
MLOpsの解読:キーコンセプトと実践に関する解説
MLOpsとは?
将来を見据えたAI戦略には、本番環境でモデルを展開、監視、再トレーニングするための仕組みが不可欠となります。さらに、変化する状況に適応するために、新しいモデルを迅速にテスト、トレーニング、実装するための仕組みも備えていなければなりません。これらの役割を担うのがMLOpsです(生成AIの領域ではLLMOpsと呼ばれる場合もあります)。従来の機械学習(ML)モデルを扱う場合でも、大規模言語モデル(LLM)を扱う場合でも、基本的な概念は同じです。
MLOps(機械学習オペレーションの略)は、機械学習のワークフローに対してDevOpsの手法を適用するための分野と言えるでしょう。ここには、本番環境で機械学習ワークフローやモデルを効率的かつ確実に開発、展開、監視、管理するために必要なプロセスとツールが含まれています。
MLOpsの中核となる概念が、継続的インテグレーションと継続的デプロイメント(CI/CD)です。CI/CDは、コードの統合、テスト、展開のプロセスを自動化することを目的としたソフトウェア開発手法です。
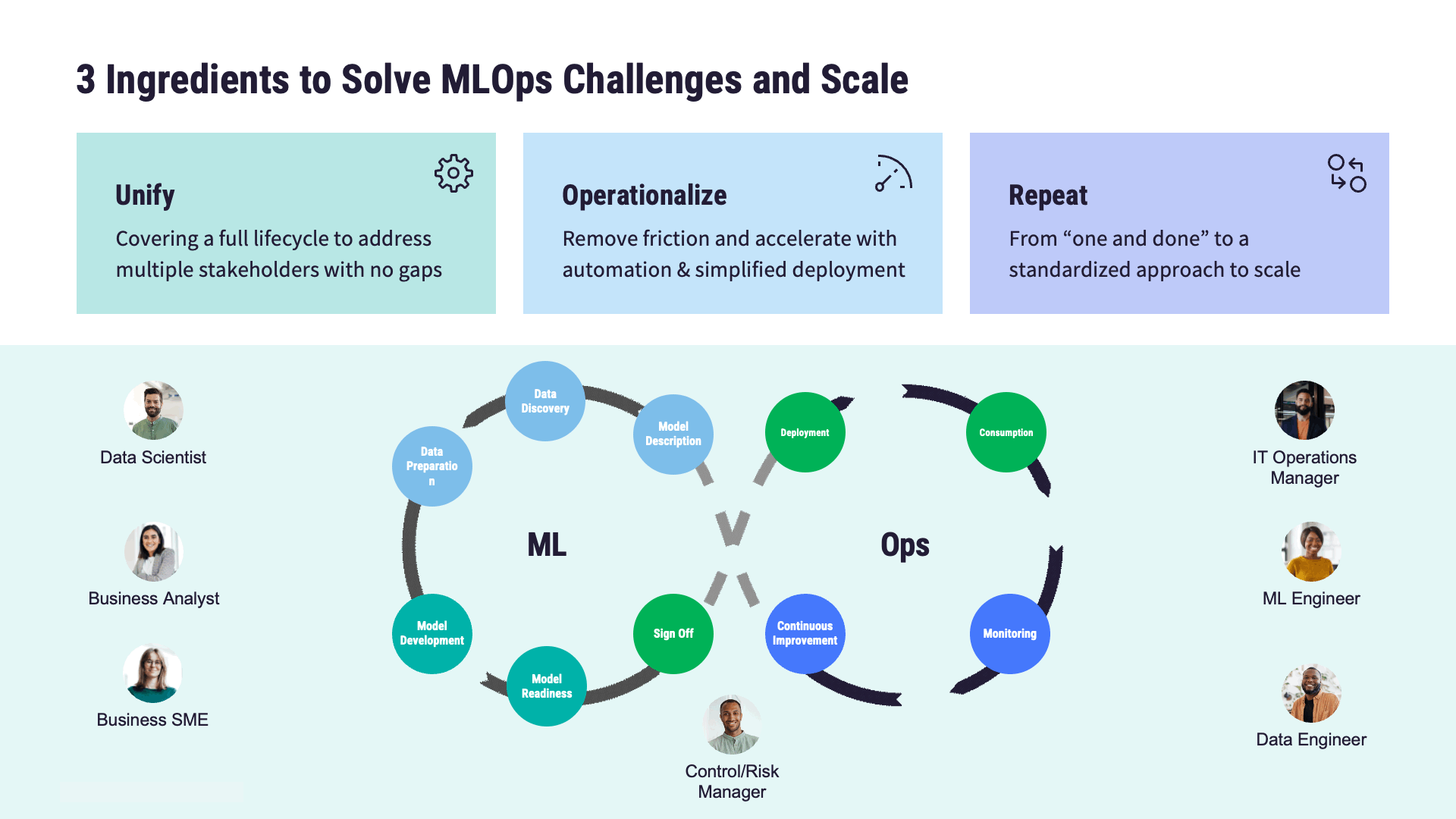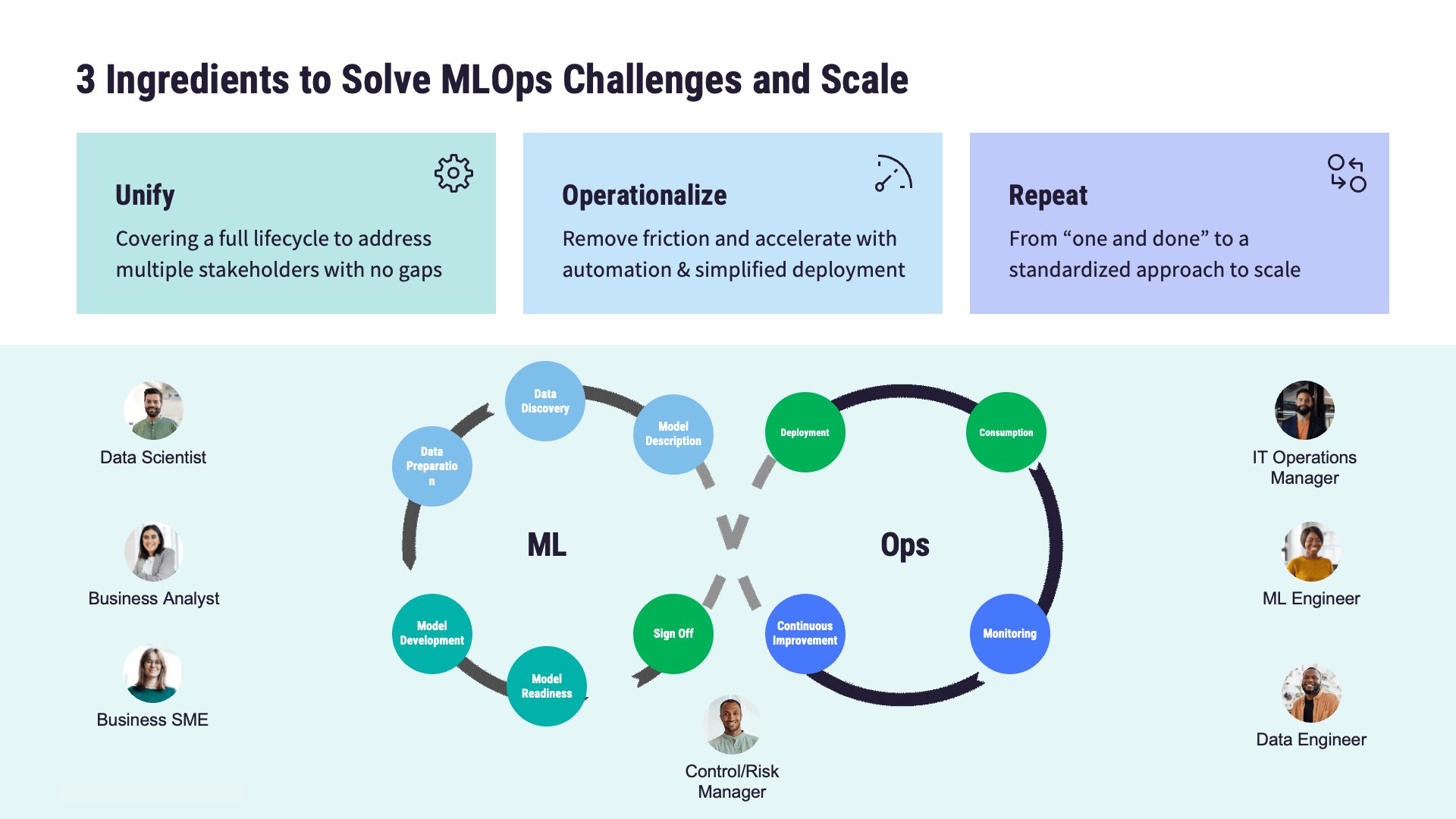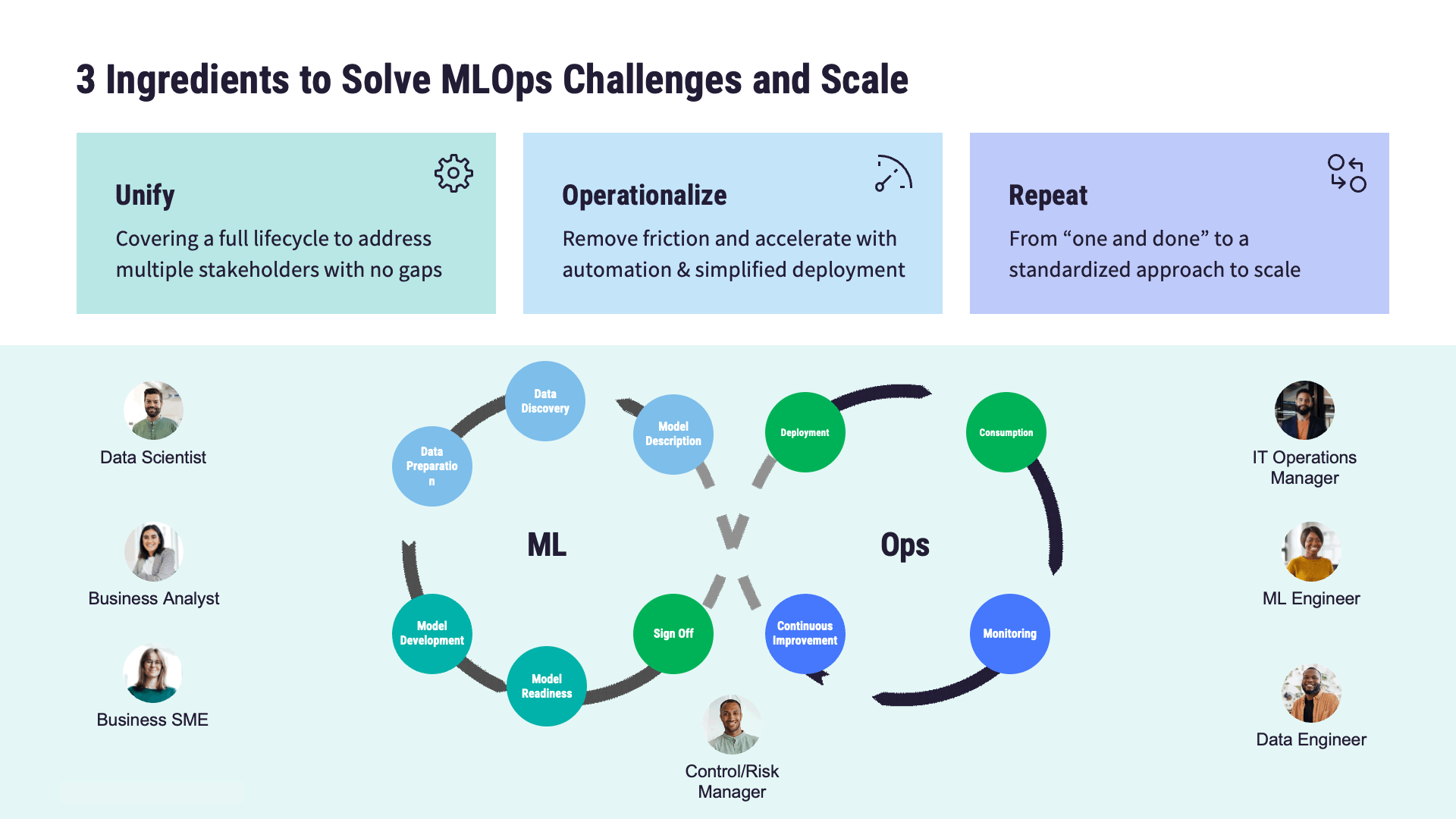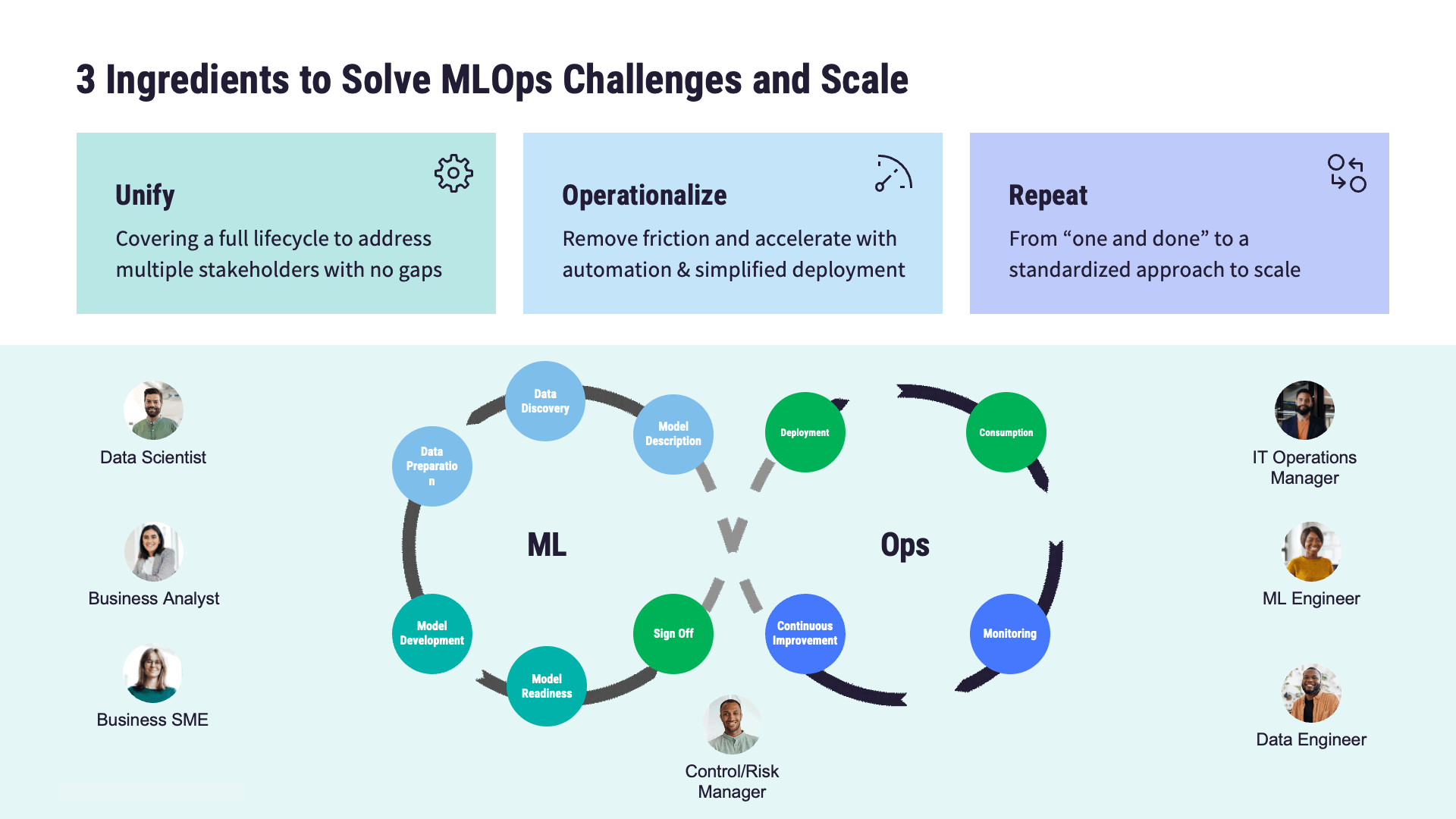
MLOpsの主要コンポーネント紹介
モデルの開発から展開、そして保守に至るまでの過程には、次のような課題がともないます:
- スケーラビリティー: 大規模なMLモデルのMLOpsライフサイクル管理。
- 信頼性:展開されたモデルの一貫したパフォーマンスおよび信頼性の確保。
- ガバナンス:規制遵守、倫理的配慮、データプライバシーに関する懸念への対応。
