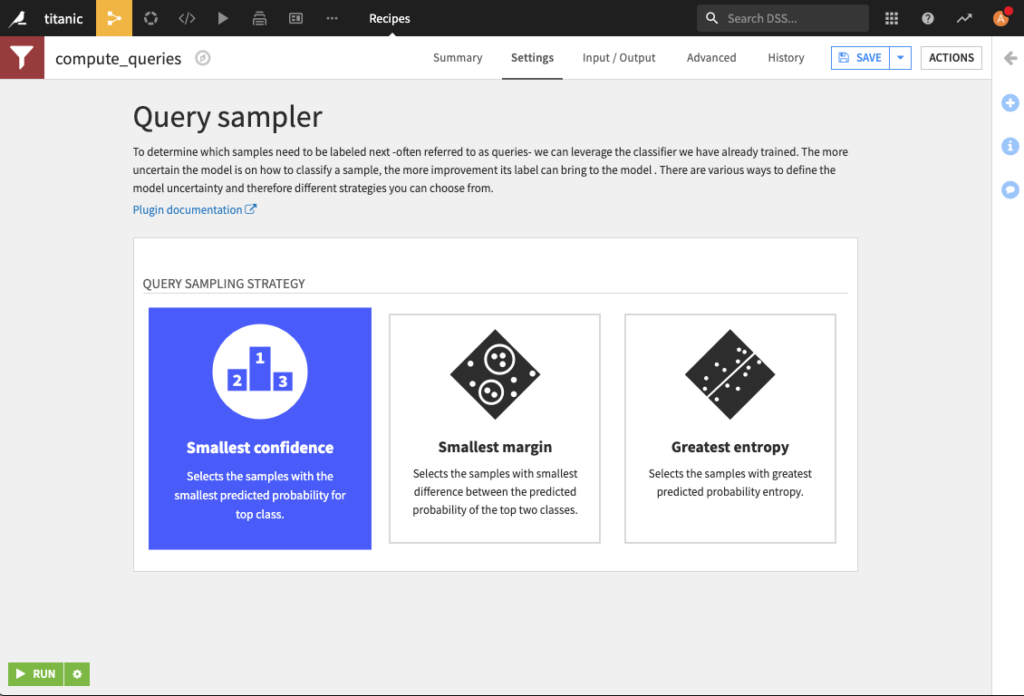
This plugin proposes the most common active learning strategies: Smallest confidence, Smallest margin, and Greatest entropy. Here are their definitions in the general multiclass classification settings with n classes. p^(i) denotes the ith-highest predicted probability among all n classes.
Note: In the binary classification case, the ranking generated by all the different strategies will be the same. In that case, one should therefore go with the Smallest confidence strategy that is the less computationally costly.
Smallest confidence
This is a confidence score based on the probability of the most probable class.
Smallest margin
This approach focuses on the difference between the top two probabilities:
Greatest Entropy
Shannon’s entropy measures the information carried by a random variable. This leads to the following definition:
In order to have an homogeneous output, this is normalized between 0 and 1.
Sessions
Tracking performance evolution is useful in an active learning setting. For this purpose, a session_id counter on how many times the query sampler has been ran so far is added to the queries dataset.
This session_id is then reported in the metadata dataset, output of the labeling webapp.
Active Learning Scenario
The Active Learning process is instrisically a loop in which the samples labeled so far and the trained classifier are leveraged to select the next batch of samples to be labeled. This loop takes place in DSS through the webapp, that takes the queries to fill the training data of the model, and a scenario that regularly trains the model and generates new queries.
To set up this scenario, this plugin proposes a custom trigger that can be used to retrain the model every n labelings. Here are the steps to follow to put in place the training:
- Create the scenario, add a custom trigger
Every n labeling.
