
ディープラーニングについてより深く理解する
ディープラーニングの定義
人工知能(AI)の世界について学んでいく際、時には混乱を招くような専門用語によって、その複雑さが増していくことに気づくでしょう。AIは、機械学習(ML)やディープラーニングといった用語と一緒に使われたり、時には同じ意味で使われたりすることがあります
ディープラーニングのようなトピックに踏み込むためには、まずその定義を行い、そのうえで次のような内容を理解する必要があります:
- ディープラーニングと関連するAIの概念(生成AIを含む)との違い
- ディープラーニングを使うべき場合と使うべきではない場合
- ディープラーニングを考える際、教師あり学習と教師なし学習についても学ぶことが重要な理由
- 機械学習およびディープラーニングの導入をDataikuがどのように支援できるのか
ディープラーニングとは何か?ディープラーニングと人工知能の違いは何か?ディープラーニングは生成AIや強化学習とどのように関連するのか?
簡単に言えば、ディープラーニングは機械学習の一部であり、機械学習は人工知能の一部です。ディープラーニングはまた、生成AIの構成要素でもあります:大規模言語モデル(LLM)は生成AIの一種であり、またトランスフォーマーネットワークの一種です。そしてトランスフォーマーは、特殊なディープラーニングのアーキテクチャーです。さらに簡単に言えば、LLMはディープラーニングの手法を用いたアルゴリズムです。したがって、ディープラーニングは単にAIの一種であるだけでなく、生成AIの根幹とも言えるものなのです。
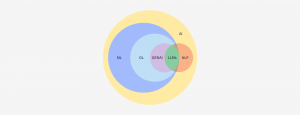
ディープラーニング:その何が特別なのか?
線形回帰やロジスティック回帰、ランダムフォレスト、勾配ブースティングといった従来の機械学習アルゴリズムは、基盤となる統計的手法を利用して、ラベル付きのトレーニングデータから反復的に学習を行うことで、特定の予測やクラスタリングタスクの実行を可能にします。通常、このアプローチでは、データサイエンティストやドメインの専門家が手作業によりモデルが使用する特徴量(変数)を抽出、設計、そして選択する必要があり、これは機械学習プロジェクトにおいて、とくに時間のかかる工程となっています。
ディープラーニングは、機械学習の中でもより新しく専門的な分野であり、多層構造のニューラルネットワーク(一般的に”ディープニューラルネットワーク”と呼ばれる)を用いて、データ内の複雑なパターンをモデル化します。一般的なディープニューラルネットワークのタイプとしては、畳み込みニューラルネットワーク(CNN)、再帰型ニューラルネットワーク(RNN)、トランスフォーマーネットワークなどがあります。
従来の機械学習モデルとは対照的に、ディープラーニングモデルはローデータから直接特徴を抽出するための対応を自動的に学習できるため、手作業による特徴量設計の必要性が減り、テキスト、画像、動画、音声などの非構造化データを扱うアプリケーションにおいて非常に大きな威力を発揮します。ディープラーニングモデルは、画像や音声認識、自然言語処理(NLP)、複雑なゲームプレイなどのタスクに向け優れたものとなっており、従来の機械学習手法を上回る性能を発揮することがありますが、一方でより複雑かつ計算処理の負荷が高く、通常は大量のトレーニングデータとGPUのような専用ハードウェアを必要とします。
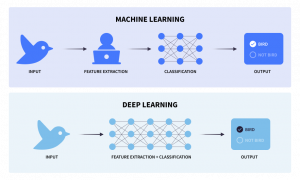
言うまでもなく、より複雑なデータを扱うということは、より複雑なアルゴリズムが必要になるということを意味します。そして、複雑なデータから十分に一般化された複雑なパターンを抽出するためには、機械学習モデルよりもはるかに多くのサンプルが必要になります。ディープラーニングモデルをゼロからトレーニングする場合、通常、目安としては数万から数百万枚のラベル付き画像が必要になります。
ディープラーニング vs 機械学習
ディープラーニングが登場したからと言って、旧来の機械学習モデルが捨て去られるわけではありません。構造化された表形式データのみを扱う多くの旧来型予測タスクについては、依然としてシンプルで計算量も少ない機械学習のアプローチの方が適しています。
例えば、次のような簡単な例があります:マンハッタンからブルックリンへ行く際には、歩くべきか、それとも飛行機で行くべきか?この最終的な判断は、コストや時間と得たい成果とのシンプルなトレードオフによって決定されます。マンハッタンからブルックリンまで飛行機で行くという行為は、”単純な”問題にディープラーニングモデルを使うようなものです。言い換えれば、この特定の問題に対しては、まったく効率的ではないのです!
