
大規模言語モデル(LLM)とは?
ニューラルネットワークの一種である大規模言語モデル
2022年12月にOpenAIがChatGPTを公開したことで、AI全般への関心が急速に高まり、その中でもとくにAIチャットボットを支える技術群に大きな注目が集まりました。大規模言語モデル(LLM)と呼ばれるこれらのモデルは、ほぼ無限とも思えるほど幅広いトピックについてテキストを生成する能力を備えています。
LLMでとくに印象的なのは、(プログラミング言語も含む)ほぼすべての言語で、人間のように自然な文章を生成できるその能力です。ここで適用されている技術は、機械学習における自然言語処理のごくあたり前な進化系ではあるものの、これらのモデルは真のイノベーションを象徴するものとなっています。なぜなら、これまでのあらゆる技術を凌駕する、高度で洗練された出力結果を生み出すことができるからです。なぜ大規模言語モデルがファウンデーションモデルと呼ばれているのか、不思議に思われるでしょうか?ファウンデーションモデルとは、さまざまな特定用途のアプリケーションを実行するように設計されたAIシステムを指します。このオリジナルモデルは、他のさまざまなアプリケーションを構築するための基盤(ファウンデーション)を提供します。ファウンデーションモデルという言葉が、LLMと同義に用いられることも少なくありませんが、これはLLMが、現状もっともよく知られ、広く使用されているファウンデーションモデルであるためです。
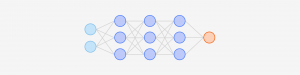
ニューラルネットワークは、ニューロンと呼ばれる小規模な数学関数を多数組み合わせた、機械学習(ML)モデルの一種です。これらは脳のニューロンと同様に、計算処理の最小単位です。各ニューロンは、入力内容に基づいて出力を計算する単純な数学関数です。しかし、ニューラルネットワークの能力は、ニューロン間の接続構造によって決定されます。
各ニューロンは他のいくつかのニューロンと接続されており、それぞれの接続の強さは数値での重みづけ(ウェイト)によって定量化されます。これらの重みづけにより、あるニューロンの出力が次のニューロンへの入力としてどの程度考慮されるべきかが決定されます。
ニューラルネットワークは非常に小規模なもの(基本的なものであれば、6つのニューロンとそれらの間に合計8つの接続を持つ)から、LLMのように非常に大規模なものまで存在します。このような大規模なネットワークには、数百万のニューロンや数千億もの接続が存在し、それぞれの接続に対して固有の重みが割り当てられています。
LLMはトランスファーマーアーキテクチャーを使用
言語モデルはどのように機能するのでしょうか?LLMは、トランスフォーマーと呼ばれる特殊なニューラルネットワークアーキテクチャーを使用しており、同アーキテクチャーは、テキストデータの逐次処理および生成に向け最適化された設計となっています。
ここで言及する「アーキテクチャー」は、ニューロン同士がどのように接続されるかを記述したものです。すべてのニューラルネットワークは、ニューロンを複数の異なる層(レイヤー)にグループ化する形で構成されます。多くのレイヤーがある場合、ネットワークは”ディープ(深い)”と表現され、これが「ディープラーニング」という言葉の語源になっています(英語)。
シンプルなニューラルネットワークのアーキテクチャーでは、各ニューロンが上位の層のすべてのニューロンと接続されている場合があります。他のアーキテクチャーでは、ニューロンはグリッド上でもっとも近くにある一部のニューロンとだけ接続されている場合もあります。後者は、畳み込みニューラルネットワーク(CNN)と呼ばれるものです。CNNは、過去10年間にわたり、現代の画像認識技術の基盤を築いてきました。CNNが(画像のピクセルのように)グリッド構造になっているのは偶然ではありません。実はこれこそが、画像データに対してこのアーキテクチャーがうまく機能する重要な理由の一つなのです。
しかし、トランスフォーマーの場合は少し違います。Googleの研究者たちによって2017年に開発された(英語)トランスフォーマーは、”アテンション(attention)”という考え方に基づいており、これは特定のニューロンがシーケンス内の他のニューロンとより強く結合する(または”より注意を払う”)ことを意味します。