- コラボレーション:データサイエンティスト、機械学習エンジニア、ビジネス関係者間での共同作業の促進。
MLOpsでは、標準化されたプロセス、MLOpsのベストプラクティス、そして自動化技術を確立することで、これらの課題に対応します。最終的な目標は、機械学習モデルにおけるライフサイクル全体の効率化です。この一連の対応における主要な工程、つまりMLOpsアーキテクチャーの重要な構成要素には、以下のようなものがあります:
モデルの開発
モデルの開発は、データを実用的なインサイトに変えるための要となるプロセスです。このプロセスには、従来の機械学習モデルだけでなく、大規模言語モデル(LLM)の開発も含まれています。MLOpsにおけるモデルの開発は、予測分析モデルのトレーニングから生成AIの創造的な可能性の探求まで、幅広い手法を網羅しています。
従来の機械学習モデルの開発では、データの前処理が重要な役割を果たします。前処理には、高度なデータ運用プラットフォームが提供する機能(データへのアクセス、結合、クレンジングなど)だけでなく、データセットの形状変更、非構造化テキストや画像の数値ベクトルへのエンコード、カテゴリカル値をダミー変数に変換するなど、モデル学習に適した形式にデータを整えるためのより専門的なデータ変換機能も含まれます。
次工程には特徴量エンジニアリングがあり、データサイエンティストはドメイン知識や特殊な手法を活用して、データ内の重要なパターンを把握します。さらにデータサイエンティストは、準備したデータに機械学習を適用し、与えられたタスクにもっとも適したモデルを特定します。ハイパーパラメータチューニングは性能を最適化し、精度(accuracy)、適合率(precision)、再現率(recall)などの評価指標はモデルの有効性を評価します。
