データとAIのガバナンス:その意味と正しい実践方法
なぜ組織にガバナンスが必要なのか
ほぼすべての主要業界において、企業はこれまで以上に高度な分析やAI駆動のデータプロセスへの投資を進めています。これは歓迎すべき動きである一方で、可視性、AIの制御、プロセス管理に関する大きな課題も生じさせています。複数のチームがデータからインサイトを導き出したり、生成AIの活用に取り組んだりする中で、包括的なドキュメンテーションやモニタリングの管理、さらに運用上または法的なリスクの軽減がますます困難になっています。
このような背景から、データおよび分析の関係者に加え、ビジネス部門およびIT部門のリーダーたちも、ガバナンスのプロセスとその機能に強い関心を寄せるようになっています。AIプラットフォームは、データエンジニアからビジネスアナリストまで、組織全体のあらゆるメンバーが協働し、責任の所在が明確な体制のもとで業務を行える手段として登場しました。モデルに対するちょっとした調整から重要な承認プロセスまで、適切に構築されたガバナンス運用は、分析またはAIプロジェクトのあらゆる段階について、すべての関係者に可視性を提供すべきです。
なぜデータとAIのガバナンスが重要なのでしょうか? また、データとAIのガバナンスとはどのように定義されるのでしょうか? その前に一歩立ち止まり、なぜガバナンスがこれほど重要になっているのかを改めて見てみましょう。ニーズや課題を明確に理解していなければ、ビジネス目標を反映した適切なフレームワークを構築することはほぼ不可能です。以下は、組織に強固なデータとAIのガバナンスが必要とされる主な理由5つです。これらのカテゴリーは、自社のAIおよび企業全体のデータとAIのガバナンスフレームワークを構築する際の優れた出発点にもなります。
データの品質と一貫性の確保
データは現代のビジネス意思決定の中心にあるため、すべてのチームで使用される情報が正確で信頼性が高く、一貫性のあるものであることが極めて重要です。データの品質が低ければ、誤ったインサイトや方向性につながり、企業にとって時間とリソースの損失になります。ガバナンスは、データ品質に関する基準を明確に定義し、一貫して適用することで、関係者が信頼できるデータに基づいて安心して意思決定を行えるようにします。
さらに、ガバナンスのフレームワークは、データの更新、修正、不整合を管理するためのプロセスを確立します。これにより、異なるチームが矛盾するデータを使用して混乱や認識のズレを引き起こす「データのサイロ化」を防ぐことができます。ガバナンスを通じてデータの品質が維持されていれば、組織は分析やAIの取り組みからより大きな価値を引き出すことができます。
一方で、ツール間でデータ定義が異なるといったデータ品質の問題は、ビジネスインテリジェンス(BI)やデータサイエンスの取り組みにおいて不正確さを引き起こし、結果として企業が誤った戦略的プロジェクトに注力してしまう可能性があります。
法的リスクおよびコンプライアンスリスクの軽減
データのプライバシーやAIシステムに関する規制が進化し続ける中、組織は抽象的な理念から実行へと移行し、ガバナンスプログラムを大規模に展開する必要があります。本記事では特定の規制の詳細には踏み込みませんが、ひとつ確かなのは、組織がますます厳しい監視の目にさらされているということです。規制に違反すれば、重い罰則や法的措置、さらには企業の評判を損なうリスクがあります。たとえば、データが適切に保護、分類されていない場合、カリフォルニア州消費者プライバシー法(CCPA)や医療保険の相互運用性と責任に関する法律(HIPAA)、EU AI法、一般データ保護規則(GDPR)などのプライバシー規制に抵触し、多額の罰金や評判の悪化を招く可能性があります。ガバナンスのフレームワークは、こうした規制要件に先手を打って対応するために不可欠であり、データやモデルの取り扱いにおける実践を標準化し、適切に文書化することを可能にします。
ガバナンスのプロトコルを導入することで、組織はデータに関する意思決定に対する明確な責任の所在を確立することができます。これには、定期的な監査の実施、データ使用状況のモニタリング、コンプライアンスの証明に必要なエビデンスの提供などのプロセスが含まれます。ガバナンスの実践がデータやAIのワークフローに組み込まれていれば、規制要件の変化に伴うリスクをより効果的に管理することが可能になります。
