




Plugin information
| Version | 1.0.0 |
|---|---|
| Author | Dataiku (Nicolas Monchy, Allan Francani) |
| Released | 2021-06 |
| Last updated | 2021-06 |
| License | Apache Software License |
| Source code | Github |
| Reporting issues | Github |
Snowflake stages are Snowflake objects pointing to a storage location. They are used to load and unload data from Snowflake, without passing credentials in the copy command.
This plugin is about unloading data from a DSS Snowflake dataset to a Snowflake stage.
Prerequisites
To use this plugin, the Snowflake stages need to be already created. This also applies to custom file formats if you wish to use any.
How to use
Let’s assume that you have installed this plugin and that you have a Dataiku DSS project with Snowflake datasets.
Export a dataset from the flow
- Select the dataset you want to export
- Click on Export to Snowflake stages at the bottom of the right panel
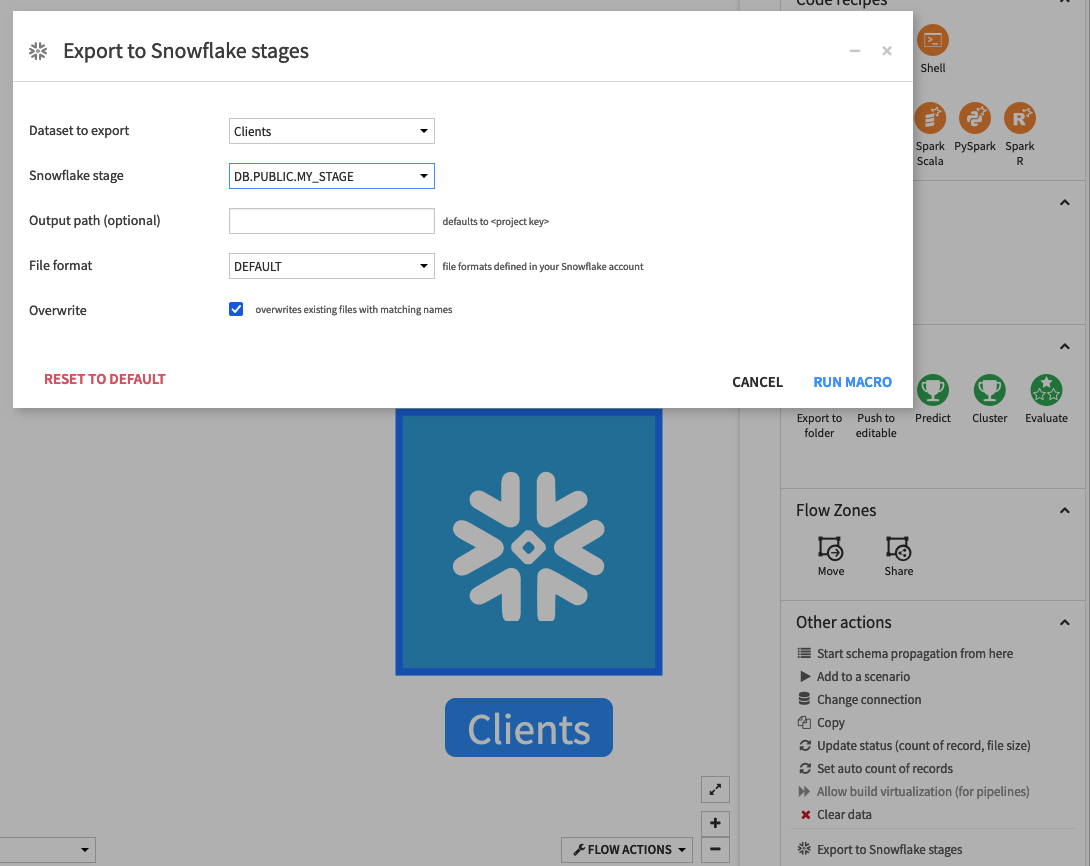
- Select the destination stage from the list
- If needed, customize the output path prefix (defaults to /<project key>)
- If needed, select a custom file format from the list