多くの場合、LLMの開発では生成されたコンテンツの品質や創造性を評価するために、人間の評価担当者による定性的な評価が行われます。データサイエンティストは、オープンソースモデルやセルフホスト型モデル、あるいは異なるプロバイダーのモデルなど、さまざまなLLMを活用する場合があります。開発における最終的な目標は、目の前のタスクに対して最適となるモデル(例えば、もっとも高性能で低コストのモデル)を見つけ出すことです。
モデルの展開
モデルの展開(デプロイ)は、実験的なモデルから、本番環境で実際のデータを処理する実用的なソリューションへの移行を意味します。データサイエンティストが適切なモデルを構築または選定した後、次のステップとなるのが展開です。この目標は、モデルを継続的に運用して、ビジネスのワークフローへ統合することです。
MLOpsは、自動化された展開パイプライン、コンテナ化、オーケストレーション技術に重点を置くことで、このプロセスを合理化するとともに、多様なインフラ環境でのシームレスで再現可能なモデルの展開を促進します。
自動化された展開パイプラインは、MLOpsにおける効率的なモデルのデプロイメント基盤になります。これにより、組織は機械学習モデルのパッケージング、テスト、展開のプロセスについて、大規模な自動化を図ることができます。開発から本番環境へのモデルの移行が、これらの自動化されたMLOpsパイプラインによって合理化されます。手作業による対応を削減し、エラーや不整合のリスクを最小限に抑えることで、これが実現されるのです。
システム環境のセットアップ、依存関係の管理、展開状況の検証など、反復する作業を自動化することで、組織はAIモデルやソリューションの市場投入までの時間を大幅に短縮することができます。これらすべてを実行しながら、展開における信頼性と一貫性を維持します。
モデルの監視
展開されたモデルの有効性と信頼性が長期にわたって維持されるよう保証することが、モデル監視の目的です。