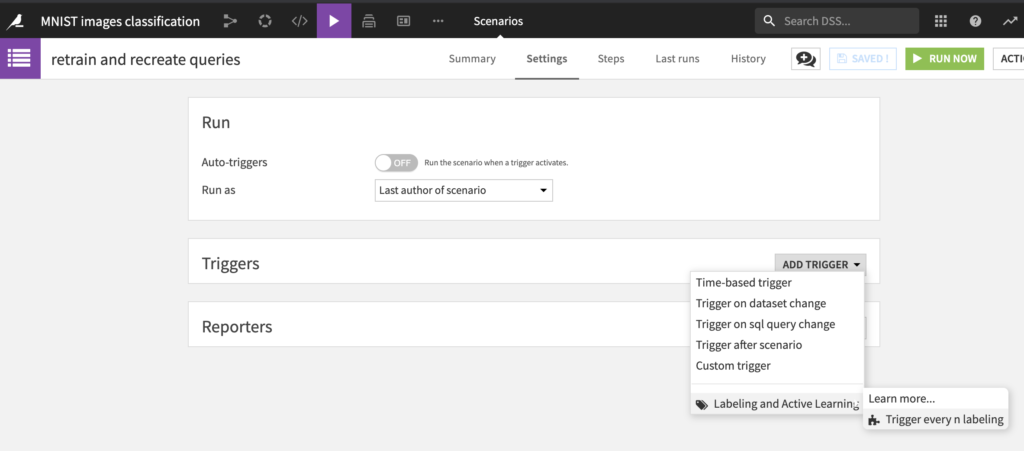
The following is then displayed:
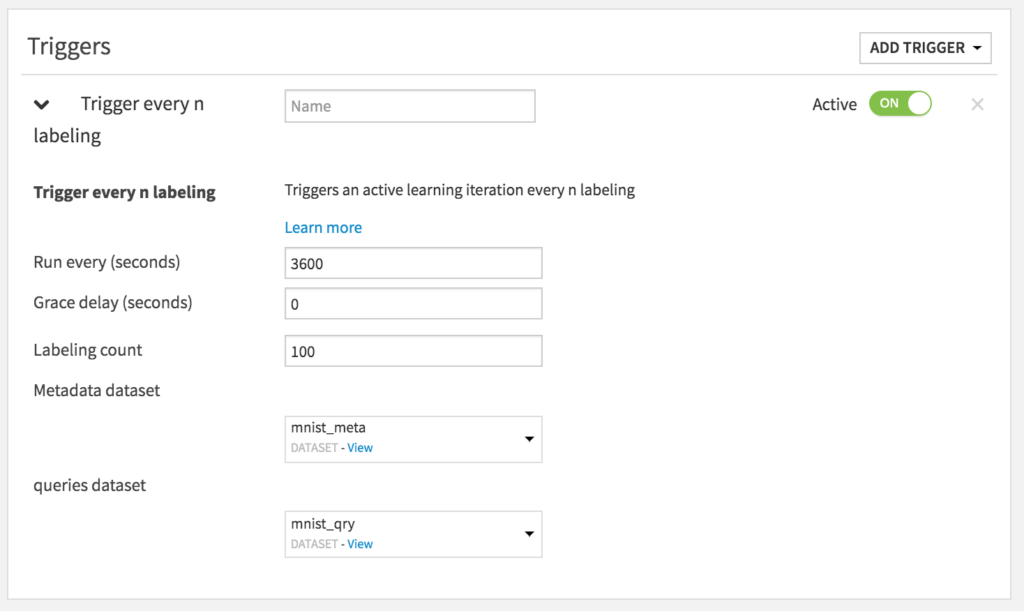
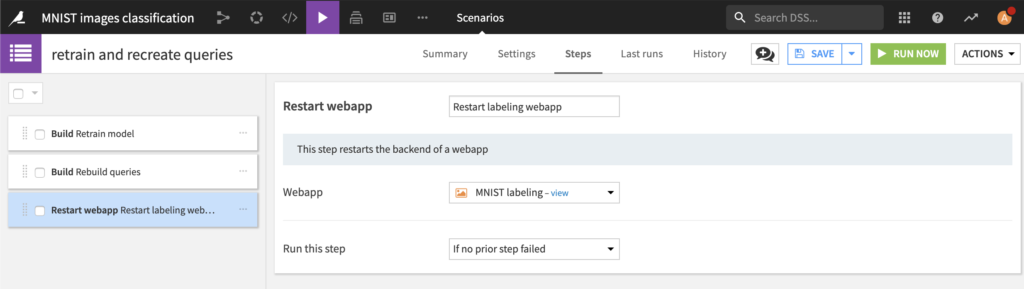
Last but not least, the following steps constitutes the full Active Learning scenario:
‘Reformat image annotations’ recipe for DSS Computer vision
Use this recipe to reformat your dataset and make it compatible with DSS computer vision (available from DSS 10.0).
How to use
Let’s assume that you have a Dataiku DSS project with a folder containing images & annotations from the labeling webapp.
To create your first ‘Convert object detection annotations’ recipe, navigate to the Flow, click on the + RECIPE button and access the recipe from there. If your folder is selected, you can directly find the plugin on the right panel.
Input
- A folder with images and object detection annotations from labeling webapp.
Output
- A dataset with two columns : images_annotations & images_path, compatible with object detection in DSS.

Settings
The recipe just needs to know the column name from your dataset which contains the annotations you want to reformat.