テキストは、単語が順番に読み込まれて生成されていきます。文を構成するそれぞれの要素が文法に従って互いを参照および修飾します(例えば、形容詞は名詞を修飾しますが、動詞は修飾しないといった具合です)。異なる要素同士がさまざまな強さでつながり、シーケンスに従って処理が行われるよう設計されたアーキテクチャーが、テキストベースのデータに対してうまく機能するのは、決して偶然ではありません。
LLMは明示的な指示なしに学習を行う
簡単に言えば、モデルとはコンピュータープログラムを指します。入力データに対してさまざまな計算を行い、出力内容を生成する一連の命令セットです。
しかし、機械学習モデルやAIモデルを特別なものにしているのは、人間のプログラマーが明示的に命令を記述するのではなく、一連のアルゴリズム(計算手順)とハイパーパラメータ(アルゴリズムの設定)を指定するだけで、モデルが自ら大量の既存データを解析し、重みやパラメータを決定する点にあります。このため、人間のプログラマーは直接モデルを構築するのではなく、モデルを構築するアルゴリズムを作成します。
LLMでは、プログラマーはモデルのアーキテクチャーや構築ルールを定義しますが、ニューロンの作成やニューロン間の重みづけを定義するわけではありません。このような対応は”モデルトレーニング”と呼ばれるプロセスで行われ、この過程で該当モデルがアルゴリズムの指示に従い、それらの変数(ニューロン間の重みなど)を自ら定義していきます。
LLMはどのようにトレーニングされるのでしょう?LLMで解析されるデータはテキストです。場合によっては、より専門的なテキストを使用することもあれば、一般的な内容が含まれることもあります。そして、最大規模のモデルの場合は、できるだけ多くの種類のテキストを学習データとして与えることが目標となります。
このトレーニングプロセスでは、数百万ドル相当のクラウドコンピューティング資源が消費されることもあり、その中で該当モデルは膨大なテキストを読み込み、自らテキストを生成しようと試みます。当初、出力される内容は意味不明なものですが、膨大な試行錯誤のプロセスを通じ、またトレーニングデータに含まれる正解と自らの出力を繰り返し比較することで、出力の品質は徐々に向上していきます。生成されるテキストは次第に理解可能なものへと変化し、目的とする出力内容に近づいていきます。
十分な時間、コンピューティングリソース、そしてトレーニングデータがあれば、モデルは”学習”を重ね、最終的には人間が書いたテキストと区別がつかないほど自然な文章を生成できるようになります。場合によっては、人間の読者がフィードバックを与える報酬モデルのような仕組みが使われることがあります。これは、生成されたテキストが自然に読めるかどうかを評価し、良い場合には報酬を、良くない場合には報酬を与えない(あるいはマイナスの評価をする)ことで学習を促す手法で、「人間のフィードバックによる強化学習(RLHF:Reinforcement Learning from Human Feedback)」と呼ばれます。モデルはこの内容を考慮しながら、フィードバックに基づいて継続的に自己改善を行っていきます。
LLMは次にどの単語が来るべきかを予測
LLMについて耳にする簡略な説明として「次に来る単語を単純に予測しているだけだ」というものがあります。これは事実ではあるものの、この単純なプロセスによって、ChatGPTのようなツールが非常に高品質なテキストを生成できるという点を見落としています。同様に、「モデルは単に数学的な計算をしているだけだ」という発言も間違ってはいませんが、モデルがどのように機能し、独自の力や応用の可能性を秘めているかを理解するという重要な視点が欠けています。
上記のトレーニングプロセスの結果として得られるのは、数百万のニューロン間で何千億もの接続を持つニューラルネットワークであり、それらの接続はすべてモデル自身によって定義されたものです。最大規模のモデルでは、すべての重みを保存するだけで数百ギガバイトにも及ぶ大量のデータを必要とします。GPT-3.5 TurboモデルのベースとなっているGPT-3.5モデルは、1,750億個の重みづけを持っており、またGPT-4については、現状、具体的なパラメータ数が公開されていませんが、数千億個以上のパラメータが含まれているものと推測されます。
それぞれの重みづけやニューロンは数学的な計算式で構成されており、モデルに入力される単語(または単語の一部)ごと、そしてモデルが出力として生成する単語(または単語の一部)ごとにこれらの計算が実行されます。