一度本番環境に展開された後は、モデルの挙動の逸脱を検出するために継続的な監視が不可欠となります。継続的な監視は、正確性を担保するだけでなく、潜在的な問題をプロアクティブに特定し、深刻化する前に対処できるという点で有効なものとなります。MLOpsでは、監視に向けプロアクティブなアプローチを採用しています。これはモデルのパフォーマンス指標、データ品質、モデルドリフトをリアルタイムで追跡することを意味します。
MLOpsにおけるモデル監視の中核となるのが、パフォーマンス指標の追跡です。これらの主要な指標は、モデルが本番環境でどれだけ正しく機能しているかを示すインサイトを提供します。精度(Accuracy)、適合率(Precision)、再現率(Recall)、F1スコアは、モデルの有効性を定量的に測定するための指標であり、これによって組織が事前に定められたモデルの性能基準を満たしているかどうかを評価することができます。
これらの指標を継続的に監視することで、データチームは性能の劣化や異常を特定し、潜在的な問題の兆候を早期に察知することが可能となります。例えば、同チームはコンセプトドリフトやデータドリフト、モデル劣化の兆候を特定し、迅速に是正措置を講じることができます。
パフォーマンス指標に加えて、MLOpsではデータ品質やモデルドリフトの追跡といった内容も網羅します。活用例として、担当チームによる入力データの完全性や一貫性の評価にも、MLOpsツールは有効となるできでしょう。最終的な目標は、モデルが推論に向け高品質な入力を受け取れるよう保証することなのです。予想されるデータ分布からの逸脱やデータ特性の異常は、モデルの性能に影響を与える可能性のあるデータ品質の問題を示している可能性があります。