データとAIの責任ある活用の推進
適切なガバナンスは、コンプライアンスを超えて、データとAIの利用における倫理的な配慮にも対応します。これにより、組織は責任あるAI開発のためのガイドラインを策定し、バイアスを軽減し、データが倫理基準や社会的期待に沿って活用されることを確保できます。
組織全体で価値観や倫理観を明確にすること自体が、大きな課題となります。Dataiku独自の責任あるAIのためのRAFTは、より大きなガバナンスフレームワークの重要な一部となり得ます。こうした前向きな姿勢は、AIの取り組みにおける透明性や説明責任を顧客、投資家、規制当局がますます求めるようになっている今、特に重要です。
AIモデルのライフサイクルを管理下に置く
AIモデルのライフサイクル(開発からデプロイ、その先まで)を管理することは、大きな課題を伴います。ガバナンスがなければ、モデルのバージョン管理、適切なドキュメンテーション、パフォーマンスのモニタリングが一貫性を欠いたり不十分になったりする恐れがあります。ガバナンスのフレームワークは、バージョン管理や監査証跡、継続的なモニタリングを徹底することで、AIライフサイクルに構造を与え、透明性と責任の所在を維持するのに役立ちます。
また、ガバナンスは、新しいデータの登場に応じてモデルを再学習や更新するためのプロトコルを定めることで、モデルの有効性と妥当性を長期的に維持することを可能にします。これにより、企業はビジネス環境の変化に迅速に対応できるようになり、古くなったり性能の低いモデルに伴うリスクを最小限に抑えることができます。効果的なガバナンスを通じて、企業はAIライフサイクル全体をより適切に管理し、AI投資のリターンを最大化することができます。
チーム間のコラボレーションを円滑化する
複数のチームがデータやAIの取り組みに関与する場合、連携のズレによって進捗が遅れたり、サイロ化が生じたりすることがあります。ガバナンスを導入することで、構造的なアプローチが可能となり、多様な役割のメンバーが効率的に連携しながら、プロジェクトの進行に対する責任の所在と可視性を維持することができます。
たとえば、各事業部門に所属するチームがそれぞれ独自のガバナンス体制を持っていたり、一部のチームは独自のアプローチをとり、他のチームは戦略なしに運用していたりする状況を想像してみてください。こうした状況は決して珍しいものではなく、「分散型構造」や「フェデレーテッドアプローチ(連合型アプローチ)」として、分析やAIの現場でよく見られます。そして、このアプローチは特に、データやAIのリソースが特定の業務機能に特化している場合には理にかなっています。たとえば、人事部門を支援する実務者と、顧客向け製品を担当する実務者とでは、求められる要件が大きく異なるはずです。
一方で、各事業部門に柔軟に対応しながらも、基本となるガバナンスアプローチを全社的に確立することで、一定の一貫性を生み出すことができます。その結果、エンタープライズ全体での効率性が向上し、プログラムのスケーラビリティや部門横断での理解が容易になります。たとえば、モデルのドリフトを監視するための標準化された方法や、プロジェクトやモデルに必要な情報、または新たなチャレンジャーモデルの立ち上げ方針などを必要とするデータサイエンティストやAIエンジニアが対象となるでしょう。
最終的に、データとAIのガバナンスを適切に実施することで得られるメリットには、データのサイロ化を解消し、組織全体で高品質かつ関連性の高いデータに安全にアクセスできるようにすることが含まれます。優れたデータとAIのガバナンスフレームワークと戦略を構築することで、企業はより良い顧客成果と業務効率の向上を実現できます。
エージェント型AIの活用に伴う懸念にどう対処するか
データガバナンスの標準とAIガバナンスの両方を備えることは、現代の組織にとって非常に重要ですが、それぞれが果たす目的は異なります。包括的なガバナンス戦略を策定するには、データガバナンスとAIガバナンスの違いを見極め、理解することが不可欠です。
