Inside the Box:説明可能なAI基盤の構築
説明可能なAI戦略の導入
住宅ローンが却下されたのに、誰もその理由を正確に説明してくれないという状況を想像してみてください。実際に、現在ではローンの承認から医療診断まで、人生を左右する何千もの決定をAIシステムが行っているのです。しかし、このようなシステムが複雑化するにつれ、「私たちが理解できない決定内容を信頼できるのか?」という大きな疑問が浮上します。
この疑問こそが、説明可能なAIにおける課題の核心となるものなのです。組織がより高度化するAIモデルを展開するにつれ、強力ではあるものの不透明なブラックボックスシステムを選ぶか、より透明性の高いホワイトボックスを選ぶかという重大な選択を迫られるようになります。成功するためには、単にAIを導入するだけでなく”責任を持って”導入することが必要になります。
このガイドでは、AIを解釈可能にするための重要なツールや戦略について解説し、競争力のあるパフォーマンスを維持しつつ、コンプライアンスに準拠した信頼できるシステムを構築する方法についてご紹介します。リスクを軽減して規制に対するコンプライアンスを確保し、強力さと透明性を両立させた堅牢なデータサイエンスを確立するための実践的なアプローチについて学ぶことができます。
透明性に優れアクセスが容易なAIシステムを構築することは、モデル開発に携わるデータサイエンティストなどの関係者だけでなく、モデル開発に直接関与していないエンドユーザー(例えば、出力結果を理解し、それを会社内の他のステークホルダーに伝える必要がある事業部門など)にとってもまた重要となります。
しかし心配は無用です — ビジネスにとって信頼性が高く確実なモデルを構築する方法は存在します。その答えが、説明可能なAI(Explainable AI)なのです。過去10年間に複雑なモデルが台頭したことで、組織はAIに私たちが理解していない(実世界に影響を及ぼす)後遺症とも言える結果が生まれていることを認識するようになりました。これがきっかけとなり、この分野で多くのブレークスルーが生まれ、このトピックに特化した会議が開催され、この分野のリーダーたちが議論を重ね、説明可能なAIモデルを大規模に理解し実装するためのツールの必要性が高まってきました。
説明可能なAIとは、AIモデル、その想定される影響、そして潜在的なバイアスを説明するための一連の手法や機能のことを指します。その目的は、ブラックボックスモデルがどのようにして意思決定に至ったのかを明らかにし、モデルを可能な限り解釈可能にすることです。
説明可能性には、主に次の2つの要素があります:
- 解釈可能性:なぜモデルはそのように振る舞ったのか?
- 透明度:どんな仕組みでモデルは機能するのか?
理想的には、業界やユースケースを問わず、すべてのモデルが説明可能かつ透明であるべきです。その結果、最終的にチームがこれらのモデルを活用したシステムを信頼でき、リスクを軽減し、関係者だけでなく誰もが意思決定の仕組みを理解できるようになるのです。説明可能で透明なモデルが有用となる適用例には、次のようなものがあります:
- 個人や集団に関する重要な意思決定(例:医療、刑事司法、金融サービス)
- ほとんど決定されない、または非定型の意思決定(例:M&A業務)
- 結果よりも根本的な原因が重視される状況(例:予知保全や機器故障、保険金請求や申請の却下)
ブラックボックスモデル vs ホワイトボックスモデル
