Plugin Information
| Version | 1.1.2 |
|---|---|
| Author | Dataiku (Hanna Julienne, Alex Reutter, Alex Combessie) |
| Released | 2015-11 |
| Last updated | 2025-05 |
| License | Apache Software License |
| Source code | Github |
| Reporting issues | Github |
Project Gutenberg is an open-source initiative to offer free ebooks for books that are no longer protected by copyright. It was created to encourage the creation and distribution of ebooks. Project Gutenberg basically contains all major works of literature.
This plugin lets you retrieve the complete content of books directly as DSS datasets, with one record per line in the book. This is a great plugin to get started with Natural Language Processing (NLP), i.e. processing human-written text.
How to set up
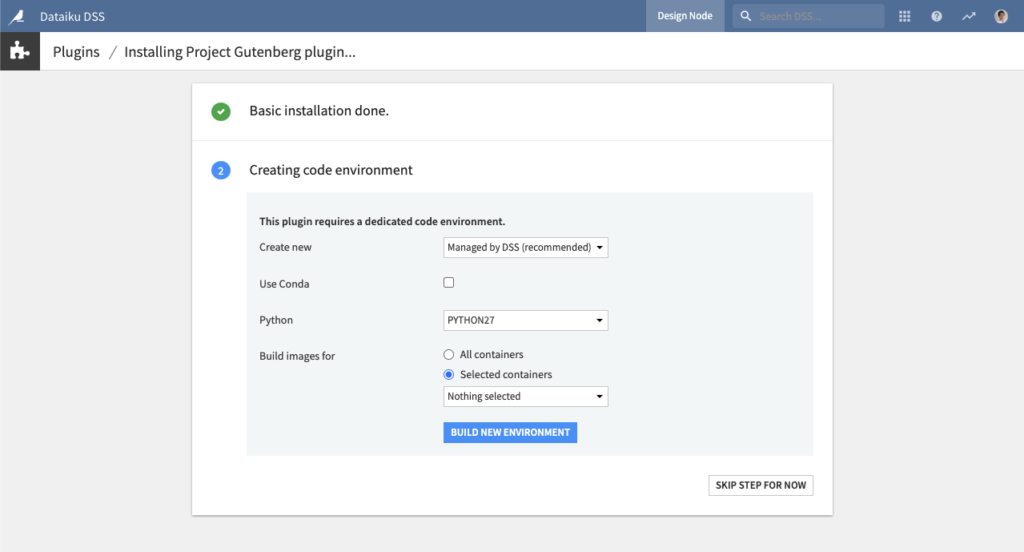
Right after installing the plugin, you will need to build its code environment. This plugin supports Python 2.7, 3.5, 3.6, and 3.7.
How to use
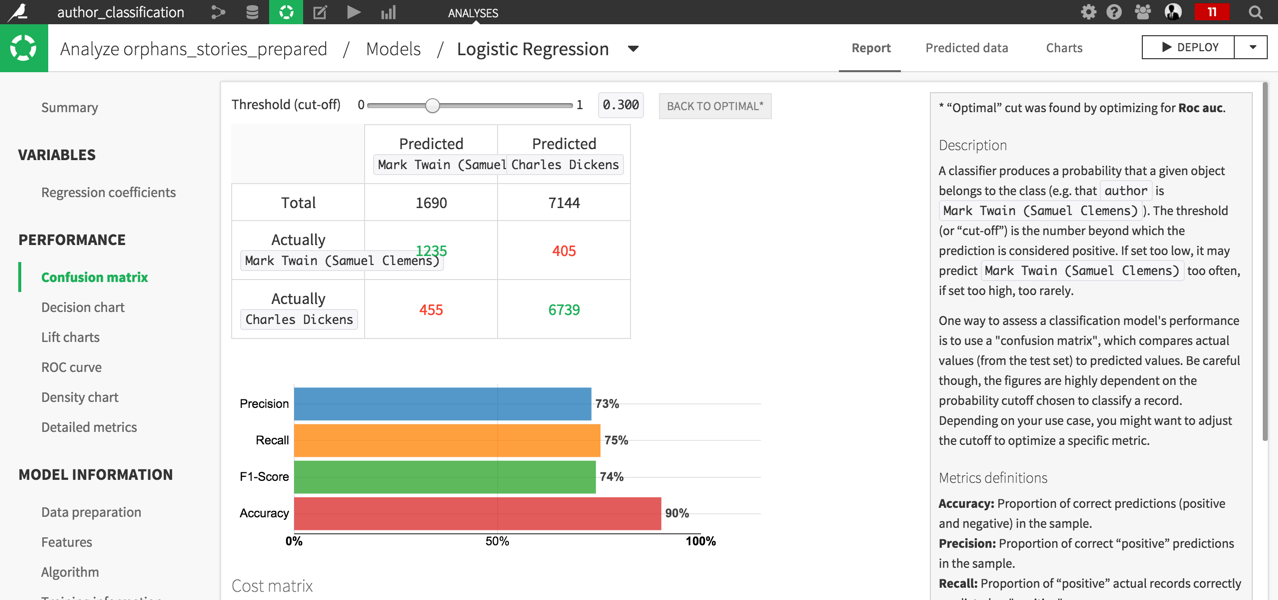
We have a great tutorial that uses this plugin to get you started on your first NLP predictive model: a service that automatically recognizes writings by Mark Twain and Charles Dickens.