
AutoMLで迅速な開始と高速化を実現
Dataikuは、迅速なプロトタイピングのためのAutoMLのシンプルさと、高度な視覚的ML機能を組み合わせ、洗練されたモデルを素早く作成できます。
予測、クラスタリング、時系列予測から因果MLやコンピュータビジョンまで、データサイエンティストもアナリストも、本番環境対応のモデルをホワイトボックスの説明可能性を備えながら、迅速に構築、比較できます。
DataikuのAutoML機能の詳細はこちらDataikuは、迅速なプロトタイピングのためのAutoMLのシンプルさと、高度な視覚的ML機能を組み合わせ、洗練されたモデルを素早く作成できます。
予測、クラスタリング、時系列予測から因果MLやコンピュータビジョンまで、データサイエンティストもアナリストも、本番環境対応のモデルをホワイトボックスの説明可能性を備えながら、迅速に構築、比較できます。
DataikuのAutoML機能の詳細はこちら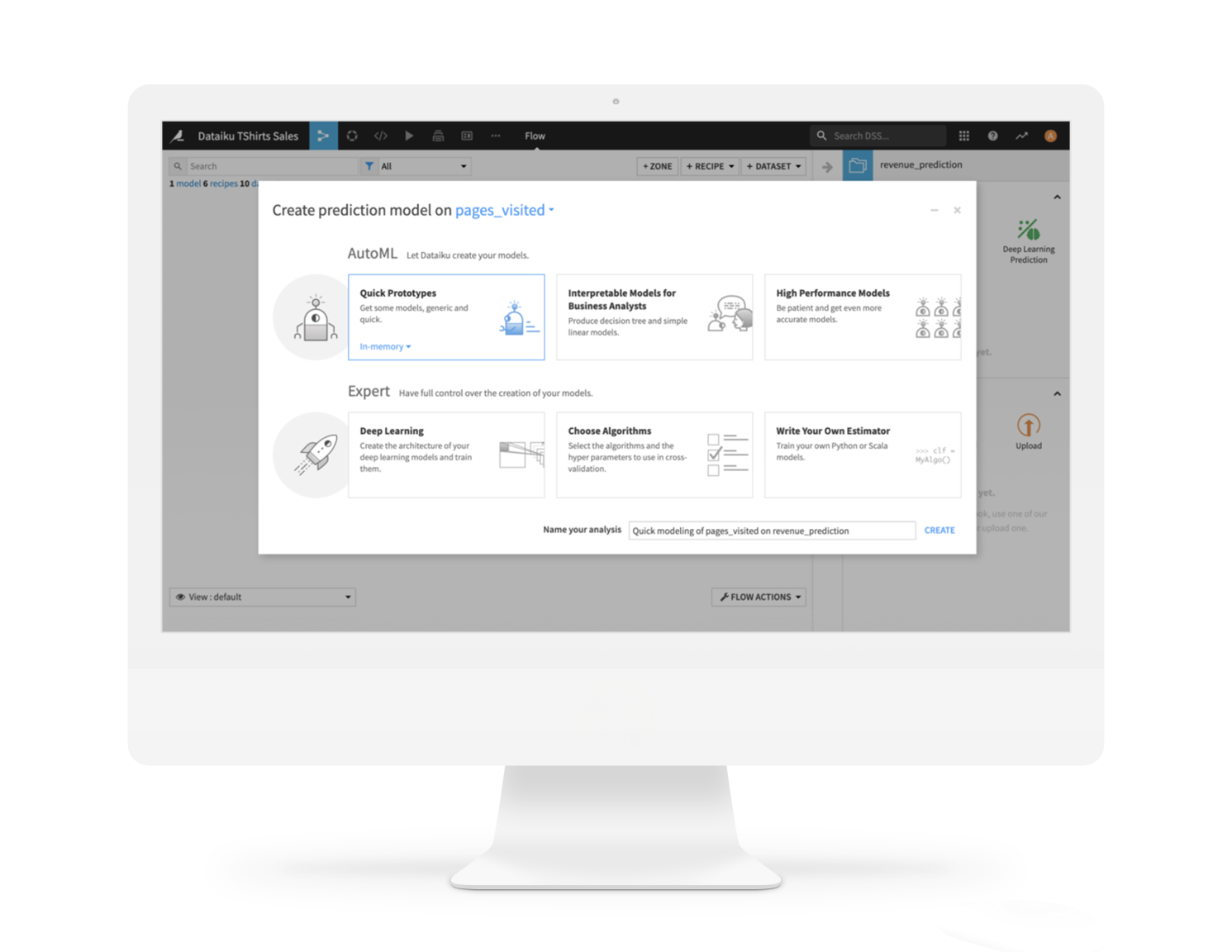
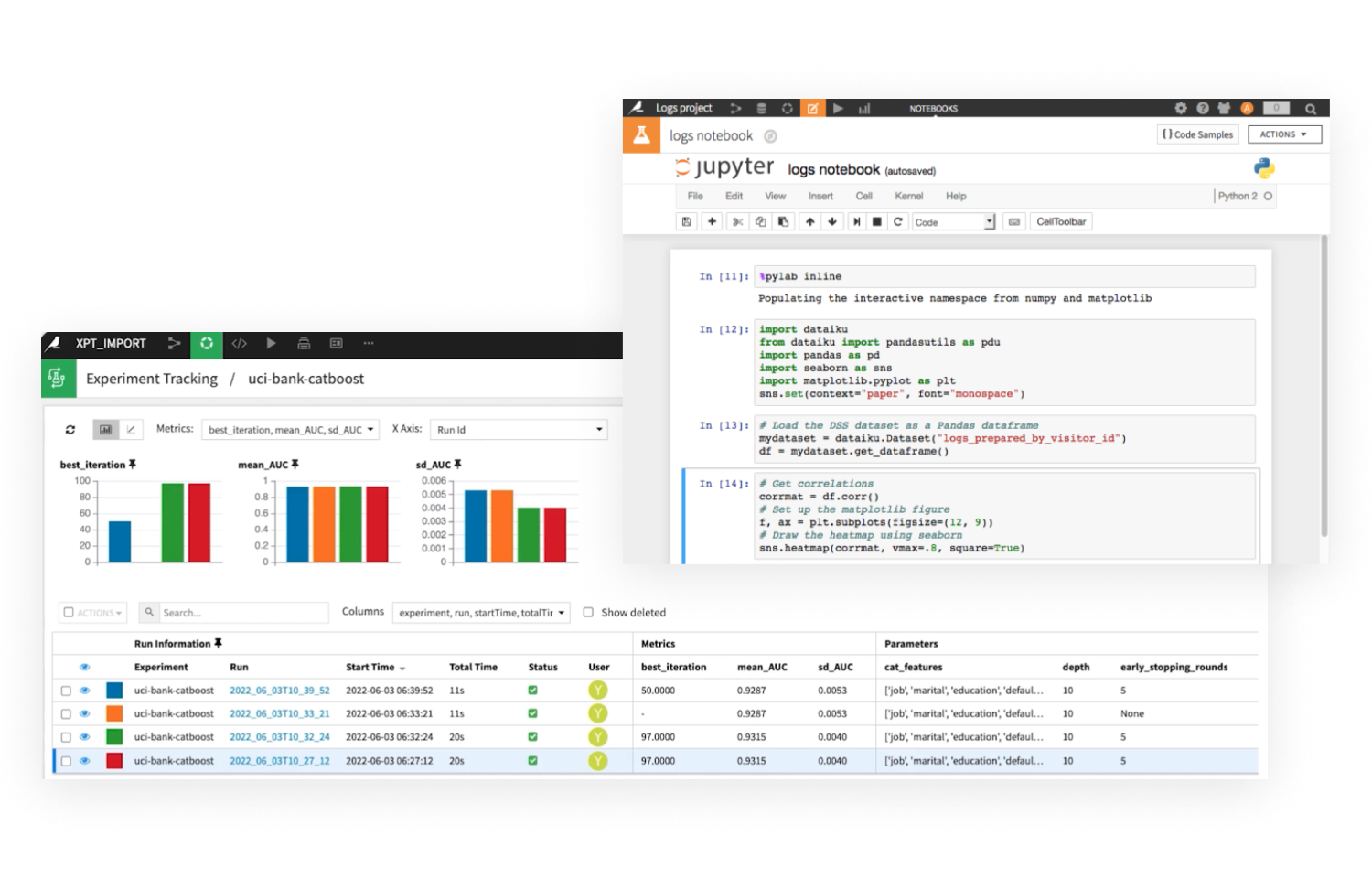
上級データサイエンティストは、プログラムによるカスタムモデルの開発(Python、Rなどの言語を使用)や、MLFlowで開発されたモデルのインポートが可能です。
外部モデルをチーム全体に可視化、解釈可能にするため、DataikuはMLFlow実験やCloudMLモデルの詳細を取得し、自動的にモデル比較と説明可能性レポートを提供します。