ディープラーニング vs 生成AI
ディープラーニングと生成AIは密接に関連しており、ディープラーニングは生成AIの稼動を可能にする基盤技術となっています。多階層のニューラルネットワークを備えたディープラーニングは、大規模なデータセットから複雑なパターンを学習するという用途で優れた性能を発揮します。
生成AIでは、敵対的生成ネットワーク(GAN)やトランスフォーマーアーキテクチャー(GPTのような)などのディープラーニングモデルが使用され、既存のデータを使ってトレーニングすることで、新たにテキスト、画像、その他のデータを生成します。本質的にディープラーニングは、高度なモデルアーキテクチャーの基盤を提供することで、生成AIが現実的で革新的なアウトプットを生み出せるようにしています。
ディープラーニング vs 強化学習
ディープラーニングと同様に強化学習もまた機械学習の一分野であり、エージェントが累積報酬を最大化する行動を実行することで意思決定について学習します。エージェントはシステム環境と相互にやり取りを行い、報酬やペナルティという形でフィードバックを受け取り、そのフィードバックに基づいて行動を調整します。一般的な例としては、ゲームプレイがあります。
強化学習はディープラーニング(いわゆる深層強化学習)とやり取りを行い、深層ニューラルネットワークを利用してポリシーや価値関数を表現します。これは、従来の強化学習手法では対応が難しい自律走行やビデオゲームのような、複雑で高次元の状態空間や行動空間を持つ環境においてとくに大きな価値を発揮します。上述のとおり、ディープラーニングのアルゴリズムでは、手作業で特徴量の設計をする必要なく特徴の抽出が行えるため、画像のピクセルや音声などの生の感覚入力を扱う場合にも深層強化学習が有効となります。
ディープラーニングを使うべき場合、使うべきではない場合
ディープラーニングは急速に普及しており、とくに人工ニューラルネットワークの分野で大きなブレークスルーがあったため、さまざまな業界の企業がAI戦略の一環としてディープラーニングソリューションを導入するようになっています。
カスタマーサービスのチャットボットから、小売業における画像や物体認識まで、ディープラーニングは数多くの洗練された新しいAIアプリケーションの可能性を開花させました。すでにそのチャンスと可能性は明らかですが、ディープラーニングは常に最適な選択肢となるのでしょうか?
膨大な量のデータを必要とする複雑なタスクにおけるディープラーニングアルゴリズムの卓越した性能と、一般に公開されているデータを用いた事前学習済みモデルの増加により、多くの組織にとってディープラーニングは、とくに魅力的な存在となっています。しかし後述するように、ディープラーニングがすべてのビジネス問題の解決策になるわけではありません。
では、ディープラーニングが必要な場合と、そうでない場合をどう見極めればよいのでしょうか?それぞれのユースケースは固有なものであり、特定のビジネス目標、AIの成熟度、スケジュール、データ、リソースなど、さまざまな要素に依存します。以下は、特定の問題の解決に向け、ディープラーニングを使うかどうか決定する前に熟慮すべき、4つの一般的なポイントです。
1:課題はどの程度複雑か?何を予測または発見しようとしているのか?