技術用語として、これらの”小さな単語や単語の一部”は「トークン」と呼ばれます。これらのトークンは、多くの場合、該当モデルがサービスとして提供される際の利用料金の計算基準として利用されます。これらのモデルと対話するユーザーは、テキスト形式で入力を行います。例えば、ChatGPTに対して次のようなプロンプトを提示することができます:
「こんにちは、ChatGPT。Dataikuについて100語で説明してください。説明には、Dataikuが提供するソフトウェアと主要な提供価値も含めてください(Hello ChatGPT, please provide me with a 100-word description of Dataiku. Include a description of its software and its core value proposition.)」
ChatGPTを背後で機能するモデルは、このプロンプトをトークンに分解します。平均すると、1トークンは単語の5分の4に相当するため、上記のプロンプト(英語原文)の23単語は約30トークンになる可能性があります。
その後モデルは、トレーニング時に取り込んだ膨大な量のテキストの解析結果に基づいて、適切と思われる応答を生成します。重要となるのは、モデルが質問そのものに関連する情報については何も探していない点です。モデルには”Dataiku”、”提供価値”、”ソフトウェア”などの関連情報を検索できるようなメモリ(記憶領域)がありません。その代わりに、モデルは出力テキストの各トークンを順に確認しながら計算を行い、もっとも適切と思われる確率の高いトークンを生成しています。
LLMは正しく聞こえるテキストを生成するものの、その正当性は保証できない
LLMは、その出力内容の正当性を保証することはできず、あくまで”正しく聞こえる”出力を提示しているだけです。なぜなら、LLMによる応答はその過去の記憶から検索されたものではないからです。先ほど説明した重みづけに基づいて、その場で生成されているのです。LLMの能力は、事実を記憶して思い出すことではありません。そのような対応なら、もっとも単純なデータベースでも完璧にこなすことができるでしょう。むしろLLMの強みは、人間が書いたように自然で、しかも正しく聞こえるテキストを生成できることにあります。正しく聞こえるテキストは実際に正しいものであることがほとんどですが、常にそうとは限らないのです。もっともらしく聞こえるものの、実際には誤っているという状況は、“AIハルシネーション(幻覚)”として知られており、現在のLLM利用における固有リスクの一つとなっています。ただし、このリスクを軽減するための対策も存在します。
LLMの知識は、トレーニング用データセットに含まれる情報に限定されているため、不完全であったり、誤っていたり、古くなっている可能性があります。例えば、ChatGPTのトレーニングデータセットは、2021年9月までの情報を基に構成されています。このため、ChatGPTが認識できるのは、この日以前に知られていた事実のみとなります。さらに、このトレーニングデータセットに含まれる事実のほとんど、あるいはすべてがインターネット上で公開されている情報であるため、ChatGPTはプライベートな情報に関する質問には答えることができません。多くの重要なビジネスユースケースでは、会議議事録、法的文書、製品仕様書、技術文書、研究開発報告書、業務手順書などの非公開文書についても考慮する必要があるため、これは非常に大きな課題と言えるでしょう。
この課題を緩和する方法として、ユーザーが質問をする際に、指定されたナレッジバンク(情報データベース)から関連する事実を検索し、質問内容とともに検索された事実をLLMに送信するという手法があります。例えばDataikuでは、Retrieval-Augmented Generation(RAG)(英語)のアプローチとDataikuの組み込みチャットインターフェースであるDataiku Answersを活用し、自社のドキュメンテーションから回答を提供するQ&Aチャットボットを開発しました。RAGのような技術は、企業向けのカスタマイズされたチャットボットを大規模に展開する際に有効となる(英語)、より信頼性の高い手法と言えるでしょう。
外部のナレッジソースへのアクセスを可能にするツールと組み合わせることで、言語モデルはその推論能力を拡張し、実世界での活用も可能となります。このようなタイプの拡張されたLLMは、一般的に”エージェント”と呼ばれます。ここで言及するツールとは、エージェントがタスクを実行するために利用できるあらゆる機能やプログラムのことを指します。これらの技術については、後ほどプロンプトエンジニアリングやRAGなどを使ったLLMの強化方法を説明する際に詳しく解説します。