私たちはブラックボックスモデルとホワイトボックスモデルが共存する世界に生きています。ホワイトボックスモデル(例えば、線形回帰モデルや決定木)は、その挙動や特徴、入力変数と出力予測の関係が観測可能で理解しやすいものとなっていますが、ブラックボックスモデルほど高性能ではない傾向があります(つまり、精度は低いが説明可能性は高いというものです)。基本的に、モデルをトレーニングするために使用したデータとモデルの出力との関係は説明することが可能です。
逆に、ブラックボックスモデルは、入力と出力の関係が観測不能であり、内部の仕組みも不透明なものとなっています(例:顧客属性を入力として車の保険料率を出力するが、その決定プロセスが判別できないモデル)。これは、非常に複雑な非線形性と入力間の相互作用をモデル化するディープラーニングモデルやブースティング/ランダムフォレストモデルに見られる典型的な特徴です。
この場合、データとモデルの出力結果との関係は、ホワイトボックスモデルよりも説明が難しくなります。モデルがどのようにしてその決定を下したのかを明確に示す手順がなく、そのため結果や予測に至る過程を判断することが困難なのです。
状況によっては、モデルの性能と説明可能性の間でのレードオフを容認しても良いと判断できる場合もあります。例えば、アルゴリズムが推奨する映画が自分のお気に入りなら、誰もその理由は気にしないかもしれません。しかし、クレジットカードの申し込みを拒否された理由は、誰もがその理由を知りたいと思うでしょう。
ホワイトボックスモデルとブラックボックスモデルのトレードオフを理解するために、不透明な”システム”の実例として医師について考えてみましょう。多くの人が、医師を症状や検査結果を入力として受け取り、診断結果を出力するブラックボックスシステムのように捉えています。医師は、医療検査や判断における詳細な仕組みについては説明せずに、検査で明らかになった主要な指標を解説しながら患者に診断結果を伝えます。私たちは、実際にはその検査がどのようなものかをよく理解していない状況のまま、生死に関わる場面では医師や検査結果を信頼します。これは、不透明なシステムすべてが悪いわけではなく、私たちが信頼できないシステムのみが問題であることを示しています。
説明可能なAIの中核を成す考えは、次に示すような関係者すべての信頼を得ることなのです:
- モデルを構築するデータサイエンティストたちは、出力結果がモデルの動作の期待値に適合していることを確認したいと考えています。
- モデルを意思決定に使用する関係者は、システムが(背後にある数学的な詳細を理解する必要なく)正しい出力内容を保証することを望んでいます。
- モデルの予測によって直接的または間接的に影響を受ける一般の人々は、不公平な扱いを受けないようにしたいと考えています。
もっとも重要となるのは、システムの説明可能性に対する期待は、このように個人によってまったく異なるという点です。それぞれの期待は、彼らの立場や、社会的そして業界的な基準に対する理解によって変わってきます。したがって、機械学習(ML)システムが責任ある、公正で正当なものであるかどうかの判断は、システムが提供するあらゆる情報をもとに、関係するすべての当事者の議論によって下されるべきであり、また常にそうでなければなりません。
生成AI時代において説明可能なAIがより重要となる理由
生成AIがさまざまな分野で進化および普及し続ける中、これらの強力な技術について責任を持って倫理的に活用するために、説明可能性の必要性がさらに高まっています。
- 出力内容の理解:生成AIモデルは(とくに自然言語処理や画像生成などの領域では)、複雑で微妙なニュアンスを含む出力内容を生成します。とくに医療や金融などで使用される重要なアプリケーションにおいて、モデルが特定の出力を生成する理由を理解することは、信頼性と信頼構築のために不可欠となります。