ディープラーニングの主なメリットのひとつは、データの中に隠れたパターンの発見や、多数の相互依存する変数間での関係把握が必須となる、複雑な問題を解決することができる点です。ディープラーニングのアルゴリズムでは、データから自動的に隠れたパターンを学習し、それらを組み合わせて、より効率的な意思決定ルールを構築することができます。
画像分類、自然言語処理(NLP(英語))、音声認識など、多くの場合非構造化データを扱う必要がある複雑なタスクにおいて、ディープラーニングはその真価を発揮します。
より単純で明確な特徴量エンジニアリングが中心であり、非構造化データの処理を必要としないタスクであれば、旧来の機械学習のほうが適している場合もあります。
2:モデルの成功をどのように評価するか?正確性と解釈可能性はどの程度重要か?
ディープラーニングでは、特徴量抽出に関わる対応の多くをアルゴリズムが自動的に行うため、人手による特徴量エンジニアリングの手間が軽減されますが、その一方、モデルが何をしているのかという内容を人が理解、解釈することがより困難になります。実際に前述のとおり、解釈可能性はディープラーニングにおける最大の課題のひとつなのです。
通常、どのような機械学習モデルを評価する場合でも、精度と解釈性の間で基本的なトレードオフが発生します。そして、これこそが説明可能なAI(Explainable AI(英語))における課題の根幹なのです。ディープネットワークは、多くの分野で旧来の機械学習手法をはるかに凌駕する精度を達成してきましたが、一方で非常に複雑かつ非線形性が高く、入力間の相互作用をモデル化しているため、その解釈はほとんど不可能となっています。
しかし旧来の機械学習では、特徴量エンジニアリングがダイレクトに行われ、線形/ロジスティック回帰や決定木といった、より解釈性の高いアルゴリズムが利用可能で、データサイエンティストが活用できるツールや分析手法も増えているため、モデルの内部で何が起きているのかを容易に理解および解釈することができます。
3:そのソリューションにどれだけの時間とリソースを割くつもりなのか?
利用しやすくなったとはいえ、実際のところディープラーニングは依然として複雑でコストのかかる取り組みです。ディープラーニングモデルは、その本質的な複雑さ、レイヤー数の多さ、必要なデータ量の多さなどから、トレーニングには非常に長い時間がかかり、また多くの計算能力が必要であり、膨大な時間とリソースを消費するものとなっています。
2024年のAIの動向においてDataikuが注目した(英語)のは、事実上、ディープラーニングアルゴリズムの実行にはグラフィックプロセッシングユニット(GPU)が必須になったという事実です。GPUは非常に高価ですが、複雑なモデルをトレーニングする際の計算量やメモリ需要を背景に、大規模なディープラーニングプロジェクトでは、GPUが実現するハードウェアアクセラレーションや分散または並列化されたトレーニングプロセスがほぼ不可欠となっています。
大規模なデータセットを扱ったり、アンサンブル手法を使ったりするような、ある種の旧来型機械学習タスクのトレーニングをGPUや並列化によって高速化することは可能ですが、多くの従来型機械学習のタスクでは、必ずしも分散トレーニングを必要としない場合があります。旧来の機械学習アルゴリズムであれば、最高性能のハードウェアを用意しなくても、十分な性能のCPUだけで普通に学習させることが可能です。計算コストがそれほど高くないため、組織はより短期間で繰り返し試行したり、さまざまな手法をテストしたりすることができます。
4:ラベル付きデータの品質は十分か?