概して、私たちはDataikuが大好きです。私たちには、AutoMLやビジュアルツールを好む人と、コード作業が好きなデータサイエンティストが混在しています。
しかし、それがDataikuの良さであり、私たちがDataikuを選んだ理由でもあります:
しかし、それこそがDataikuの良さであり、私たちがDataikuを選んだ理由でもあります。素早いモデルが必要なら、それも可能です。
"Ben Powis
Ayca Kandur
Jennifer Garcia
Dataikuの使い慣れたモデル設計、デプロイメント、ガバナンス体験により、データプロジェクトやビジネスアプリケーションの一部としてディープラーニングを容易に組み込めます。
KerasとTensorflowによるカスタムディープラーニングアーキテクチャの定義、または画像分類やオブジェクト検出などのコンピュータビジョンタスクのための事前学習済みモデル、転移学習、ノーコードインターフェースを活用できます。
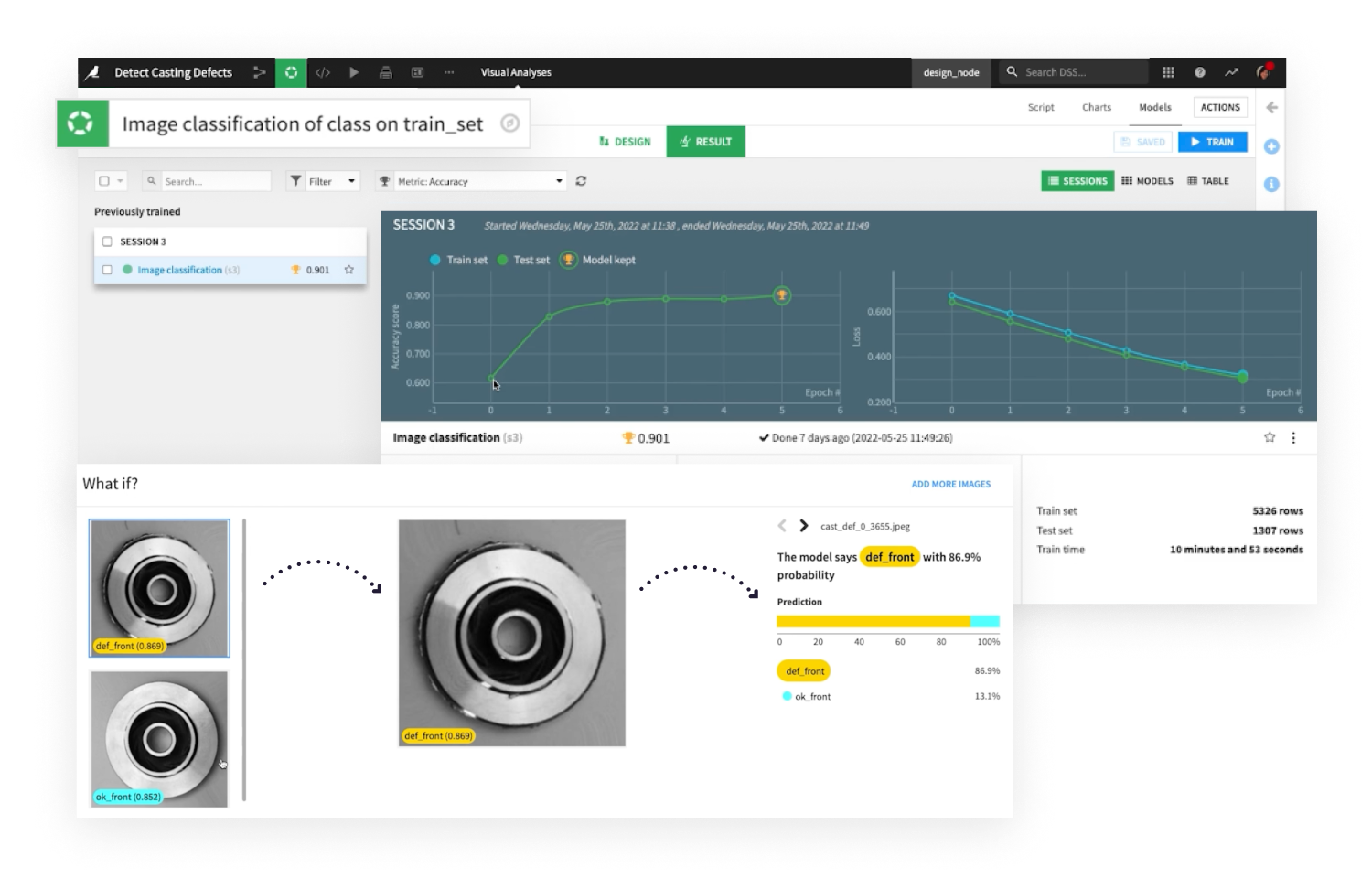
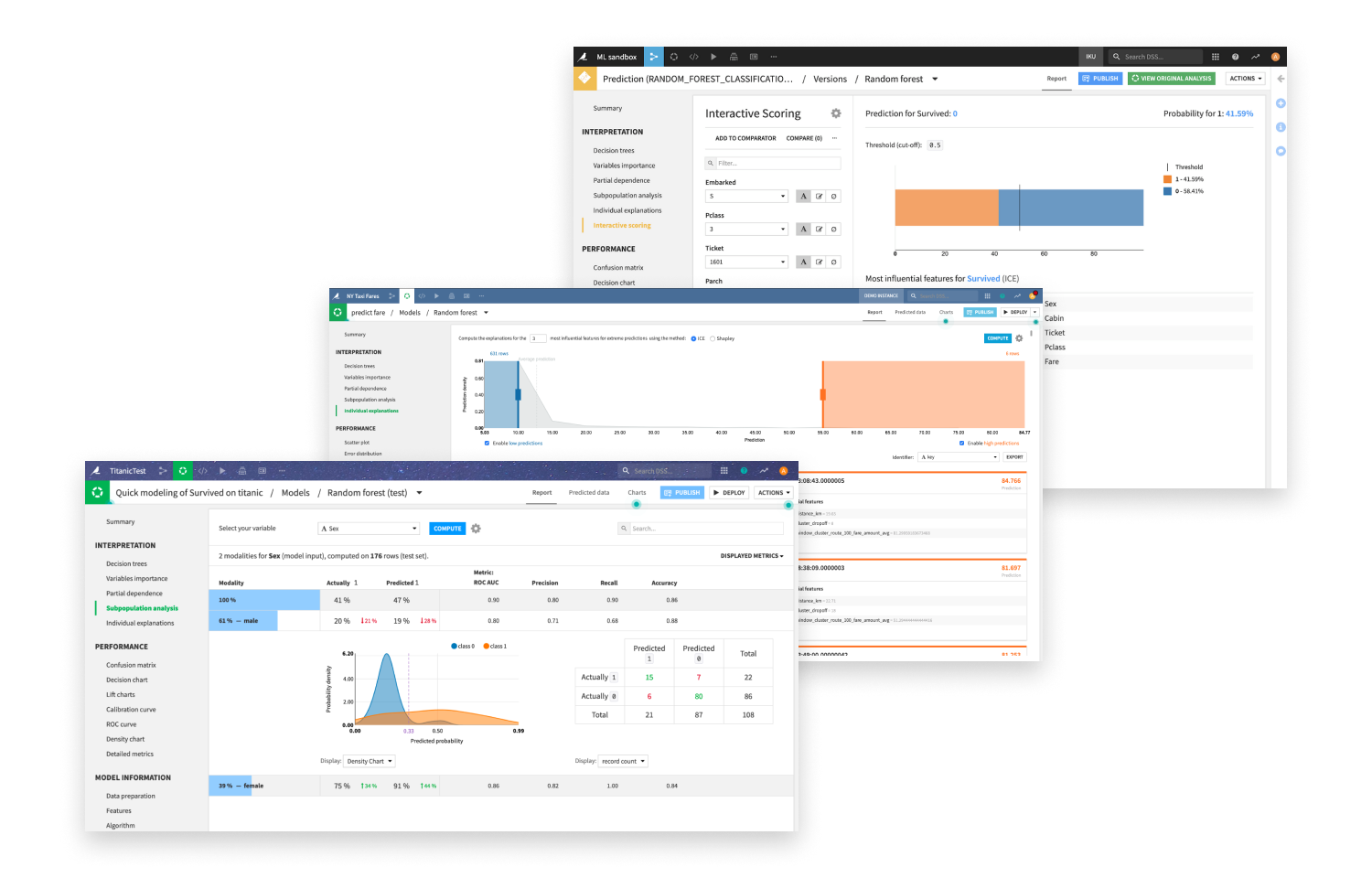
Dataikuの堅牢な説明可能性機能により、技術者と非技術者の双方が機械学習モデルの結果をより深く理解できます。
公平性分析、what-if分析、ストレステストなど、インタラクティブなパフォーマンスと解釈レポートの包括的なセットを提供します。
Dataikuは、信頼性の高い高品質なMLモデルの構築だけでなく、デプロイ、モニタリング、管理に必要なすべてのツールを提供します。