近年、企業はデータカタログやデータインベントリ、データコレクションを通じて、データの一元管理と制御を進めてきました。一方で、AI(とくに生成AI)への関心は飛躍的に高まっています。機械学習(ML)モデルや分析プロジェクト、そしてそれらが活用されるユースケースの拡大により、より具体的かつ厳格なガバナンスが求められています。従来のデータガバナンスポリシーは、AI時代に必要とされる民主化された機械学習の運用には対応できないため、新たなガバナンスフレームワークが必要となっています。ここでAIガバナンスが重要な役割を果たします。
AIガバナンスとは何でしょうか?データガバナンスの役割はどのように定義されており、なぜデータガバナンスとデータマネジメントの違いが重要なのでしょうか?データガバナンスの運用モデルとは何であり、それはAIガバナンスとどのように異なるのでしょうか?以下に、理解しておくべき4つの主な違いを紹介します。
データガバナンスとAIガバナンスにおけるガバナンス範囲の違い
データガバナンスのプロセスは、組織におけるデータの可用性、利便性、完全性、安全性の管理に重点を置いています。その目的は、データの正確性と一貫性を確保し、規制や社内ポリシーに準拠しながら責任を持って活用されるようにすることです。主な機能には、データ品質管理、データセキュリティー、メタデータ管理、データスチュワードシップ、データライフサイクル管理が含まれます。
一方で、AIガバナンスはAIプロジェクトの開発およびデプロイに関するプロセス、ポリシー、管理体制を監督します。AIの取り組みを組織の目標と整合させるために、ルールやプロセス、要件を調整、徹底する役割を担います。主な活動には、モデルのドキュメンテーション、リスク管理、バイアスと公平性の評価、監査可能性、AIシステムにおける責任の所在などが含まれます。
データガバナンスとAIガバナンスはいずれも、組織全体で適切なフレームワークとベストプラクティスを徹底するという共通の目的を持っていますが、AIガバナンスはAIのスケール拡大に特化している点が特徴です。これは、データ品質ガバナンスや機械学習モデルの保守といった技術的課題から、AIの取り組みが拡大することで生じる非効率性、不透明性、リスクまでを含むものであり、MLOpsや責任あるAIの原則とも密接に関連しています。最終的には、データガバナンスとAIガバナンスは相互に影響し合う関係にあり、良好なデータガバナンスが優れたAIガバナンスを実現し、またその逆も然りです。
AIおよびデータの取り組みを拡大する中で、信頼性とコンプライアンスを維持するためには、両方のガバナンスフレームワークを理解し、実装することが組織にとって不可欠です。AIガバナンスとコンプライアンスは本質的により広範であり、データ保護コンプライアンスを超えて、バイアスの防止やモデルの説明可能性といった目的も含まれます。
データガバナンスとAIガバナンスにおける規制の境界
データガバナンスの役割や責任、ポリシーは、GDPR、DPA、CCPA、PIPEDAといった規制に基づいて策定されます。これらの規制や、その他の地域、業界特有のデータ保護法は、主にプライバシーやデータセキュリティーに焦点を当てています。一方で、AIガバナンスの原則は、AIを対象とした新たな規制によって定められています。たとえば、倫理的配慮やリスク管理に言及するEU AI法がその一例です。業界特有のアプローチも、AI固有の規制を補完する形で重要な役割を果たします。
なぜ規制が重要なのでしょうか? その理由のひとつは、規制が今やあらゆるところに存在するようになってきているからです。各国政府は、組織がAIを構築、購入、導入する方法を規定するために、規制的および非規制的な介入を進めています。たとえば:
- 米国では、NIST AIリスク管理フレームワーク、AI権利章典、安全かつ信頼できるAIの開発と利用に関する大統領令などが導入されています。2025年には政権交代の可能性もあり、AI規制はさらに断片的な形で施行されると予想されます。だからこそ、市場や規制環境の変化に柔軟に対応できる一方で、厳格な基準を備えたガバナンスフレームワークの重要性がますます高まっています。
- シンガポールのIMDAは「AI Verify」を発表しました。