ディープラーニングの主な強みのひとつは、より複雑なデータタイプや関係性を把握できる点ですが、同時にこれは、使用されるアルゴリズムがより複雑であることも意味します。繰り返しになりますが、教師あり機械学習やディープラーニングを「モデルが正解を推測しているだけ」と断定しないことが重要です。
データから潜在的なパターンを抽出するためには、非常に多くのラベル付きサンプルを用意する必要があります。通常、事前学習済みモデルをファインチューニングする場合でも数万件、ゼロからモデルを学習させる場合には数百万件ものラベル付きデータが必要になります。
十分な量の正確にラベル付けされた高品質なデータが揃っていなければ、いくつかのビジネスケースでは、期待外れの結果になるというリスクがあります。組織は、データの整理、準備、ラベリングにおいて課題に直面しており、担当チームはこれらのプロセスによって膨大な時間やリソースを浪費しています。しかし本来、このような時間やリソースは、次期の機械学習モデル構築やモデルの本番環境への展開にあてるべきものなのです。
これらすべての検討事項を、後で参照できる便利なセクションとして以下にまとめました:

特定のデータプロジェクトにおいて、旧来型の機械学習を選択するか、ディープラーニングを選択するかに関わらず、共通するのはプロセスのあらゆる段階で人の介入、評価、意思決定が必要となる点です。このように人がループに組み込まれた拡張インテリジェンスこそが、真に責任ある透明性の高いAIを実現する鍵となるのです
では、ディープラーニングは教師あり学習なのか、それとも教師なし学習なのでしょうか?注:どちらにもなり得ます。例えば、CNNを使った画像分類は教師なしディープラーニングタスクです。
対照的に、オートエンコーダーを使った異常検知は、教師なしディープラーニングのタスクの一例です。次のセクションでは、典型的な”どちらか一方の例”をいくつかご紹介します。
Dataikuによるディープラーニング
ここまでの各セクションで、段階的にディープラーニングへの理解を深めてきた。現時点では十分な情報が揃っていますが、さらなる支援がなければ、実際にすべてを実践することが難しくなる場合もあります。
そのような場合、Dataikuによるご支援が可能です。
ディープラーニングについて少し理解が深まった今こそ、その実際の活用方法を調査し、探求し始める好機なのです。Dataikuは、AIが持つ可能性や性能を皆様の手に委ねるためのプラットフォームであり、そこにはディープラーニングへの取組みを始めるための素晴らしい機会が数多く存在します。
AutoMLによるノーコードソリューションから、完全にカスタマイズ可能なフルコードでのモデル構築まで、Dataikuでは、機械学習やディープラーニングの構築プロセスに多くの人々を容易に参加させることができます。モデルの説明可能性と解釈可能性を高めるための各機能により、モデルの結果をより深く理解し、さまざまな変数がモデルのパフォーマンスに与える影響を把握し、結果についても積極的に監視することができます。

あらかじめ用意されたAutoMLテンプレートを使用することで、コーディングする必要なく、画像分類や物体検出といった高度なディープラーニング手法や、時系列予測や因果予測といった専門的な機械学習にも簡単に取り組むことができます。
この最後のセクションでは、データのラベリングから、ビジュアル機械学習やコードノートブックを使った最初のモデルの構築、さらには転移学習でプロセスを加速するところまで、あらゆる側面について解説します。すぐにディープラーニングを開始したい皆様は、こちらのDataikuのチュートリアルをチェックすることで、最初のモデル構築(英語)や、NLP(英語)またはビジュアルディープラーニング(英語)を体験いただけます。
コーディングも可能なビジュアル機械学習
Dataikuは、コンピュータービジョンのような事前に定義されたユースケース向けに、ビジュアルでノーコードのディープラーニングテンプレートも提供していますが、カスタムのタスクではローコードのアプローチのほうがニーズに合致する場合もあります。このアプローチでは、ディープラーニングのアーキテクチャーを定義したり、カスタムのデータ前処理や拡張を行ったりするために、多少のコーディングスキルが必要になりますが、それ以外はDataikuが対応します。
特徴量の取り扱いやハイパーパラメータ探索の最適化から、モデルの展開やスコアリングまですべてを、Dataikuで作成および管理された他のモデルと同じように取り扱うことができます。ディープラーニングモデルは非常に多くの計算リソースを必要とするため、Dataikuでは、CPUから複数のGPU、さらにコンテナデプロイメント機能によるトレーニングもサポートしています。クラウド対応のダイナミックGPUクラスター上で、モデルを簡単にトレーニングおよび展開することができます。
フルオンコードマスター
次に紹介するのは、Dataiku内での無制限のコーディング機能です。夢にまで見たオリジナルのディープラーニングモデルを、思う存分コーディングして構築するための準備を開始しましょう。Dataikuでは、ビジュアル機械学習機能に搭載されたアルゴリズムに縛られることなく、これらの対応を進めることができます。PythonやScalaを使って独自のモデルをコーディングすることも、また先ほど紹介したビジュアル機械学習機能からスタートし、独自のニーズに合わせてカスタマイズしながらモデルを構築することも可能です。Keras、TensorFlow、TensorBoardなど、あらゆるツールが揃っており、まさに利用者の皆様の可能性は無限です!