企業におけるLLMの活用
企業でLLMを活用する方法は、大きく分けて2つあります。そして、各アプローチには独自のメリットとデメリットがあるため、次にその内容を説明します。
オプション1: LLM APIの活用
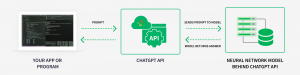
企業でLLMを活用するための最初の方法は、サービスとして提供されているモデルに対してAPIコールを行うというものです。例えば、企業はChatGPTの基盤となっているGPT-3.5やGPT-4のモデルにアクセスし、自社専用のアプリケーションを構築することができます。
OpenAI、Anthropic、Mistral、CohereといったLLM専業プロバイダーに加え、主要なクラウドコンピューティング企業も次のような専用のAIサービスを提供しています:Amazon Bedrock、Google Cloud Vertex AI、Microsoft Azure OpenAI Serviceなどがこれに該当します。
APIコールを行うためには、小規模なソフトウェアプログラムやスクリプトを設定する必要があります。このスクリプトはAPIに接続し、適切にフォーマットされたリクエストを送信します。APIはリクエストをモデルへ送信し、モデルはAPIへレスポンスを返します。その後APIは、リクエスト元にレスポンスを送り返します。
API経由で大規模言語モデル(LLM)をサービスとして利用するメリット
このアプローチには、次のような複数のメリットがあります:
- 参入障壁の低さ:APIの呼び出しはシンプルな作業です。ジュニアレベルの開発者でも数分で対応することができます。
- より洗練されたモデル:APIの背後で動作するモデルは、多くの場合、利用可能な最大でもっとも洗練されたバージョンとなります。これは、大規模モデルは小規模で単純なモデルと比べて、より広範なトピックについて、洗練された正確な回答を提供できるからです。
- 素早い応答:一般的にこれらのモデルは、リアルタイムでの使用を可能にする比較的迅速な応答(秒単位のオーダー)を返すことができます。
API経由で大規模言語モデル(LLM)をサービスとして利用する際の制約
前述のとおり、API経由での公開(パブリック)モデルの利用は便利でパワフルです。しかし、以下のような制約により、特定の企業向けアプリケーションには適さない場合もあります:
- データレジデンシーとプライバシー:公開APIを利用する場合、クエリの内容をAPIサービスのサーバーへ送信する必要があります。企業は、このアーキテクチャーが、自社のデータレジデンシー(データの所在)およびプライバシーに関する要件を満たしているかどうかを、ユースケースごとに慎重にチェックする必要があります。
- コストが高額になる可能性:公開されているAPIのほとんどは、有料サービスとなっています。ユーザーは、クエリの回数や送信されるテキストの量に応じて課金されます。とくにRAGやエージェントベースの手法を用いた場合は、コストが急激に増加する可能性があります。月末に予想外の請求が発生するといった事態を防ぐために、企業は厳格なコスト管理とモニタリングのプロセスを導入すべきです。
- 依存関係の強さ:APIの提供元は、いつでもサービスを停止または変更することができます。企業は、このようなサービスに依存することによるリスクを十分に検討し、あらかじめ代替手段(フォールバックプラン)を用意しておく必要があります。
オプション2:マネージド環境でオープンソースモデルを実行
二番目の選択肢は、オープンソースのモデルをダウンロードし、自社で管理するシステム環境で実行するという形態です。Hugging Faceのようなプラットフォームでは、このようなモデルを幅広く集約しています。
API経由で公開モデルを利用する際のデメリットを考慮すると、特定の企業やユースケースにおいて、この選択肢は合理的と言えるでしょう。これらのモデルは、企業が所有するサーバー上、あるいは企業が管理するクラウド環境で実行することができます。
オープンソースモデルを自社で管理することによるメリット
このアプローチには、以下のような興味深い複数のメリットがあります:
- セキュリティーおよびプライバシー:これらのモデルはプライベート環境やオフライン環境でホストすることが可能であり、個人識別情報(PII)や機密情報を扱う厳格な規制が適用される業界やユースケースに適しています。