- 英国はAI規制に関する政策文書を発表し、AI安全性研究所を設立しました。
- EU AI法は、リスクレベルに応じた要件と、それに伴う厳しい制裁を定めることで先例を築きました。EU AI法を理解し、その要件への準拠をガバナンスの実践を通じて管理することは、欧州で事業を展開するあらゆるグローバル企業にとって重要な要件となりつつあります。
データマネジメントとデータガバナンスおよびAIガバナンスの運用実装の違い
一般的に、データガバナンスのロードマップは、データポリシー、中央集約型のデータカタログ、データスチュワードシップ、データ品質管理プロセスを通じて実装されます。一方で、AIガバナンスの計画はより複雑で、多様な目的を含みます。これには、倫理的ガイドラインやリスク評価フレームワーク、運用効率の評価、承認や合意のワークフローを通じた価値のモニタリング、AIアプリケーションの可観測性システムなどが含まれます。
データガバナンスの計画を持っていることと、より包括的なAIガバナンスの計画およびフレームワークを持っていることを混同しないことが重要です。実際、AIガバナンスのフレームワークは、データセットのカタログ化とは明確に区別されるべきです。AIの開発と導入における誤りを防ぐためには、ルールの順守と運用上の実装が求められます。これは、AIを安全にスケーリングし、ガバナンスフレームワークの不遵守による後退を回避するうえで極めて重要です。
大規模言語モデル(LLM)を基盤とするAIエージェントや生成AIアプリケーションには、データ漏えいや幻覚(ハルシネーション)、有害な出力といったリスクに関連する波及的な影響を防ぐため、追加のガバナンス対策が求められる可能性があることにも留意すべきです。
データガバナンスとAIガバナンスにおける関係者の違い
データガバナンスのプログラムには、データスチュワード、データチーム、IT部門、コンプライアンス担当者、ビジネスユーザーなどが関与するのが一般的です。一方で、AIガバナンスの関係者はより広範にわたることが多く、幅広い関係者の参加が求められます。これには、データサイエンティスト、機械学習エンジニア、AIエンジニア、リスクマネージャー、倫理専門家や法務アドバイザーに加え、ビジネス領域の専門家などが含まれます。
これらすべての関係者がデータおよびAIガバナンス計画に関与する中で、シームレスな連携は成功のために不可欠です。AIモデルの急速な普及を踏まえると、ビジネスチームはIT部門、データサイエンスチーム、マネージャーやリーダーと連携し、進行中のプロジェクトやパフォーマンス、ステータスに関する可視性を共有できる統合プラットフォーム上で、AIモデルのガバナンスを実現する必要があります。これにより、効果的な優先順位付けと意思決定が促進されます。
さらに深く理解する
共通するデータおよびAIガバナンスの課題
AIガバナンスとデータガバナンスの課題には共通点が多くあります。たとえば、データフローやAIの意思決定における透明性とトレーサビリティーの確保は、信頼性とコンプライアンスの観点から不可欠です。また、両者はバイアス管理にも取り組んでおり、誤ったインサイトを防ぐためのデータ品質基準の策定や、AIモデルにおける公平性の担保も重要な課題です。さらに、継続的なモニタリングも共通の難題であり、規制の変化に対応しながら、データ利用状況の追跡やAIモデルの性能維持を通じて、責任の所在を明確にすることが求められます。
要するに、すべての企業がAIシステムやAIモデルを成功裏にスケーリングしたいと考えています。しかし、重要なのはAI技術やMLアルゴリズムに基づくアプリケーションだけではありません。サイロの解消やセルフサービス型のフレームワークの提供が不可欠となるデータの民主化でさえ、適切なガバナンスが必要なのです。
最終的な目標は、大量のデータから価値を創出または生成することです。同時に、コストを削減し、リスクを管理することも重要です。これらは非常に大きな課題であり、現代の組織においてスケールさせるのが極めて難しい目標です。その理由は:
- 組織には標準化されたプロセスが存在しないことが多く、各事業部門がデータプロジェクトを本番環境に移行するための独自の作業プロセスを持っている可能性があります。