最新かつ最高のディープラーニングアルゴリズム、ライブラリ、さらに環境に関する充実したサポートを受けることができます。さぁ、コーディングを開始しましょう!
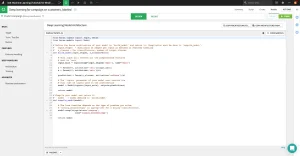
機械学習アシストによるラベリング
新しくモデルをトレーニングする場合でも、また事前にトレーニング済みモデルをファインチューニングする場合でも、アルゴリズムにタスクの実行方法を学習させるためには大量のラベル付きデータが必要であり、その用意には大きな手間がかかります。しかし、仮に皆様がラベルデータをお持ちでない場合でもご心配は無用です!
Dataikuは、担当チームが表形式、テキスト、画像ベースのデータセットに効率的にラベリングできるよう、管理されたラベリングレシピを内蔵しており、データアノテーションの取り組みを効率化します。例えば下の画像は、ラベリング担当者がより大きな画像の中で特定のオブジェクトを検出する方法をモデルに教えるために、興味のあるクラスを示すバウンディングボックスで画像に注釈を付ける様子を示しています。
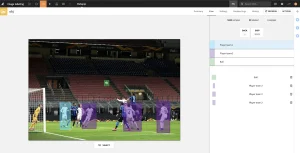
モデルの学習プロセスにおいてもっとも情報量の多いサンプルを優先的にラベリングするアクティブラーニング手法を導入することもできます。対象となるのは、モデルの予測確度がもっとも低いレコード、入力空間のあらゆる領域をカバーする多様性のある観測データ、そしてデータ分布全体を代表する汎化性能の向上が期待できるレコードなどです。
アクティブラーニングが有効なのは、ラベル付けにかかるコストや労力を最小限に抑えながらモデルの性能を向上させることができるからであり、とくにラベル付けされたデータが不足している場合や、入手に多大なコストがかかる場合に大きな付加価値となります。
より詳細な内容へ
ディープラーニング革命の一翼を担う
ここまで、ディープラーニングの定義、ディープラーニングとAIなどの他の概念との違いや共通点、ディープラーニングの利用を検討するタイミング、教師あり学習と教師なし学習の違いを理解すべき理由、さらにDataikuの提供ソリューションが機械学習やディープラーニングのソリューション実装にどのように役立つかを説明してきました。
機械学習、ディープラーニング、AIのいずれを定義するにしても、すべてに共通する根本的な原則は、人間主導であるべきだという点です。真に責任ある透明なAIを実現する鍵は、皆様のような人の知性を組み込むことなのです。
現在、”エブリデイAI(Everyday AI)”は最大の注目を集め、データサイエンス分野に熱狂をもたらしていますが、真に意味のある影響力を発揮するためには、AI導入における責任あるミッションとビジョンを確立し、継続的に教育を行うことが極めて重要となります。