モデル比較からドリフト検出、モデル再学習まで、そしてさらに多くの機能により、真のスケールでのML展開を実現します。
DataikuのMLOps機能について詳細はこちら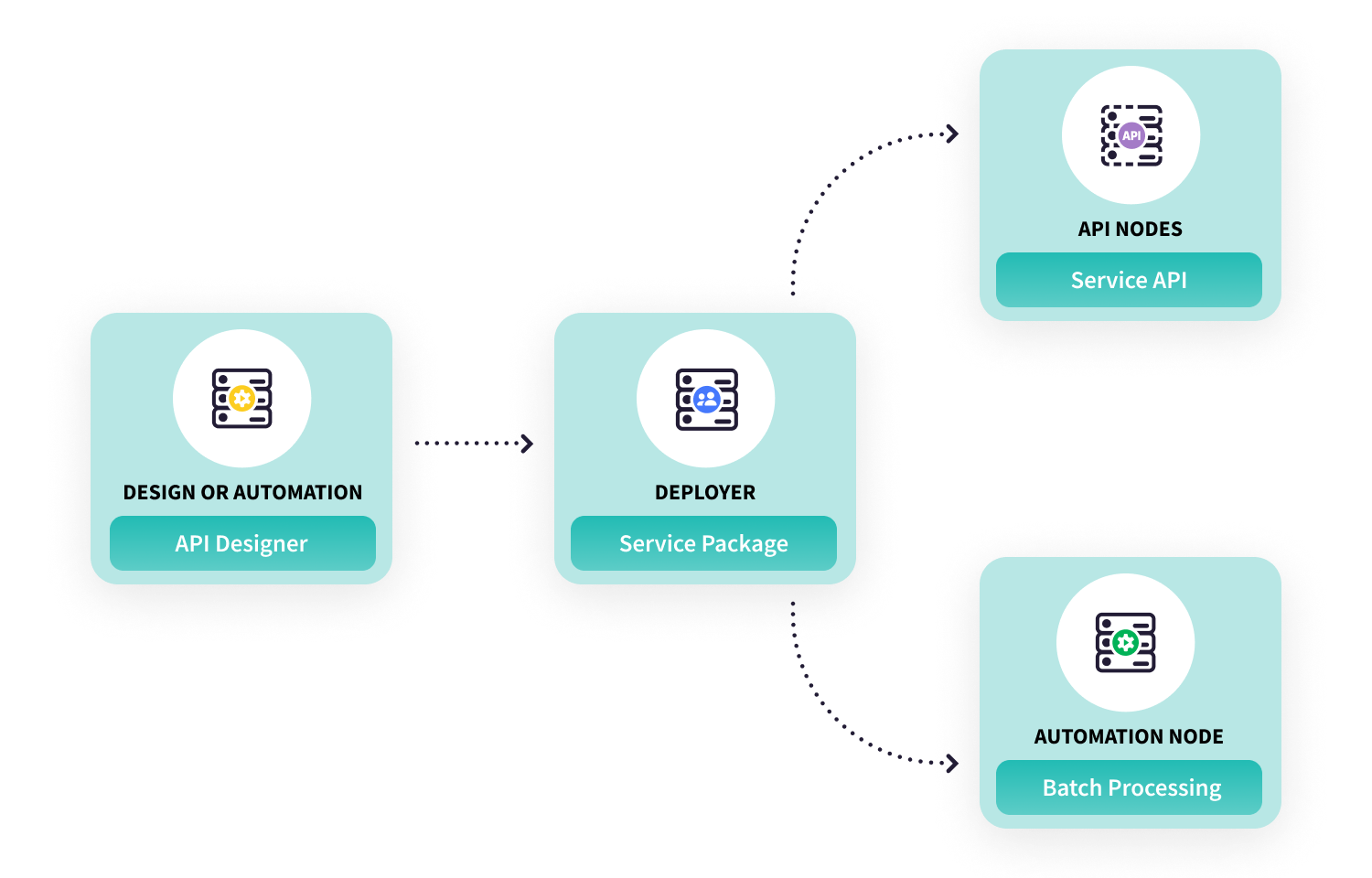
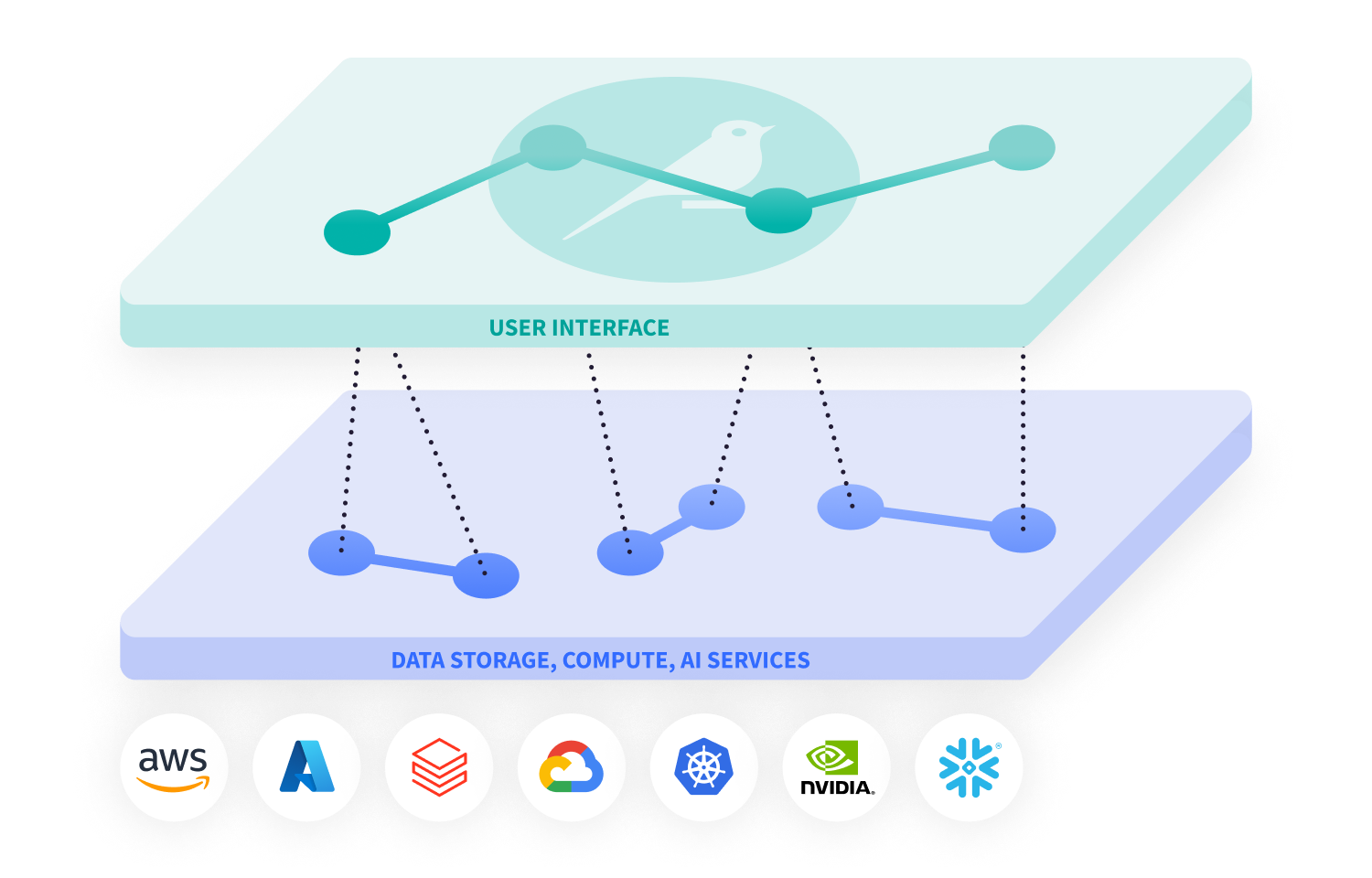
大規模な計算やモデルトレーニングジョブのために、Dataikuは選択したクラウド上でSparkとKubernetesを活用したオンデマンドの弾力的なリソースで、ワークロードを自動的かつ効率的にスケールできます。
事前設定された完全管理型クラスターがコンテナ化インフラストラクチャの複雑さを抽象化し、バックエンドリソースの設定に時間を費やすことなく、本来の作業に専念できます。