- トレーサビリティーが低い傾向があります。正直なところ、自分の作業を文書化するのが好きな人はあまりいません。しかし、データパイプラインに関するドキュメントがなければ、成功に必要な監査証跡も得られないのです。
- IT部門には可視性が欠けています。複数の事業部門やチームが、それぞれデータやAIプロジェクトに取り組んでいることでしょう。中央でプロジェクトを監視できる仕組みがなければ、これから何が始まるのか、すでに本番環境で稼働しているのは何かを把握することができません。
データガバナンスのサービスやソフトウェアは、こうした課題の解決を支援することができますが、万能な解決策というわけではありません。次のセクションでは、データガバナンスのソリューションと、より大規模なAIガバナンス戦略へと展開するためのベストプラクティスについて解説します。
データ戦略およびガバナンスのベストプラクティス
効果的なガバナンスを実現するには、データとAIの管理それぞれに適した戦略的なアプローチが必要です。透明性、責任の所在、リスクの軽減といった課題や目標は共通していますが、AIガバナンスとデータガバナンスの具体的なベストプラクティスは、それぞれが抱える固有の課題に応じて異なります。
データガバナンスのベストプラクティス
強固なデータガバナンスのフレームワークテンプレートを構築することは一つの旅路であり、全体的な目標と明確に一致しているかを定期的に見直す価値があります。特に、優れたデータガバナンス戦略と強力なAIガバナンスは、最終的に表裏一体の関係にあるからです。ここでは、顧客や業界からよく聞かれる、一般的なデータガバナンスの柱や事例をご紹介します。
- 成功を測定する方法を理解し、目標の定義にはビジネス部門を巻き込む:優れたデータガバナンスモデルと戦略には、進捗を継続的に測定するための明確な指標やKPIが必要です。また、組織の整合性とポリシーの徹底を図るためにも、目標の定義にはビジネスリーダーの関与が欠かせません。
- データライフサイクル全体にわたって明確な役割と責任チームを定義する:データは静的なものではなく、さまざまな目的で異なるユーザーによって変換、クレンジング、削除などが行われます。だからこそ、すべてのデータ利用者に対して監査証跡やデータリネージを構築できる仕組みを整え、適切な人に責任を持たせることが重要です。
- データ制限を過度に強化しない:データアクセスのガバナンスや厳格な制限の導入は魅力的に思えるかもしれませんが、アクセスにボトルネックを設けることは、ビジネス全体のスピードを著しく低下させ、プロジェクトの失敗や競争に後れを取るといった新たな業務リスクを生みかねません。新たなポリシー制限を設ける前に、まずビジネス部門からデータの利用実態について情報を収集し、どのレベルでアクセス制限を設けるべきかを判断することが重要です。
AIガバナンスのベストプラクティス
分析およびAIガバナンスのフレームワークは、標準化されたルール、プロセス、要件を通じて組織の優先事項を徹底させます。こうした優先事項が、分析やAIの設計、開発、導入を方向づけることになります。自社のAIガバナンスの成熟度を考える際に自問すべき質問には、以下のようなものがあります。
- 自社のモデルにバイアスが存在するかどうかを検出する手段はありますか?
- 自社の倫理原則は何ですか?
- パイプラインのどの部分について誰が承認する必要があるのかを定義する、明確なプロセスはありますか?
- それらのモデルが本番環境に移行した後も、監視することは可能ですか?
これらの問いに対する答えは組織ごとに異なるため、AIガバナンスの枠組みも一様ではありません。しかし、これらの問いは模範的なAIガバナンスの枠組みを構築する出発点として適しています。
基礎的なガバナンスの問いから実践的な現実へと進めるには、強固な運用体制の構築が不可欠です。ここで重要になるのが、MLOpsの枠組み、さらにはDataOpsやLLMOpsを含むより広範なXOpsです。AIモデルを展開、監視、管理するための効果的な運用プロセスがなければ、どれほど精緻に設計されたガバナンスの枠組みであっても、理論の域を出ることはありません。