同様に、モデルドリフトの監視では、入力データとモデル予測内容との関係の経時的変化を検出します。ドリフト監視は、モデルが意図された範囲外で動作している場合や、基盤となるデータパターンが変化した場合にフラグを立て警告を発します。この情報をもとに、担当チームは必要に応じて、精度と関連性を維持するためにモデルの再トレーニングや再キャリブレーションを行うことができます。
モデルのガバナンス
モデルのガバナンスは、MLOpsのエコシステムにおいてもっとも重要なものとなります。これはとくに、厳格なコンプライアンス要件を満たさなければならない規制産業において顕著になります。組織は、MLOpsのフレームワークがガバナンスおよびコンプライアンスの課題に対応していることを確認する必要があります。この中には、モデルのバージョン管理、リネージの追跡、アクセス制御の実装、モデルの挙動監査に向けたプロセスと制御が含まれます
効果的なモデルのバージョン管理は、MLOpsにおけるモデルガバナンスの要とも言えます。これにより、組織はモデルの変更履歴を追跡し、再現性とトレーサビリティを確保することができます。モデルのバージョン履歴を維持管理することで、必要に応じて容易に以前のバージョンへ戻すことが可能となります。さらに、開発から配備までのモデルの変化を明確に追跡することができます。
コースに関する適切なバージョン管理は、データチーム間の知識共有を促進させます。さらに規制遵守のための明確な監査証跡も提供します。効率的なMLOpsは、最終的にモデルの開発および展開プロセス全体における透明性と説明責任を示すべきなのです。
バージョン管理だけでなく、適切な追跡管理もまたMLOpsには不可欠となります。データリネージとは、データチームがどのようにモデルを作り、どのようなデータを使ってモデルをトレーニングしたかを把握することです。もちろん、これは組織全体におけるAIの民主化にも役立ちます。しかしそれだけに留まらず、コンプライアンスや規制要件の遵守についても、より円滑なものとします。
効果的なMLOpsとはどのようなものか?