- バイアスと公平性に関する問題の検出:生成AIモデルは、トレーニングデータに含まれたバイアスを意図せず学習し、拡散してしまう可能性があります。AIモデルの説明可能性ツールやそのメカニズムは、これらのバイアスを特定し、生成された出力内容の公平性と公正性の確保に役立つものとなります。
- デバッグと改善:AIモデルの説明可能性ツールは、モデルがどのように意思決定や出力の生成を行っているかに関するインサイトを提供することで、生成AIモデルのデバッグや改善を支援します。このようなフィードバックループは、時間の経過とともにモデルの性能を改善および向上させるために非常に重要となります。
- 規制の遵守:AIにおける倫理や透明性に関する規制が強化される中、さまざまな場面で説明可能性が法的要件になりつつあります。生成AIシステムは、説明責任を果たし潜在的なリスクを軽減するために、これらの規制要件を遵守しなければなりません。
- ユーザーの信頼と採用:モデルによる意思決定の根拠が理解できる場合、ユーザーは生成AIシステムを信頼し、その採用の可能性が高まります。説明可能なAIは、透明性を提供することで、人間であるユーザーとAIシステム間での信頼関係の構築に役立ちます。
- 倫理面での考慮事項:生成AIモデルの内部の仕組みを理解することは、AIが生成したコンテンツの悪用の可能性やプライバシーやセキュリティーへの影響など、倫理的な懸念に対処するために不可欠となります。
これらの説明可能性における課題は、AI実装におけるより広範な検討事項の一部であり、モデルの性能と解釈可能性のバランス(英語)を確保することです。ブラックボックスモデルとホワイトボックスモデルの間にあるこの根本的な緊張関係は、あらゆる組織が慎重に評価しなければならない独自のトレードオフをもたらします。
ここまで、説明可能なAI(英語)とは何か、それがなぜ重要なのか、そして説明可能性をフレームワークに組み込む際に考慮すべき課題や微妙なポイントについて説明してきました。ここからは、Dataikuがどのようにその実現を支援できるかについてまとめてみます。
Dataikuにより説明可能となるAI
現時点で明らかなように、高いパフォーマンスを発揮するAI組織には、透明性と説明可能性に基づくベストプラクティスが欠かせません。言い換えれば、信頼できる存在であることが不可欠なのです。この高い信頼性を満たすために、機械学習システムには高度な解釈能力が要求されます。
今日の堅牢な機械学習パイプラインには、単に予測を行うだけでなく、人間がモデルを十分に理解し、そこからシステムに対する信頼を築けるだけの情報を提供することが求められます。それではここからは、機械学習パイプラインの各フェーズ、それぞれで考えるべき質問、そしてDataikuがそれらの質問にどのように答えられるかを見ていきましょう。
使用するモデルがどのように意思決定を行うのかを理解することが、組織にとって非常に重要である理由は、次のとおりです:
- 分析をさらに洗練させ改善するための機会が得られる。
- モデルがデータをどのように活用して意思決定しているかを、専門家意外にも説明しやすくなる。
- 実務担当者がモデルによる望ましくない結果や予期しない影響を回避する際に説明可能性が有効となる。
Dataikuは、解釈可能性とモデル性能の最適なバランスを実現することで、これら3つの目標すべてを組織が達成できるよう支援します。ユニバーサルAIプラットフォームであるDataikuは、モデルのライフサイクル全体を通じて透明性と信頼性を確保します。では、Dataikuはどのようにして開発者やプロジェクトの関係者が責任あるAIに向けた組織の価値観に沿って活動できるよう支援しているのでしょうか?