これらの運用システムは、ガバナンスの原則とその実践的な実装との橋渡しを担います。ポリシーの自動適用、モデルの挙動の追跡、データドリフトの監視などを実現します。この運用層は、基礎的なガバナンスの問いへの回答と組み合わさることで、組織固有のコンプライアンス要件、監査ニーズ、リスク管理の優先事項に直接対応する包括的なガバナンス枠組みを可能にします。このようにして構築される枠組みは、単なる理論にとどまらず、実際に展開されるモデルやそこから生じる現実的な課題に基づいて形作られ、機能するものです。
生成AI時代のガバナンス
AIガバナンスの未来は、生成AIとLLMを中心に展開しています。Dataikuが見ているのは、生成AIによって組織が従来よりも迅速にガバナンスについて考えるようになってきているということです。これまで以上に、組織はAIへの信頼を構築することを重視しています。そして、信頼は透明性、ドキュメント整備、そして絶えず進化する状況に対応したAIポリシーの整備によって実現されます。
もちろん、LLMの上に構築されたアプリケーションを従来の意味でガバナンスすることは重要です。つまり、適切な承認者が配置されており、パイプラインに対する適切な監視が行われているといった体制です。また、モデルのドキュメントを常に最新の状態に保ち、どのユースケースにどのモデルを使用すべきか(あるいはすべきでないか)を整理するために、LLMレジストリのようなLLM特有のガバナンスツールも有効です。しかし、生成AIにおいてさらに重要なのは、人間が介在する仕組みを持つことです。
生成AIやLLMアプリケーションにおいて人間を介在させる際には、何が妥当かを見極める必要があります。たとえば、顧客向けのAI生成メールのようにリスクの高いものでは、人間の関与が不可欠でしょう。一方で、他のプロジェクトではそれほど必要ないかもしれません。
堅牢な枠組みを構築するための必須データガバナンスツール
DataikuのようなAIプラットフォームは、データとAIのワークフローを管理するための統合ツールを提供することで、強固なガバナンス基盤の構築において重要な役割を果たします。これにより、既存のデータガバナンス原則の遵守を支援すると同時に、従来の機械学習やLLMを活用したアプリケーションを含む新たなAIガバナンスの枠組みを構築することも可能になります。
ガバナンスの観点から、テクノロジースタックが足かせではなく支援となるようにするために、AIプラットフォームに求められる主な機能をいくつかご紹介します。
中央監視タワー
プロジェクトに数十、あるいは数百もの可動要素が含まれ、データアクセス権限やコーディングスキル、目的の異なる複数のユーザーが同じプロセスやデータセット上で作業する場合、すべてをひとつの信頼できる情報源に集約することが不可欠です。企業がAIの取り組みを拡大していく中で、可視性を維持しリスクを軽減するためには、プログラムの中央集約的な監視が極めて重要となります。
Dataikuのようなプラットフォームを利用すれば、データおよびアナリティクスのリーダーやプロジェクトマネージャーは、複数のAIおよびアナリティクスの取り組みの進捗を一元的に把握でき、責任あるAIのライフサイクルアプローチを実現するために、適切なワークフローやプロセスが整っていることを確認できます。
AIプラットフォームは、AIおよびアナリティクス資産全体を見渡す中央監視タワーとしても機能すべきです。そして、その統合された視点から、どの資産に明示的なガバナンスが必要かを判断できるようにする必要があります。リスク管理者やデリバリーマネージャー、機械学習エンジニアなどのデータおよびアナリティクスの関係者にとって特に重要なのは、AIプラットフォームがモデルレジストリ、すなわち従来の機械学習モデルとLLMの両方を含む全モデルの一元管理を可能にすることです。
モデルの開発とデプロイを構成する多くの要素を見渡せる中央ハブがあれば、ガバナンスプロセスもまた、関係者がプロジェクトの価値とリスクを標準化された評価枠組みで判断できるようにすべきです。つまり、リスクを防ぐだけでなく、価値の創出と定量化を可能にすることが重要であり、これこそが優れたAIプログラムの核心です。
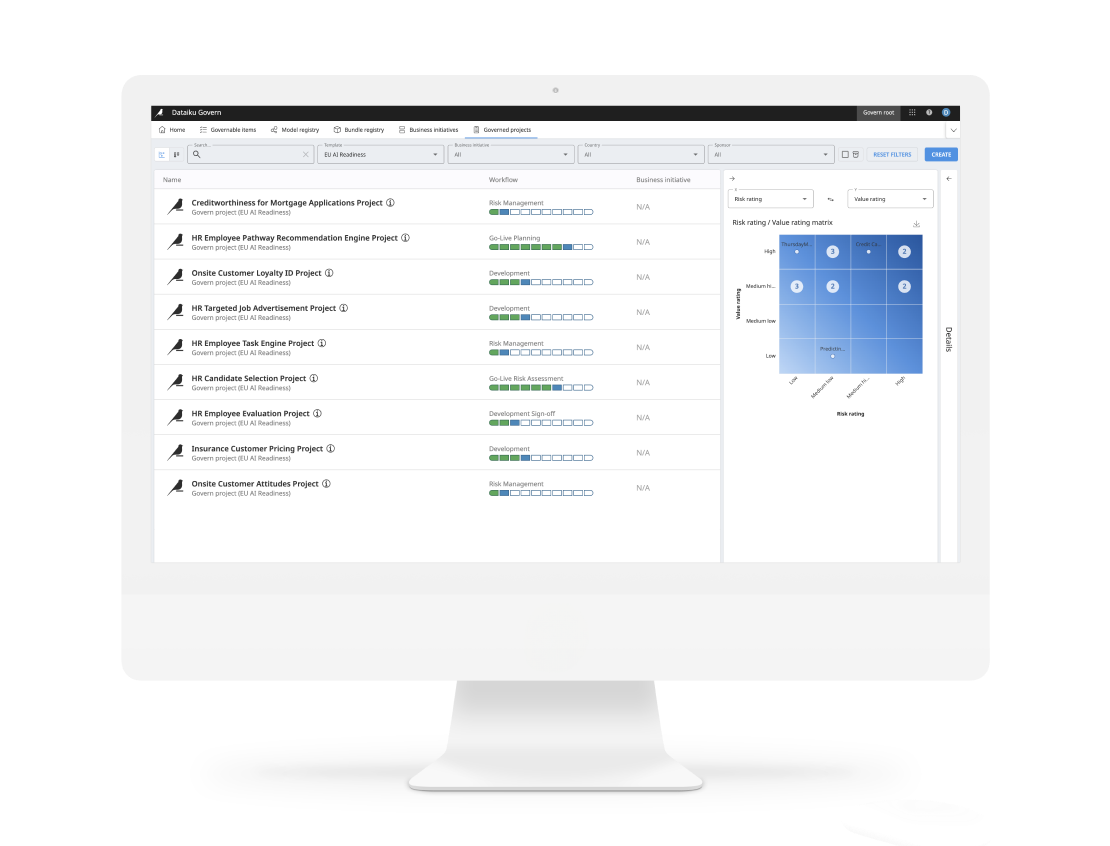