- 幅広い選択肢:LLaMA、Mixtral、Falconなどを含む数十万ものオープンソースモデルやモデルファミリーが存在しており、それぞれに独自の強みと弱みがあります。企業は、自社のニーズにもっとも合致したモデルを選択することができます。しかし、この方法を採用するためには関連技術への深い理解と、それぞれのトレードオフを適切に判断する能力が求められます。選択肢が非常に多いため、適切なLLMを選定する作業が非常に困難となり、幅広い選択肢自体がデメリットにもなりかねません。
- コストを抑えられる可能性:場合によっては、用途が限定された小規模なモデルを実行することが合理的な選択肢となります。モデル推論に必要なモデルストレージと計算の費用のみを支払えばよいため、特定のユースケースに適したパフォーマンスを低コストで実現することができるからです。
- 独立性:オープンソースモデルを自社で運用および管理することで、組織はサードパーティーのAPIサービスに依存する必要がなくなります。これらのモデルについては、企業やユーザーが自由にファインチューニング(微調整)やカスタマイズを行うことができます。
オープンソースモデルを自社管理する際のトレードオフ
オープンソースモデルを利用するメリットは多岐にわたります。ただし、以下の理由により、すべての組織やユースケースにとって最適な選択肢にはならない可能性もあります:
- 複雑さ:LLMのセットアップと維持には、高度なデータサイエンスおよびエンジニアリングの専門知識が不可欠となります。ここで求められるのは、単純な機械学習モデルで必要とされるレベルをはるかに超えた専門知識なのです。組織は、自社に十分な専門知識が備わっているかどうかを慎重に評価する必要があります。さらに重要となるのは、それらの専門家が長期にわたって対象モデルをセットアップおよび維持するための十分な時間とスキルを持っているかどうかという点です。
- コスト:セルフホスト型LLMのセットアップおよび維持に必要な専門AIエンジニアリングリソースの費用に加え、GPUの導入や継続的な計算コストについても考慮する必要があります。いずれにしても、これらの計算作業は、設置コスト、管理コスト、電力消費をともなうハードウェア上で実行する必要があり、これらのハードウェアに対しては、月末に料金の支払いが発生します。一方、主要なLLMプロバイダーの場合には、ハードウェアおよび計算リソースのコストを全顧客に分散して負担させることができるため、個々の顧客にかかるコスト負担を大幅に軽減することが可能となります。
- パフォーマンスの低下:パブリックAPI経由で提供される非常に大規模なモデルは、カバーすることが可能なトピックの幅広さにおいて驚異的な能力を発揮します。オープンソースコミュニティーによって提供されるモデルは、一般的に規模が小さく、用途がより特化されています。
DataikuでAIの活用を促進
Dataikuがコアビジョンとして掲げるのは、お客様企業が最新技術を迅速に導入および統合できるようにすることであり、これは一貫して変わりません。この理念はLLMにも引き継がれています。
企業におけるLLMアプリケーションにおいて、AIサービスを利用するか、セルフホスト型モデルを使用するかの判断は、ユースケースに応じて決定されます。幸いなことに、Dataikuはこれら両方のアプローチに完全対応しており、LLMを大規模に活用するために不可決となる包括的なフレームワークも提供しています。Dataikuでは、Amazon Web Services(AWS)、Databricks、Google Cloud、Microsoft Azure、Snowflake(Arctic)など、15以上の主要なクラウドおよびAIベンダーへのダイレクトな接続機能を提供しています。
さらにDataikuは、追加の形でディープラーニングおよび自然言語処理(NLP)向けの機能も提供しています。これらの機能はLLMを基盤に構築されており、入力として自然言語や画像を使用する機械学習モデルの構築を支援します。例えば、LLMメッシュに登録された埋め込み型モデルを使用することで、テキストや画像の両方を容易に数値へ変換できると同時に、これらの非構造化データに含まれる重要な情報も保持されます。これらのベクトル化された特徴は、ビジュアル機械学習インターフェースにおいて容易に分類や回帰のタスクに活用できます。
より詳細な内容へ
Discover Generative AI Use Cases: Real Applications, Real Safety
