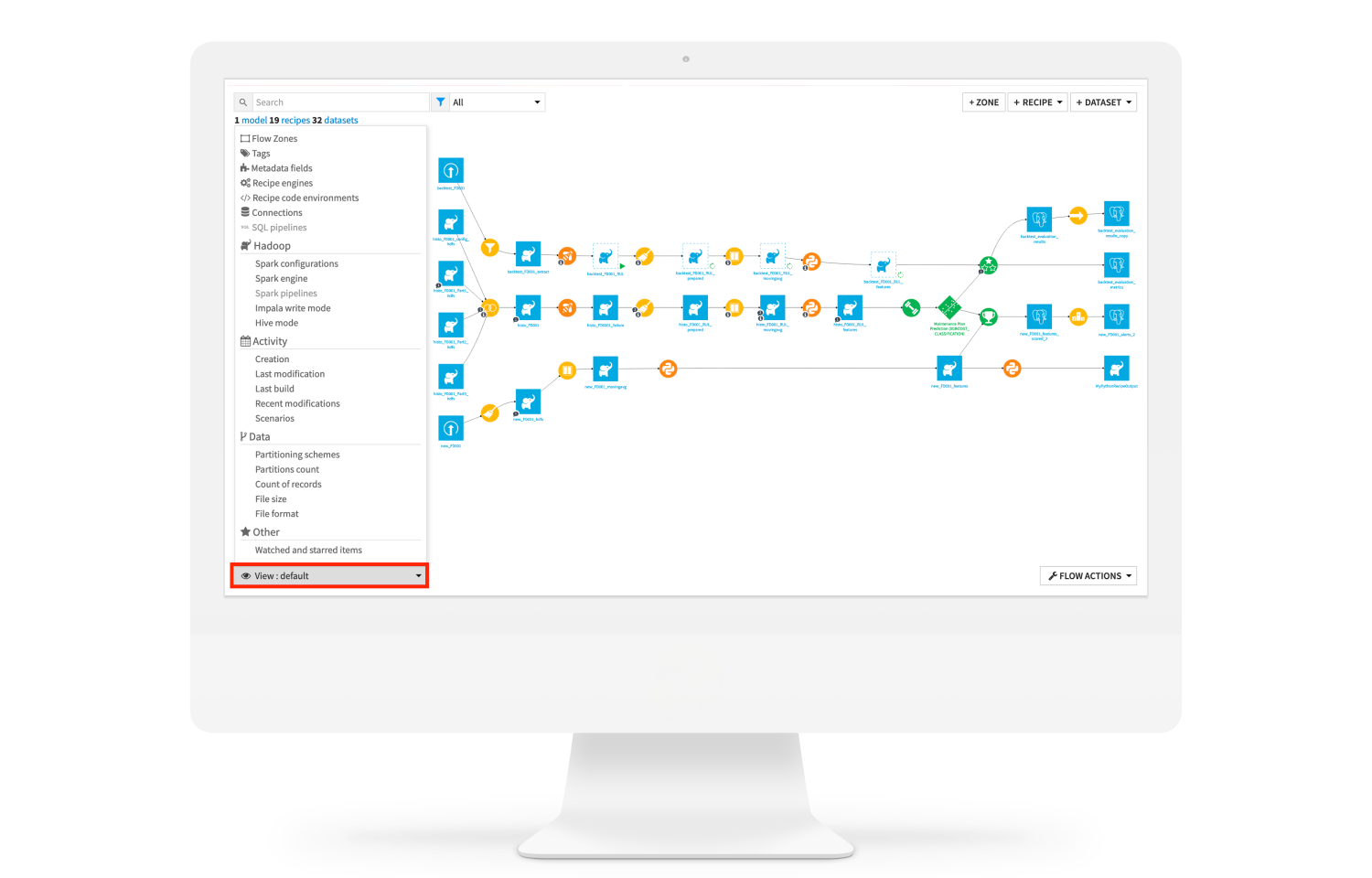
フローでデータパイプラインを可視化、管理
Dataikuのフローは、データパイプラインを視覚的に表現することで、複雑なワークフローの設計、理解、管理を直感的に行えるようにします。フロー上の各ステップは、データの取り込みから変換、加工までの処理を表しています。
スマートな操作機能(例:レシピの挿入、削除と再接続)により、Flowの編集も簡単。パイプライン全体を明確に把握できるため、チームは迅速に問題を解決し、プロセスを最適化することができます。
Learn About the Dataiku Flow