データとAIのガバナンスを統合するという観点からも、AIプラットフォームには共通のデータ資産を発見、理解、活用できる中央リポジトリが備わっているべきです。データカタログはアナリティクスにおいて不可欠な存在であり、データアナリスト、データサイエンティスト、データエンジニアなどが分析に適したデータを迅速かつ容易に見つけ出すのに役立ちます。
AIプラットフォームを活用して、カタログと最終段階のデータ、アナリティクス、AIの作業をより緊密に統合することで、以下のような主要な機能が得られます:
- データ探索:カタログを利用することで、組織内のすべてのデータ資産(データベース、データウェアハウス、ファイルシステムなど)を検索、閲覧できるようになります。データサイエンティストやデータアナリストは、必要なデータを迅速に見つけることができます。さらに、データエンジニアは、各プロジェクトでデータがどのようにデータパイプライン(Dataikuでは「フロー」と呼ばれる)で使用されているかを把握できます。
- データプロファイリングと品質評価:高度なデータプロファイリングおよび品質評価機能により、データアナリストやデータサイエンティストは、レポートやモデルにデータを使用する前にその品質を評価することができます。
- コラボレーションと情報共有:カタログには、データ実務者がデータ資産に関する知識やインサイトを共有できるコラボレーションおよび情報共有の機能が備わっています。
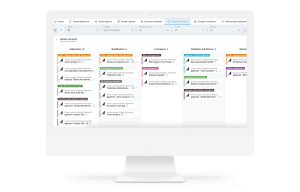
標準化されたガバナンス計画とワークフロー
各チームにはプロジェクトごとに固有のガバナンス要件があるとはいえ、適切にガバナンスされたワークフローを構築するたびに一からやり直す必要はありません。ユーザーは、すべてのビジネスイニシアチブにわたってプロジェクトのステータスを追跡し、AIへのアプローチを標準化し、プロジェクト計画を作成し、明確なステップとゲートを備えたワークフローブループリントを活用することで、各ガバナンス対象プロジェクトにおいて最適なスピードと価値でAIプロジェクトを探索、構築、テスト、デプロイできるようにすべきです。
プロジェクトオーナーは、自身のプロジェクトの目的、スコープ、想定されるユースケースを文書化し、共有できる必要があります。また、プロジェクトのビジネススポンサーの詳細やモデルのドキュメントなど、誰もが確認、レビューできる追加情報を添付できるようにすべきです。
Dataikuのようなプラットフォームを使用すれば、プロジェクトごとにガバナンスプロセスを柔軟に調整できる一方で、あらかじめ構築された計画やワークフローも利用でき、初期段階から運用を支援することが可能です。
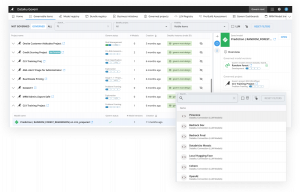
構造化された承認プロセスとサインオフ
レビューとサインオフは、優れたガバナンス運用の核心と言えるかもしれません。アナリティクスやAIプロジェクトに対してステークホルダーの承認を得ることは、管理や追跡が難しい場合もありますが、プロジェクトやモデルがビジネスニーズに合致し、監査可能であり、責任あるAIのベストプラクティスに従っていることを担保するためには不可欠です。
しかし、効率性と慎重さのバランスを取ることは重要でありながら難しい課題です。プロセスが複雑すぎて官僚的であれば、プロダクションに進むことはありませんし、スピード重視で設計されていれば、ミスが生じるリスクがあります。プロジェクトオーナーがモデルやプロジェクトバンドルを本番環境に昇格させる前に、サインオフを「依頼、収集できる」だけでなく「必須にできる」AIプラットフォームを選ぶべきです。これにより、透明性とスムーズさを維持しつつ、ボトルネックを最小限に抑え、デプロイに関する判断が常に監査対応可能な状態となります。
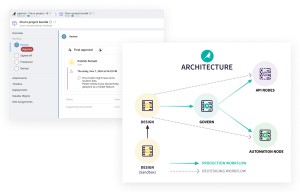
Dataikuによるガバナンス
優れたガバナンスは、家族に代々伝わる優れたレシピのようなものです。いくつもの重要な要素が必要で、それぞれが同じくらい重要であり、すべてが組み合わさることで真価を発揮します。しっかりと構築されたアナリティクスおよびAIの機能は、ユーザーが適切な監視のもとでAIを安全にスケールさせ、最も価値をもたらすデータプロジェクトやモデルを優先できるようにします。