プロンプトエンジニアリングやRAGなどを用いたLLMの強化
LLMやプロンプトエンジニアリングは優れた出発点となりますが、複雑な迷路のような行程を進むためには、ビジネス環境に適応した専門的なソリューションが不可欠となります。
知識の森:RAGが照らし出す道
契約書、ユーザーガイド、無数のPDFなど、テキスト文書の宝の山を抱えている企業にとって、この迷路を進むためのコンパスとなるのがRAG技術なのです。
LLMにおけるRAGの位置づけは、どのようなものでしょうか?皆様の組織のドキュメント群を広大な図書館のようなものだと想像してみてください。この場合、RAGは以下に示す圧倒的に効率的な司書のような役割を果たします:質問をすると、RAGはさまざまなドキュメントの中からもっとも関連性の高い部分を特定します。これらの厳選された情報は、ユーザーのクエリと結合されてLLMに与えられ、LLMはドキュメント内の情報を直接参照して回答を生成します。要約すれば、これがRAGの仕組みです。

まず、RAGは文書を小さなかたまりに分割し、それらをベクトルに変換した上、ベクトルストアと呼ばれる専用のデータベースに格納します。質問を投げかけると、RAGはまるでユーザー専属の司書のように振る舞います。RAGはベクトルストアをスキャンし、ユーザーの質問にもっとも近いベクトル(つまり関連性の高い文書の断片)を検索します。これらスキャンで見つかった内容は、ユーザーからの質問とペアの形でChatGPTのようなLLMに引き渡され、LLMはこれらの文書を直接参照して回答を生成します。
もし、これらすべてを技術的な複雑さに巻き込まれずに実装する方法をお探しなら、Dataikuが最適となります。Dataikuでは、このRAG技術をワークフローに直接統合できる一連のコンポーネントを提供しています。このビジュアル埋め込み型レシピには、ドキュメントパーサーとベクトルストアが組み込まれています。またDataikuでは、自然言語で質問するだけで、ドキュメントから情報を抽出して即座に回答を生成できる直感的なWebアプリインターフェース用のテンプレートも提供しています。
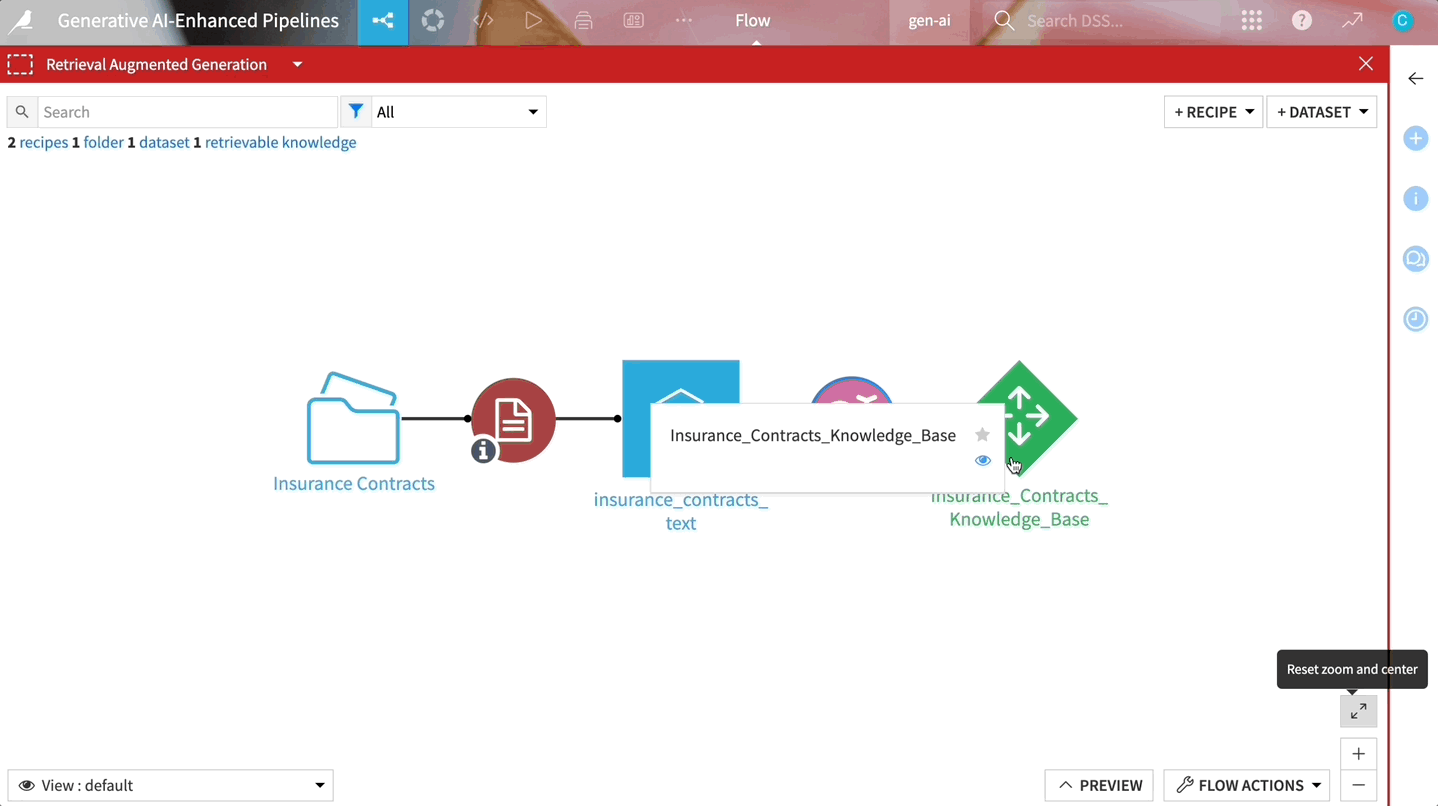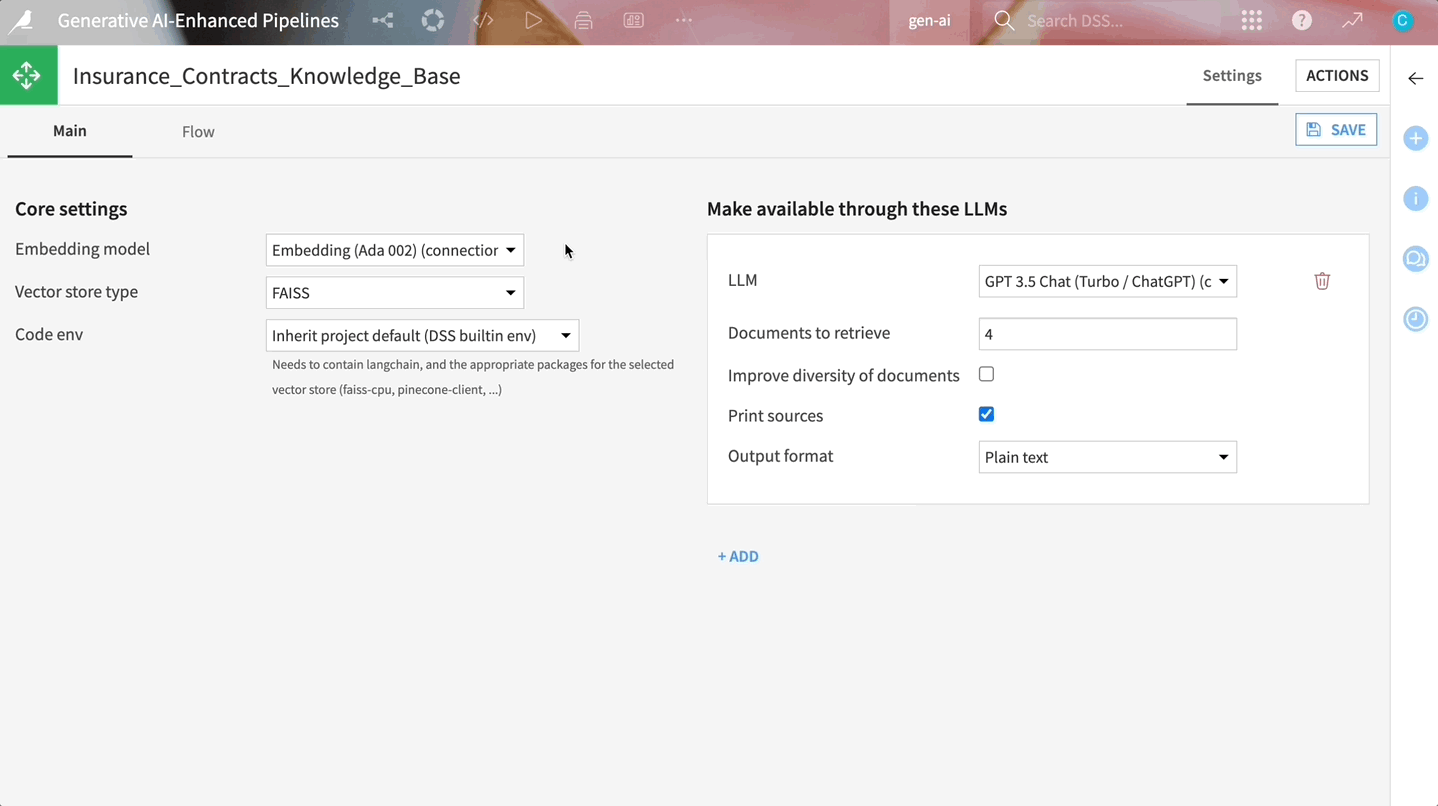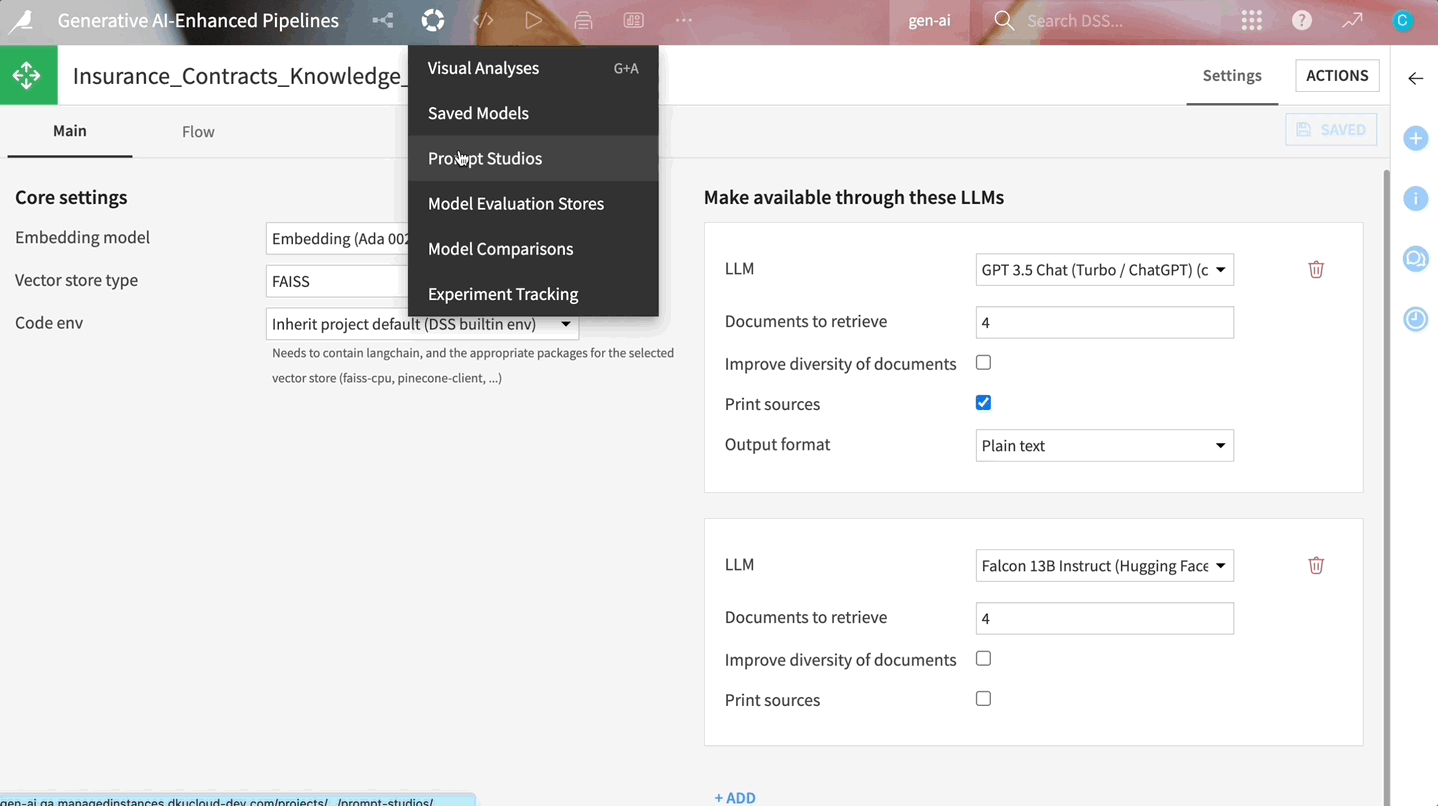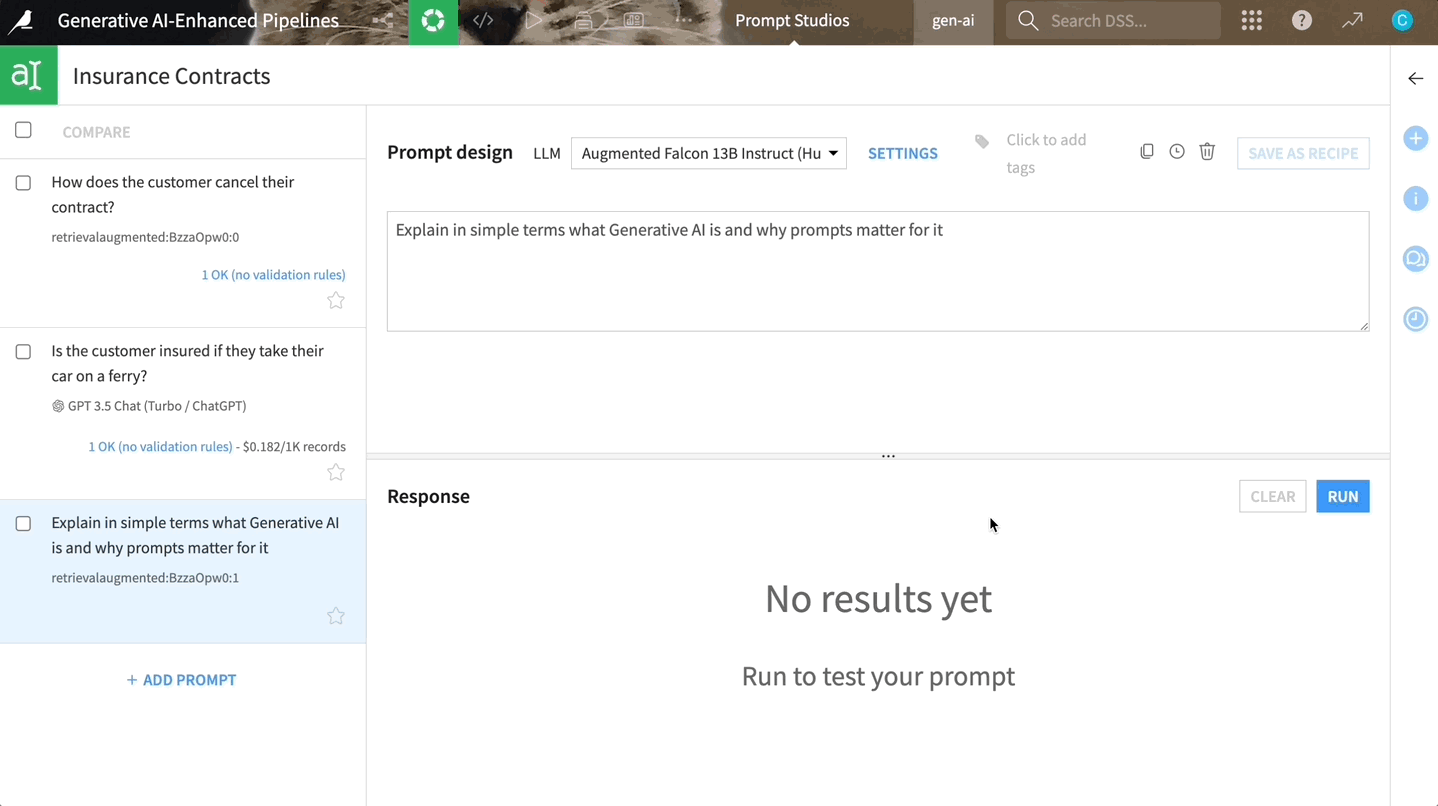
Dataikuのビルトインコンポーネントでは、ドキュメントからテキストを抽出し、それをベクトル化して保存し、その情報によって基盤となるLLMを強化します。
ここで、次のようなフラストレーションがたまるシナリオを想像してみてください:準備が整い、データにRAGを適用しようとした矢先、取り扱うのがテキスト文書ではなく数百万行に及ぶデータセットだと気づいて愕然としたという状況です。RAGがここで機能しない理由は何でしょうか?実は、テーブルデータのベクトル化という対応がRAGの得意分野ではないからです。いまこそ、迷宮の秘密の抜け道を解き明かす時が来ました。RAGの制約を超えてLLMと表形式のデータを統合できるだけでなく、チャートやダッシュボードを生成して分析の道筋を照らすことができる”インストラクション駆動型クエリ実行”と呼ばれる手法について探っていきましょう。
インストラクション駆動型のコマンドで高度な課題に取り組む
ドキュメントではなくデータセットを扱う際には、ガイドとなる別のコンパスが必要になります。ここで登場するのが、インストラクション駆動型クエリです。
主な考え方は、次に示すように非常に簡単です:データセットのスキーマ(列名、データ型、説明など)をLLMに提供し、これに基づいて実行可能なクエリのインストラクションを生成するよう具体的に依頼します。ただし、これらは単なるインストラクションではなく、通常はPythonやSQLで記述されたものであり、求める正確なインサイトを抽出するためにローカルで実行できるよう設計されています。自然言語を使って求める情報を記述するだけで、LLMはユーザーのデータに合わせたチャート、指標、ビジュアルを生成する正確なコードを作成します。ユーザー側でのコーディングは一切不要です。LLMがプログラマー、統計専門家、データサイエンティストの役割をすべて担うからです。
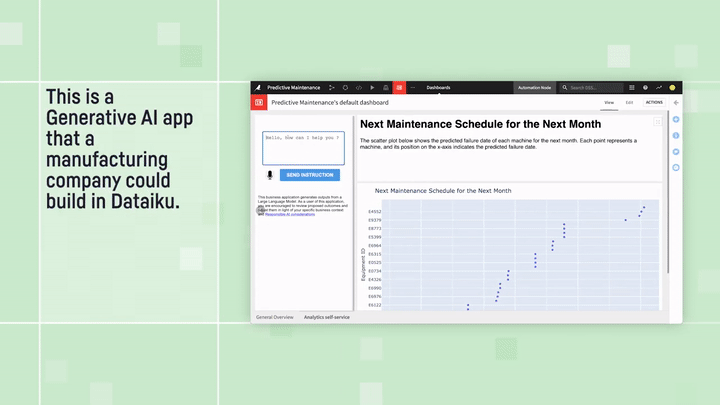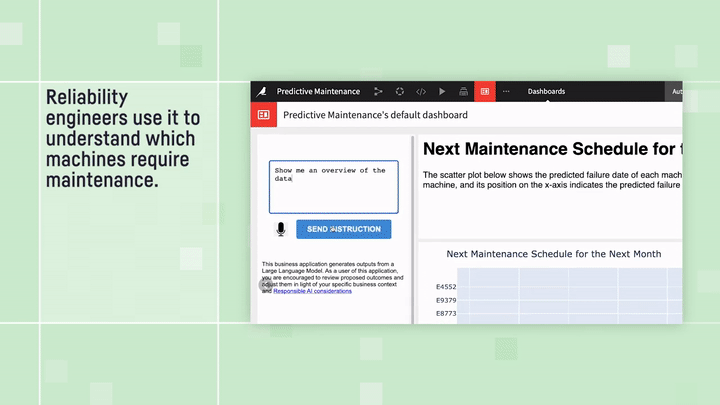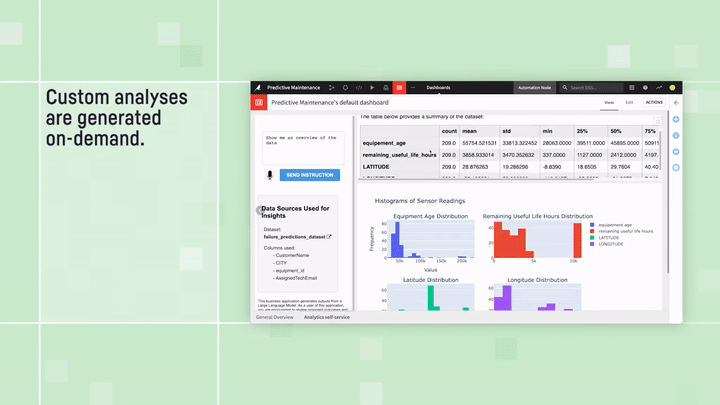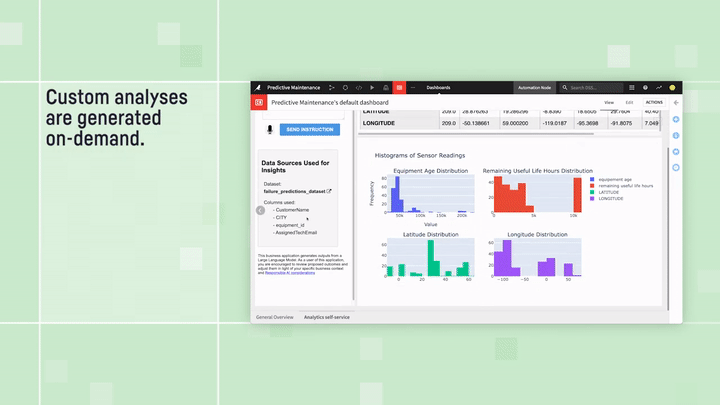