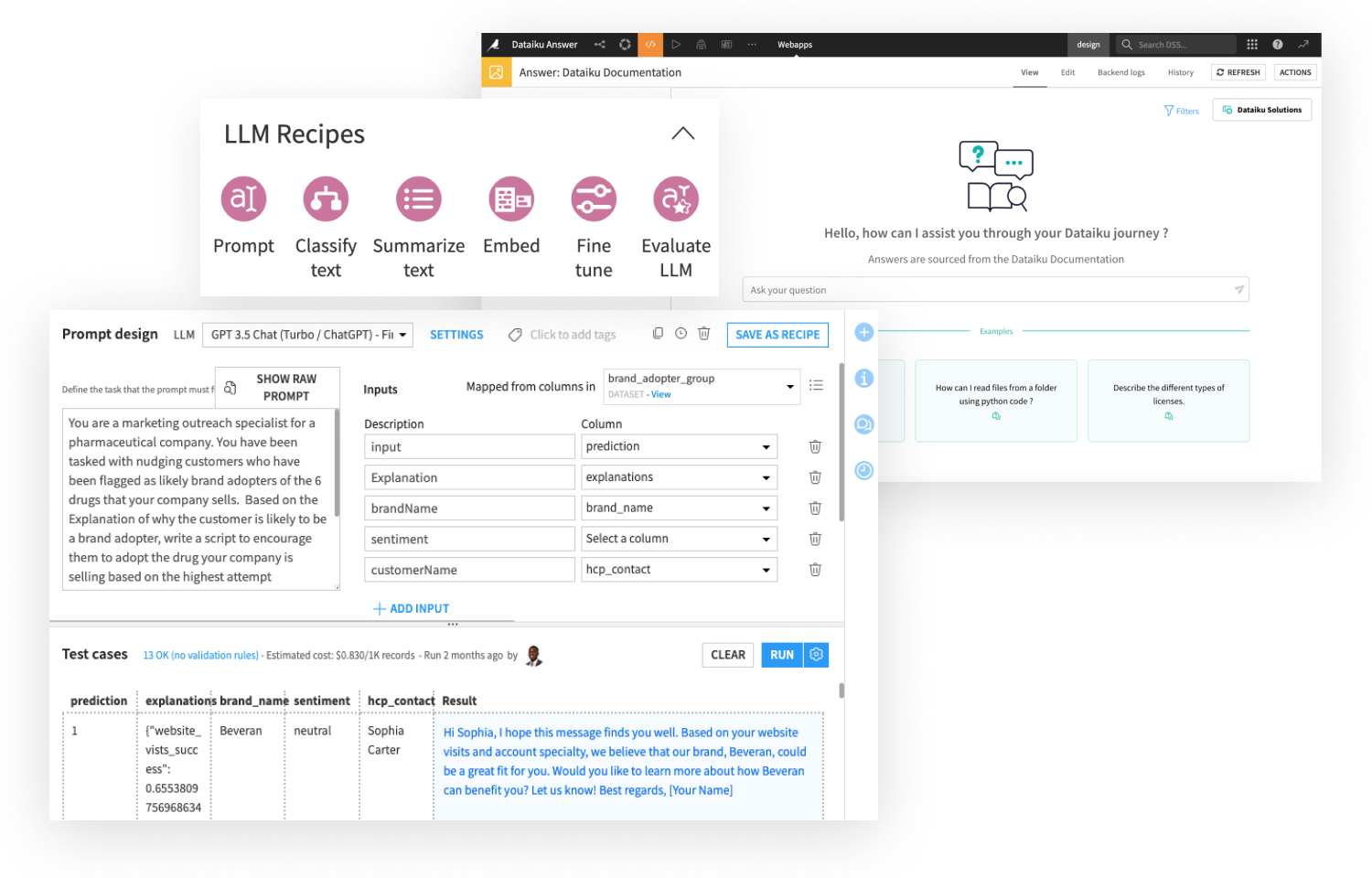
READ THE PUSHDOWN COMPUTATION BLOG POSTユニバーサルAIプラットフォームとしてのDataikuの強みは、従来のMLと生成AIベースのアプリケーションを、すべて一つの場所で構築できることです。Dataikuにおける生成AIのビルダーツールには以下が含まれます:

Prologis democratized AI with Dataiku, leveraging AutoML features to enable more than 2,000 analysts to build and deploy models with no coding knowledge for a 12x increase in productionalized projects.
Dataikuのおかげで、Regeneronは迅速な実験のための確立されたAIと機械学習のテストベッドを持っています。さらに、データ専門家と非データ専門家のどちらもDataikuを使用し、協力することができるため、Regeneron社は、研究開発に従事するウェットラボの科学者、データサイエンティスト、そして協同作業を心掛ける計算の専門家を適切に組み合わせることができます。
Dataikuは、データ分析、操作、モデリング作業を合理化、簡素化することで、Daviviendaに大きな利点を提供し、結果として、私たちの金融機関におけるポートフォリオ管理と回収の課題に対処するための、より洗練された効果的なソリューションを提供します。
Marc O'Poloのデータサイエンティストチームは、Dataikuを活用して、印刷広告の最適化のための高度なアップリフトモデリングを実験しました。最終的には、「見込みのある」お客様にダイレクトメールを送ることで、コストを削減してビジネスにインパクトを与えることができました。

Kapital Bank built a behavioral scoring model in Dataiku that was 3x faster than previous legacy models to identify small- and medium-sized businesses for which to provide loans.