Dataikuを活用した場合、貴社のガバナンスの取り組みやプロセスがどのようになるかを想像してみましょう:
- コンプライアンスやリスク要因は、プロジェクトの評価(英語)段階で明確に定義され、プロジェクトワークフロー(英語)全体を通じて体系的に追跡されます。モデルを本番環境へ移行する前には、レビューとサインオフ(英語)が必須です。各ステップには明確なタイムラインと責任が設定されており、ドキュメントもアップロードおよびカスタマイズしてコンプライアンス要件を満たすことができます。
- 機微データの評価は文書化(英語)され、中央で管理され、可視性とアクセス性の高いプラットフォーム上でサインオフ(英語)されます。必要に応じて(英語)適切なアクセス権限が設定され、適切な人物のみが該当データにアクセス、利用できるようになり、それ以外の人物には制限がかかります。監査用のドキュメントも中央で管理され、アクセス状況の監視が可能です。
- 技術的なモデルバリデーションはシナリオ(英語)を通じて自動化され、モデルドリフトも自動的にプラットフォームに取り込まれ、監視およびサインオフ(英語)が可能になります。評価に関するメールで適切な人物をCCに入れる必要も、メールを探したり他のドキュメントにリンクしたりする必要もありません。プロジェクトにアクセス権を持つユーザーであれば、Dataiku Governノード上でデータを確認できます。
- プロジェクトおよびモデルのポートフォリオに対するモデルレジストリは自動的に生成され(英語)、重要なメタデータも継続的に更新されます。ビューの詳細(英語)は、スポンサー、サインオフ、ドリフトメトリクス(英語)などのデータを含めてドリルダウンや展開が可能です。スプレッドシートの記入を促すリマインダーも不要になり、リストの更新状況に対する不確実性も解消され、プロセス全体が可視化、透明化されます。
AIガバナンスにDataikuを選ぶ理由
エンドツーエンドのモデル開発とガバナンスワークフローを統合し、データ専門家、ビジネス専門家、IT、コンプライアンス担当者を一か所に集約して、デリバリーのスピードを落とすことなくガバナンスを簡素化できるのは、Dataikuだけです。
2021年、DataikuはAIプロジェクトに対するコントロールと可視性を強化するために、専用のAIガバナンス機能「Dataiku Govern」をリリースしました。これらの機能は、同プラットフォームに備わるデータコントロールやデータコラボレーションの機能を補完し、データ共有を促進するとともに、組織がデータガバナンスとデータマネジメントを高度に実現することを支援します。
それ以来、Dataikuは新たに登場する規制枠組みに対応するために、その機能を拡充してきました。カスタマイズ性の高さと、価値実現までの時間を短縮するためのリソースにより、「Advanced Govern」は、EU AI法をはじめとする(英語)現在および将来の規制への対応準備を加速させるための最適なソリューションです。
Dataikuの高度なAIガバナンス機能は、既存システムと連携しながら本番環境のワークフローにシームレスに統合され、データサイエンスチームの自律性を損なうことはありません。エンタープライズ向け生成AIアプリケーションの共通基盤である組み込み型「LLMメッシュ」により、有害性検知や個人情報保護といった機能を通じて、適切な生成AIガバナンスの枠組みを実現します。
まとめ
企業や組織がデータアナリティクスへの投資を強化し、AIの成熟度をさらに高めていく中で、アナリティクスおよびAIプロジェクトに対するガバナンスの重要性はますます高まっています。精巧に調整された時計のように、優れたデータオペレーションは多くの可動要素で構成されており、その一部は目に見えやすく、また一部は見えにくいものです。だからこそ、すべての関係者がリスクを最小限に抑えつつ価値を最大化するプロジェクトをスケールさせるために、自らのプロセスを包括的かつ確実にコントロールできるデータプラットフォームをチームが見つけることが不可欠です。