- Choose whether to overwrite potential existing files with the same name
- Click on RUN MACRO
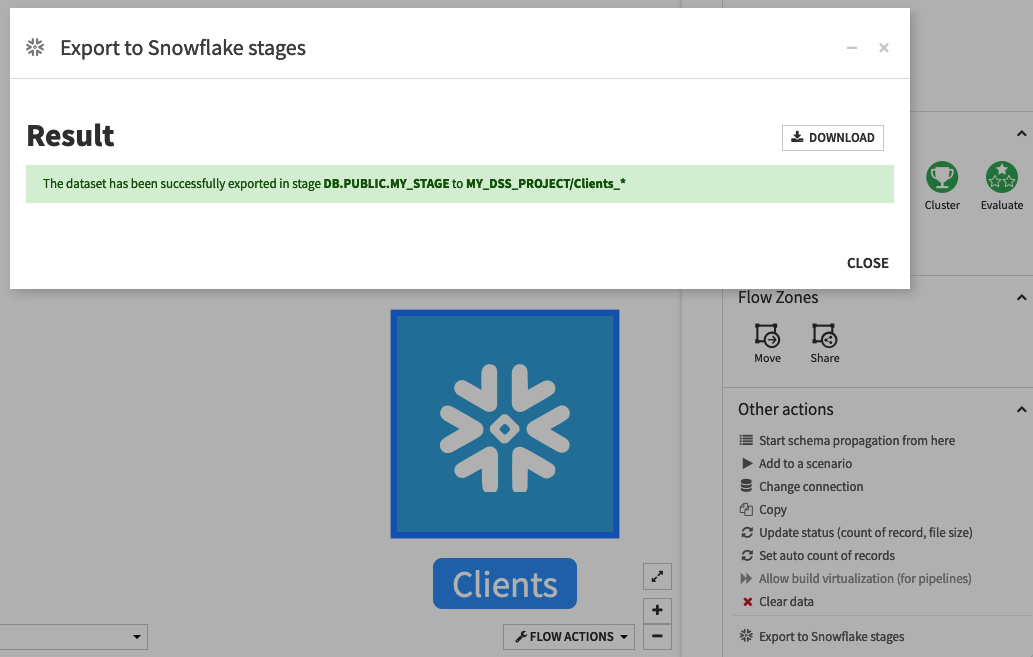
The name of the output file(s) is prefixed with the name of the dataset you exported.
Export a dataset from a scenario
- From a scenario, add a Execute macro step
- Select the Export to Snowflake stages macro
- Select the dataset to export
- All the other steps are similar to the previous section
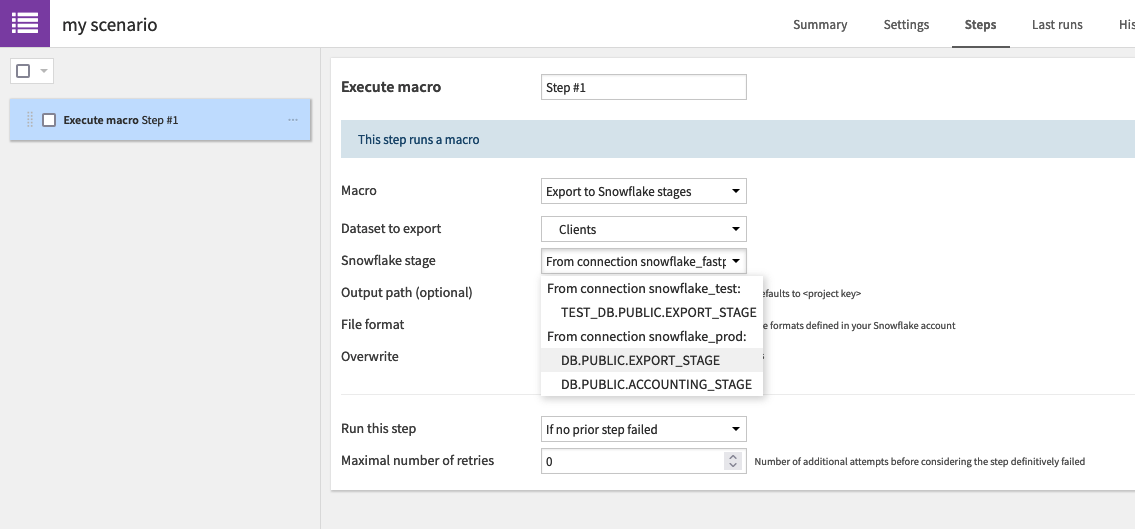
ℹ️ If you have multiple Snowflake connections in your project, make sure to select a dataset, a stage and a file format from the same connection.
Customize the output
Output path
By default, the output files are written to /<project key>/
This path will be replaced by any value that you enter. If you want to write the output files at the root of the stage, simply enter /
File format
Snowflake lets you create custom file formats. You may ask your Snowflake administrator to create new ones if needed. By default, the plugin will use the default file format of your connection.
Additional instructions are available in our Github repository.