Predictive Maintenance Analysis(予知保全分析):”テキストからダッシュボードへ”の例
もちろん安全こそが最優先事項です。Dataikuは、安全なエクスペリエンスを確保するために、さまざまなインフラストラクチャーに対応し、スケーラブルにコードを実行できる環境を提供しています。また、Python APIを介してデータセット、モデル、レシピ、ダッシュボードへのシームレスなアクセスを可能にします。さらに、すべてのコードは、コントロールされたセキュリティー対策が施されたプロファイルの下で実行されるため、偶発的なデータ事故のリスクを完全に排除することができます。
また、カスタマーレビューのような、より自由な形式のデータを扱う場合でもまったく問題ありません。”構造化”されたパターンを活用することで、そのような非構造化テキストを整理されたデータセットへと変換することができます。その方法については、こちらのブログをご覧ください(英語)。これにより、データが分類、タグづけ、整理された後、インストラクション駆動型クエリ手法を活用できるようになります。
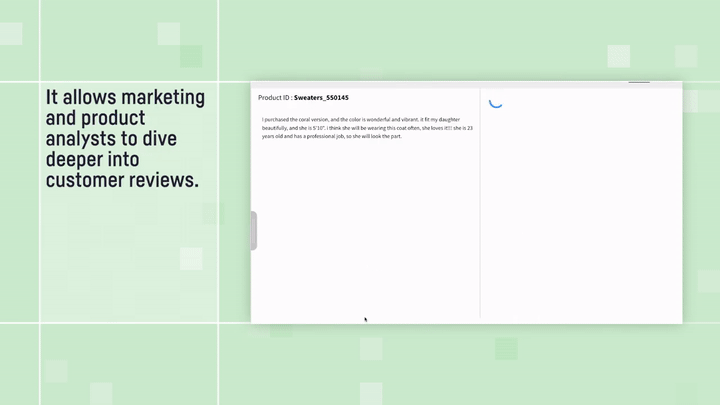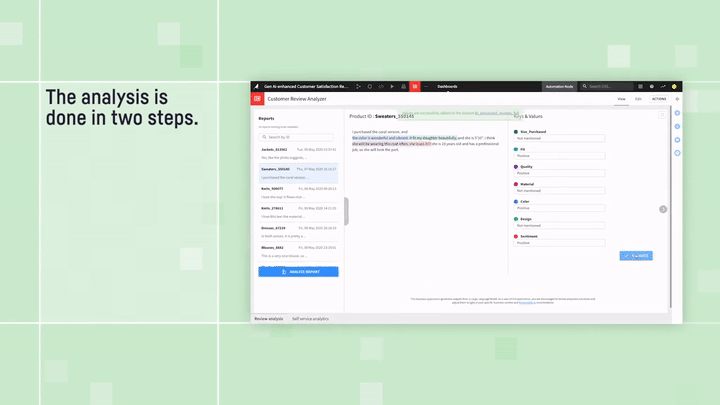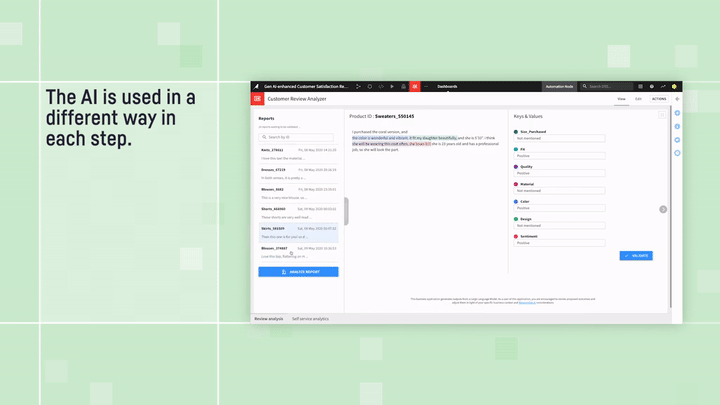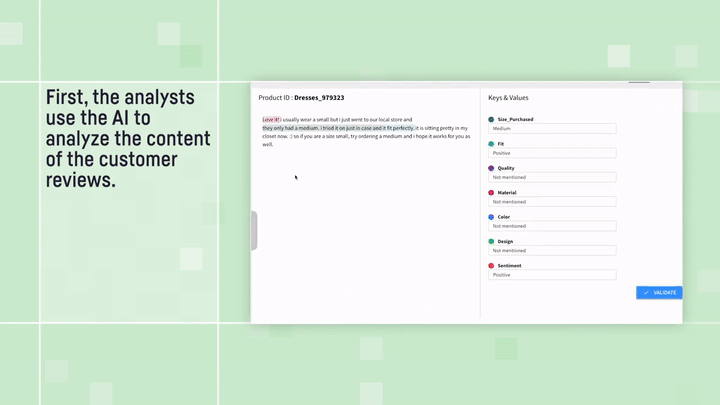
Customer Review Analyzer:テキスト構造化の例
RAGとインストラクション駆動型クエリでツールキットを強化した皆様の前に広がるのは、文書やデータセットが入り混じった迷路のような複雑な課題の数々です。これらに対処するためには、複数のツールを融合させる必要があります。次のステップは、これらのツールとカスタム設計されたインテリジェントなガイドとの統合です。同ガイドは、各ツールを「いつ」「どのように」適用すれば複雑な課題が解決できるかを明らかにするものです。
潜在能力を最大限に引き出すマスターエージェント
入り組んだ迷路のような数々の課題がさらに続き、多くの曲がり角や分岐点、さらに多種多様なデータ形式が待ち受けています。ドキュメント、データセット、Webサイト。それぞれの課題解決に最適なツールを動的に選択できるガイドが必要となります。ここで皆様専用に設計されたマスターオーケストレーター(指揮者)という存在であるAIエージェントの登場です。
あたかも知識豊富な探検家のように、AIエージェントは状況に応じて推論と行動を組み合わせ、最適なアプローチを決定します。社内ドキュメントとデータセットを使って質問に答える必要はあるのでしょうか?エージェントは、関連するテキストを迅速に取得するためにRAGベースのツールを呼び出し、カスタム分析コードを生成するためにインストラクション駆動型クエリを実行します。さらに未知の課題に直面した場合には、エージェントは複数のツールの組み合わせを反復的に試すことで、時間とともにその能力を拡張していくことができます。
Dataikuは、ReAct(英語)やLangChainなどの最新フレームワークを活用するための包括的な機能セットを提供することで、組織におけるチャットボットからエージェントへの移行(英語)を支援します。LLMスターターキットをご覧いただき(英語)、LLMの構築方法を学ぶとともに、さまざまなLLM関連の事例を探索しながら、独自の高度なLLMチェーンの構築を開始することができます。
ReActのようなAIフレームワークは、推論と行動を組み合わせることで機能します。具体的には、まずAIエージェントが(文書やプロンプト、その他のコンテンツ生成からの文脈を考慮しながら)最適なアプローチについての推論プロセスを実施し、その推論結果に基づいて次の行動をとります。このプロセスにより、AIエージェントが使用するツールは論理的な推論の流れに従い、より高品質なレスポンスとアクションを実現します。
自社のデータでLLMをファインチューニングする
皆様は、自社の内部文書によってLLMをファインチューニングするという対応が、明白な次のステップだとお考えかもしれません。従来のモデルに慣れ親しんでいる人々にとっては、それがまさに聖杯のように思えるからです。しかし注意が必要です。この方法にはそれなりの課題がつきまといます。