強力なMLOpsの実現に向けた堅牢な機械学習モデル管理プログラムは、次のような質問に回答することを目的としています:
- モデルを開発および選定する際には、どのパフォーマンス指標を測定するのか?
- モデルが堅牢で偏りがなく、安全であることをどのように保証するか?
- ビジネスにとって許容できるモデルの性能はどの程度のレベルか?
- 本番環境における機械学習モデルの性能や保守の責任者を明確に定めているか?
- モデルドリフト(つまりモデル性能の劣化)に対応するために、機械学習モデルはどのように更新およびリフレッシュされるのか?アラートが発生した際、簡単にモデルを再トレーニングできるか?
- モデルや機械学習プロジェクトの展開における信頼性をどのように高めるのか?
- 目まぐるしく変化するAI環境の中で、刻々と変化するビジネスニーズに対応する機械学習プロジェクトをどのように迅速に展開できるか?
- モデルの劣化、予期せぬ異常なデータや予測値を検出するために、長期にわたりどのようにモデルを監視しているのか?
- モデルはどのように監査され、開発チーム以外の人にも説明が可能か?
- AIのライフサイクルに沿って、モデルやプロジェクトをどのように文書化しているのか?
これらの質問は、機械学習モデルのライフサイクル全体にわたるものです。注目すべきは、これらの質問への回答には、データサイエンティストだけでなく、企業全体のさまざまな人々が関わるという点です。MLOpsは単なるツールや技術の問題ではないからです。サイロを取り払い、コラボレーションを促進することで、継続的かつ再現可能で摩擦のないAIライフサイクルのもとで機械学習プロジェクトにおける効果的なチームワークを実現することなのです。
適切なMLOpsを実践せずに大規模な形で機械学習モデルを展開する組織は、モデルの品質と継続性の問題に直面するでしょう。MLOpsを実践していないチームは、現実的にビジネスへ悪影響をおよぼすモデルを導入してしまうリスクを負います。例えば、偏った予測をして会社に悪影響を与えるモデルについて考えてみてください。
なぜMLOpsの実現は困難なのか?
MLOpsとDevOpsの違いについて言及すれば、MLOpsは単にDevOpsの手法を機械学習に適用するというよりも、少し複雑なものとなっています。実際に、大規模な形で機械学習のライフサイクルを管理することが困難な理由としては、主に次の3つがあります:
- 断片化されたAIツールを取り巻く環境:DevOpsとは対照的に、AIツールを取り巻く環境は非常に細分化されており、常に変化しています。それは多種多様な技術や手法をともないます。数多くのフレームワーク、ライブラリ、プラットフォームが存在する中、組織は自社固有のニーズに合致した適切なツールを選択しなければなりません。また同時に、機械学習パイプライン全体での互換性と相互運用性を確保する必要があります。
- 学際的なコラボレーション:大規模にAIを運用することはチームスポーツのようなものであり、全員が同じ言語を話すわけではありません。機械学習のライフサイクルにはさまざまなチーム(技術、ビジネスなど)が関わりますが、彼らは必ずしも同じツールを使用しているわけではありません。そして多くの場合、これらの異なるプロフィールを持つチームメンバーは基本となるスキルを共有しておらず、それがコラボレーションをより困難なものにしているのです。MLOpsの導入を成功に導くためには、これら多様なステークホルダー間のコミュニケーションギャップを埋めるための対応が不可欠となります。
- スキルセットの不一致:(ほとんどの)データサイエンティストは、ソフトウェアエンジニアやデータエンジニアの資質を備えているわけではありません。彼らの多くは、モデルの構築と評価に向けた対応に特化しており、モデルの展開や維持に関する専門家とは限りません。しかし、その作業成果を本番環境で活用するために、モデルの展開に取り組まざるを得ないケースが少なくありません。このようなスキルセットの不一致は、MLOpsのワークフローにおける非効率やボトルネックにつながる可能性があります。
企業がより多くのAIを活用するようになるにつれ、一貫した方法で問題を追跡し解決することがより困難になります。とくに担当チームが複数のプラットフォームを使ってモデルの構築、展開、展開後の状態監視を行っている場合は、これが一層困難になります。これらの問題は、経営者がもっとも聞きたくない言葉である「監督不行き届き」につながります。DataOps、MLOps、LLMOpsを統合した”XOps(英語)”と呼ばれる統一領域は、それぞれの分野の共通の目標や意図を最大限に活かすことで、分断されたプラットフォームやプロセスに依存することのない、一貫したアプローチを実現します。
XOpsとは何か?
