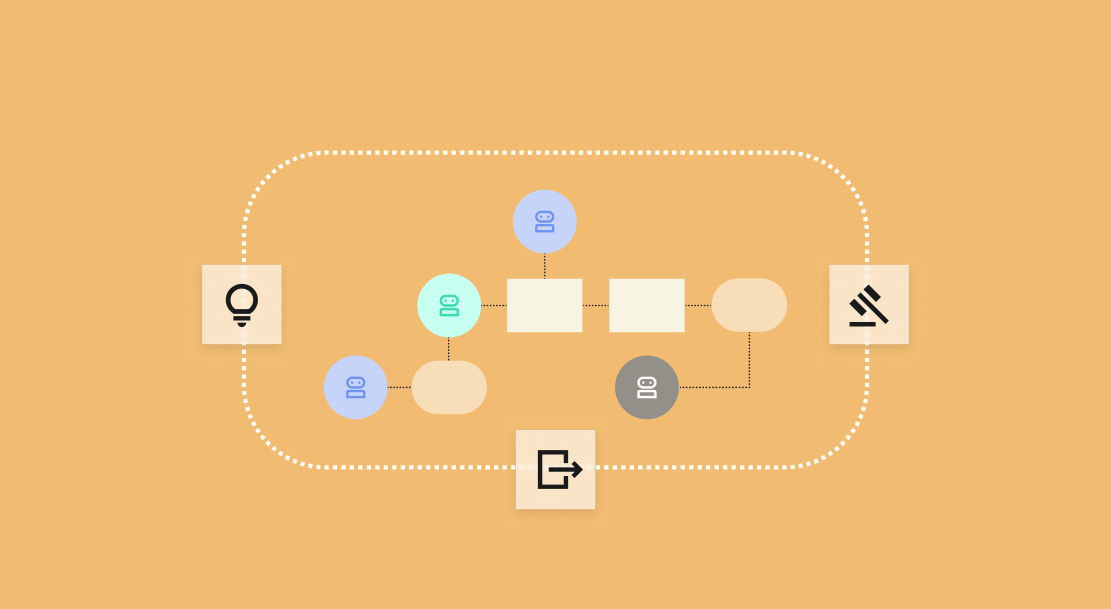
Big picture: How does the Kiji Inspector™ work?
Kiji Inspector™ follows a six-step pipeline that goes from raw model internals to human-readable explanations:
1. Contrastive pair generation: Synthetic pairs of user requests are created that share the same intent but require different tools. For example: "What is the latest version of Product X?" (requires file read) vs. "Set the latest version of Product X to v3.2.1" (requires file write). Same topic, different tool decision.
2. Activation extraction: The model processes each prompt, and Kiji Inspector™ captures the hidden-state activations at the exact decision token, the precise position in the output where the model commits to a tool choice. This is the neural "snapshot" of the decision-making process.
3. SAE training: A JumpReLU Sparse Autoencoder (SAE) is trained on those raw activations to decompose them into interpretable, monosemantic features, individual directions in the model's representation space that correspond to human-understandable concepts.
4. Contrastive analysis: The contrastive pairs are used as post-hoc statistical probes to determine which learned features are associated with specific tool decisions. The SAE itself is trained unsupervised; the pairs only help identify which features matter.
5. Feature interpretation: An LLM assigns human-readable descriptions to identified features and generates decision reports.
6. Fuzzing evaluation: A token-level A/B testing methodology (adapted from Eleuther AI's autointerp) validates whether the feature labels actually identify the correct tokens driving each feature, catching explanations that sound plausible but are wrong.
The result: You get a report that tells you which internal computational features drove the agent to pick a specific tool, grounded in the model's actual representations, not in a post-hoc narrative.

.png)