まず、ファインチューニングは非常に多くのリソースを必要とします。単に計算コストの問題だけでなく、バランスの取れたトレーニングデータセットを構築するための時間や専門知識も不可欠となります。さらに、新しい文書や変更が発生するたびに、モデルの頻繁な更新が必要になります。
次に、ファインチューニングは学習という観点では諸刃の剣と言えます。対応が行き過ぎると、モデルは一般的な知識を忘れ、業界の専門用語に過度に特化してしまう可能性があります。一般的な知識を保持しつつ、特定の文書の詳細を習得するというバランスを取るのは、決して容易ではありません。
最後に、たとえファインチューニングされたモデルであっても、その出力情報については依然として検証が必要です。情報源を明示するRAGとは異なり、ファインチューニングされたモデルでは、回答がハルシネーション(幻覚)でないことを利用者側が確認する必要があるからです。
とは言うものの、ファインチューニングにメリットがないわけではありません。例えば、モデルに新しい文体を学習させたり、特定分野の専門用語や業界用語、そして文脈をより深く理解させたりするなど、特定のニーズに対しては効果的なアプローチとなり得ます。このため、Dataikuはビジュアルコンポーネントとコードベースのコンポーネントの両方を提供することで、オープンソースのローカルモデルでも、LLM APIサービスでも、LLMを特定の目的に合わせてファインチューニングするためのプロセスを簡素化します。
大規模言語モデル(LLM)に適したAIツールの組み合わせ
現代の複雑なデータの世界において、データ活用の取り組みは、一本のまっすぐな道を進むというよりも、多様で入り組んだ地形を巧みに進んでいくといったものになるでしょう。すべての課題に対応できる単一の万能ツールは存在しません。その代わり、さまざまなデータ環境に直面した際にそれぞれが独自の強みを発揮できるよう、各機能が連携して動作する汎用性の高いツールキットが必要となるのです。
この先駆的な取り組みを進めるにあたり、私たちは責任あるAI(Responsible AI)の実践も同時に育んでいかなければなりません。バイアスの監査、透明性の確保、そして人間による監督体制の確立を着実に行うことが重要となります。適切なツールと健全な原則を統合することで、さまざまなデータソース間での知識統合の方法を再構築し、倫理的で一貫性があり監査可能なインサイトを提供できるようになります。進むべき道は無限の可能性を秘めていますが、その中で私たちを導くためには、責任あるAIの価値観をともなう洗練されたツールキットの採用が不可欠です。では素晴らしい第一歩は、どこから踏み出せばよいでしょうか?Dataikuが提供するこのEBOOKでは、AIにおけるリスクを探るとともに、従来型AIと生成AIの両方に適用可能な責任あるAIのための「RAFT(Reliable、Accountable、Fair、Transparent)」フレームワークをご紹介しています。
大局的に見れば、広大なデータの宇宙では、私たちはあくまでその中を旅する探求者にすぎません。しかし、堅牢なツールキット、イノベーションの精神、そして責任あるAIへの確固たる取り組みを備えた私たちは、これからの道筋を歩むために十分過ぎるほどの準備ができています。旅は続いており、その行き先に何が待っているのかを、私たちは心から楽しみにしています。
以上、強力なツールキットのひとつであるLLMが、もっとも困難なデータ課題の解決にどのように役立つかをご覧いただきました。次のセクションでは、LLMを企業活動の一部としてもっともよく活用するための方法、つまりこのAI分野が実際にどのように活用され得るかを示す、もっとも具体的なアプリケーションについて見ていきます。
結論:いまこそが大規模言語モデルを構築する好機
LLMは、NLPをはじめとする各分野で前例のない能力を発揮し、私たちのAIとの関わり方や活用方法に革命をもたらしました。APIを活用して迅速な統合を行う場合でも、またオープンソースモデルを管理してより高度な制御を実現する場合でも、これらのモデルの仕組みや、導入におけるベストプラクティスを理解することは極めて重要です。
企業がこれらの技術を探求する中で、プロンプトエンジニアリング、RAG、インストラクション駆動型クエリなどのツールは、LLMの潜在能力を最大限に引き出しながらリスクを軽減するために不可欠な存在となっています。これらの戦略を統合することで、企業はLLM力を最大限に活用し、膨大なデータを実用的なインサイトへと変革することが可能になります。