生成AIのデジタル提供に関する需要が急速に高まる中、技術スタックの一新だけでなく、AI展開の基盤となる実践やプロセス自体の革新が不可欠となっています。例えるなら、自動車製造はこの数十年の間に、オーダーメイドでの製造形態から、部品を標準化し各工程を合理化した、効率的かつスケーラブルな生産を実現する高度に自動化された組立ラインへと進化しました。
AIエンジニアリングは、AIへの取組みにおける同様の変革であり、カスタムメイドのモデルから標準化されたスケーラブルなソリューションへの移行なのです。どちらの領域においても、考え方の転換、プロセスの標準化、そして実施への強いこだわりが求められます。AIエンジニアリングの実践を取り入れ、責任あるAIの展開を確実に遂行することで、組織はAIの力を活用してイノベーションを促進し、社会に多くの付加価値を提供できるようになります。それでは、XOpsの出番はどこにあるのでしょうか?
ModelOpsとDataOps(英語)を統合したXOpsアプローチの採用は、AIのライフサイクル全体にわたる知的財産(IP)の育成に向けた非常に効果的な戦略となります。このアプローチは、AIバリューチェーンに沿ったエンジニアリングの実践における統合作業を合理化するもので、実験段階から長期的な運用段階までを一つの統合された環境内でカバーします。
XOpsプラットフォームでAIのスケーリングとイノベーションを推進
XOpsでは、実践、プロセス、テクノロジーを標準化することで、組織が単発のカスタムAIモデルから堅牢なAIアセンブリーラインによる知的財産の構築体制へと移行できるよう支援します。
これは単独の取り組みでも、また孤立した取り組みでもありません。ワークフロー設計からレシピ作成、そしてモデル検証まで、ライフサイクル全体で知識を蓄積する協働的かつ普遍的な取り組みであり、この貴重な知識はプラットフォームに依存しない形で保存および活用されるべきものなのです。
自動車がさまざまなメーカーによって設計された部品から組み立てられるのと同様に、XOpsは多様なプロバイダーのモデルを組み立て、処理し、管理し、運用する際に、その普遍性を発揮します。
Dataikuは、XOpsのユニバーサルアセンブリーラインとして、コラボレーションおよびイノベーションを促進します。このアプローチを採用することで、組織はAIイノベーションを新たな高みへと押し上げ、真の価値を提供するスケーラブルなデータ製品を創出し、AIが生活のあらゆる側面を向上させる未来へ私たちを前進させることができます。
MLOpsを開始する
現実に目を向けましょう:多くのデータサイエンスチームは、時間をかけるべきでない作業に、実に多くの時間を費やしています。例えば、データの準備やデータ管理に時間をかけ過ぎています。当然、本番環境へのデータ展開は手慣れたものでなく、メンテナンスにも困難がともないます。さらに、エンドユーザー向けのインターフェースやアプリケーションの構築は、実験やモデルの開発という彼ら本来の専門分野から外れたものと言えます。
MLOpsソリューションの導入は、この課題の解決策のひとつです。
Dataikuは、組織におけるすべてのモデルやプロジェクトを本番環境で管理するための包括的なソリューションとなります。データへのアクセスおよび準備から、モデリング、アプリ開発、本番展開、そして保守まで、Dataikuは一つの統合プラットフォームでこれらをカバーします。従来の機械学習や生成AI、またはその両方が併用されているかどうかに関わらず、Dataikuはデータチームの対応作業を加速化します。
ある大手金融機関は、DataikuをMLOpsおよび潜在的リスクの検出に向け活用しています。同社では、大規模でミッションクリティカルなワークロードを扱う125人以上の関係者をサポートしています。DataikuをMLOpsのプラットフォームとして使用することで、次のような成果が得られました:
- 本番環境向けモデルコードの最適化とリファクタリングにかかる時間を86%削減。
- DataikuのビジュアルレシピとGUIにより、機械学習担当エンジニアが書くパイプラインのプロダクションコードを75%削減。
- 従来のデスクトップソリューションと比較して、展開にかかる時間を全体で90%短縮。
設計環境と本番環境の統合
設計環境と本番環境の統合により、機械学習プロジェクトの展開プロセスをシームレスかつ効率的に推進することができます。例えば、統合された設計環境と本番環境を提供することで、Dataikuは組織がモデルの開発から展開へとシームレスに移行できるよう支援します。さらにDataikuでは、大規模なリファクタリングや再構成も不用となります。結論:Dataikuは、担当チームが真のビジネス成果を生み出せるよう、価値実現までの時間を短縮します。
Dataikuの主要なMLOps機能のひとつとなるのが、Deploy Anywhere機能です。Deploy Anywhereを使用することで、Dataikuで開発したモデルをあらゆるクラウドは環境の機械学習プラットフォーム上に展開することができます。この柔軟性によりベンダーロックインが解消されるため、組織は自社で選んだインフラを活用できるようになります。Deploy Anywhereは、異なるクラウドプロバイダー間やハイブリッド環境間でのシームレスな移行を促進し、機械学習の展開におけるスケーラビリティー、耐障害性、コスト効率を確保します。
さらに、Dataikuの設計環境と本番環境間のシームレスな統合により、部門を超えたチーム間のコラボレーションや知識の共有が促進されます。統一された環境内で、データサイエンティスト、データエンジニア、ビジネスアナリスト、ITプロフェッショナルのコラボレーションが可能となります。各個人およびチームは、それぞれの専門知識やスキルを活かしてイノベーションを推進し、共有されたビジネス目標を達成することができます。
このコラボレイティブなアプローチにより、機械学習のライフサイクル全体を通じて俊敏性と透明性が促進されます。Dataikuにより、組織はガバナンス、安全性、コンプライアンス基準を維持しつつ、変化する要件や市場の動向に迅速に適応できるようになります。
容易な監視と保守
展開後は、Dataikuの堅牢なMLOpsサービスが稼動することで、プロジェクトの監視と維持を自動化し、継続的にパフォーマンスとスケーラビリティーを確保します。この自動化により、担当チームは手作業によるプロジェクトの維持管理の負担から解放されます。これはより多くのデータチームが、イノベーション推進や付加価値の高い業務に集中できるようになることを意味します。Dataikuの高度な監視機能により、組織は容易に次の対応ができるようになります:
- 展開されたモデルの健全性とパフォーマンスの追跡。
- 異常や逸脱した行為をリアルタイムで検出。
- 発生する可能性のある問題にプロアクティブに対処。
DataikuのMLOps機能の主な利点の一つは、実験追跡とのシームレスな統合です。これにより、チームメンバーは反復的な実験を行い、さまざまなアプローチで容易にテストを行うことが可能となります。
Dataikuの実験追跡機能を活用することで、データサイエンティストやMLOpsエンジニアはモデルの迅速な反復と最適化を実現できます。この”早期の失敗認識”による実験アプローチが、イノベーションと継続的改善の文化を育みます。
Dataikuは、すべてのモデルやプロジェクトを本番環境で管理するための包括的なソリューションへと進化してきました。例えば、Dataiku Unified Monitoringは、MLOpsプロセスの全体的な可視化と管理のための集中ハブとして機能します。これにより、組織は機械学習の展開状況を完全に包括的な形で把握することができます。
モデルのパフォーマンス指標からデータ品質に関する指標、そしてリソース使用状況の統計値まで、Dataiku Unified Monitoringは、MLOpsワークフローの健全性と効率性に関する総合的な視点を提供します。この集中監視機能により、組織はAI施策の継続的な改善を推進することができます。Dataiku Unified Monitoringを活用することで、組織は実践的なMLOps運用において、より高い透明性、効率性、そして俊敏性を実現できます。これはつまり、ステークホルダーに対してより素早く、より確実に価値を提供できるということなのです。
ボーナス:DataikuのLLMメッシュ、Prompt Studios、RAG機能を活用することで、データサイエンティストは生成AIでモデルやプロジェクトを素早く強化することができます。つまり、すべて最新のLLMやサービスを、IT部門による承認済みの環境で利用できるということです。