データの説明可能性および透明性
責任あるAIの実践には、データセットに潜在的な欠陥やバイアスがないかを検査するという対応が含まれます。Dataikuには、データ品質管理や探索的データ分析のための組込み型ツールが搭載されており、データの重要な側面を迅速にプロファイリングして容易に理解することができます。さまざまな統計テストや視覚化機能を提示するスマートアシスタントにより、各列の間の関係を特定して分析し、より迅速にインサイトを発見できるようになります。特殊な汎用データ保護規制オプションにより、個人を特定できる情報(PII)がどこで使用されているかを文書化して追跡できるため、当初から機密データの管理をより適切に行うことが可能となります。
Dataikuは、生データのバイアスを検証するためのインタラクティブな統計機能(英語)を提供しており、さらに次のような対応も可能です:
- データリネージュ(英語)(データの由来)、つまりデータがどこから来たのかを把握することが可能
- 透過的なデータ変換とクリーニングによりデータ品質を確保
- 探索的データ分析とサマリー統計を自動化し、データに関する異常値と主要なインサイトを特定
- Flow(英語)と呼ばれるビジュアルパイプラインを活用することで、すべての処理や操作を説明可能かつ追跡可能に
- Gitベースのバージョン管理や、最近のプロジェクトアクションのタイムライン(変更内容を元に戻す機能を含む)利用が可能
モデルの説明可能性
DataikuのVisual MLフレームワークは、モデリング要素を含むプロジェクト向けに機械学習モデルを微調整し評価するための多様なツールを提供し、パフォーマンス、公平性、信頼性に関する期待が満たされているかどうかを確認できるようにします。
モデルの構築とトレーニング
常識的なチェックとしてモデル実験にドメインの知識を組み込むために、各分野の専門家はモデルアサーション(特定のケースにおいてモデルがどのように振る舞うかを予測した、基本情報に基づく記述)を追加することができます。これらの機械学習アサーション(英語)によって、モデルの予測がドメイン専門家の知見と整合しているかどうかを体系的に検証することができます。充実した診断パネルが用意されており、過学習や漏えいなどの問題が検出された場合に自動的に警告を発し、他の整合性チェックの実行を促します。
部分依存プロット(英語)では、特徴量とターゲットとの関係を視覚的に示すことで、モデル作成者による複雑なモデルの理解を支援し、またビジネスチームも特定の入力が予測にどのように影響するかをより確実に把握できるようになります。
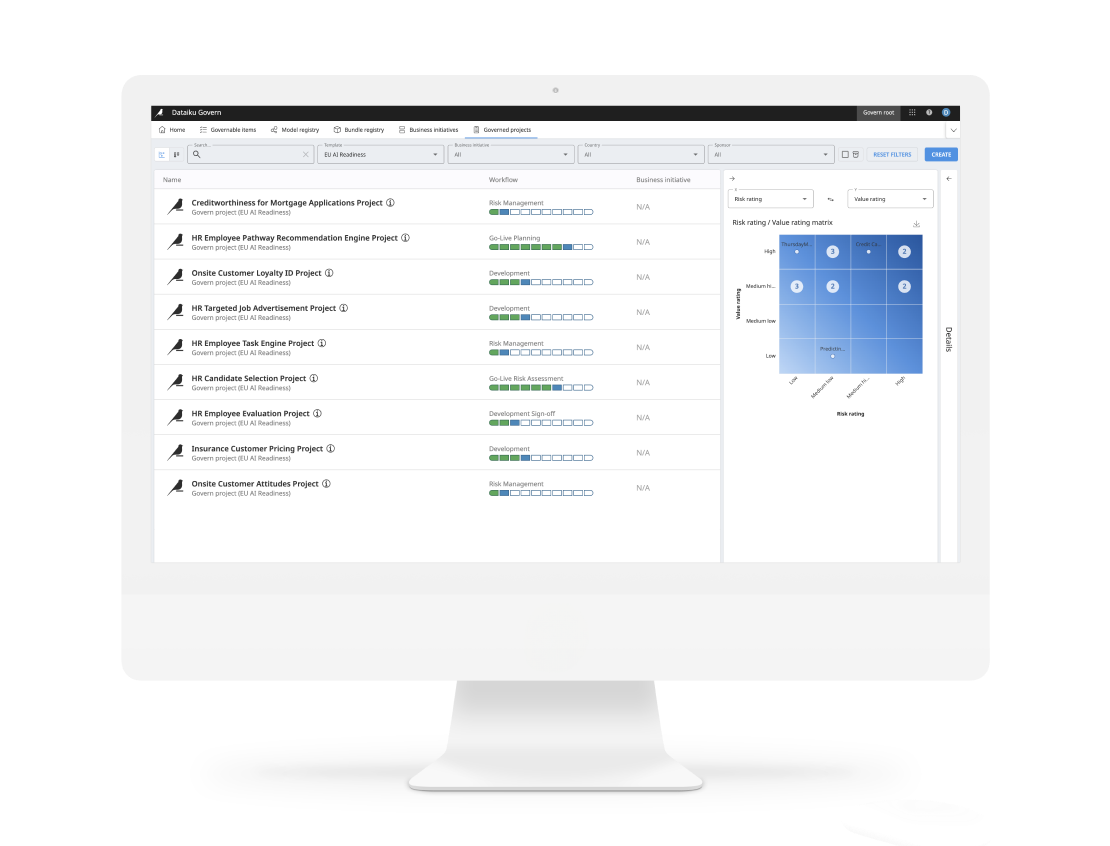
ユーザーはインタラクティブなサブ母集団分析機能(英語)により、グループ別の結果を確認でき、モデルが人口統計学的に異なるサブグループ(データの区分)において均等に良好なパフォーマンスを発揮しているかどうかを検証することができます。関連するビューとしてモデル誤差分析(英語)があり、モデルの性能が十分でない可能性のある特定のグループ(コホート)に関するインサイトを提供します。これら2つの分析はいずれも、モデルによって不公平または異なる扱いを受けている可能性があるグループを特定する際に役立ちます。これにより、担当チームはより責任ある公平な成果を提供できるだけでなく、モデルをデプロイする前にその堅牢性と信頼性を高めることができます。
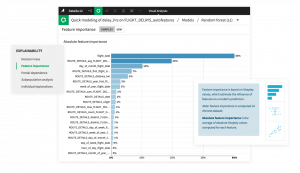
人種、性別、年齢、その他の属性など保護対象のカテゴリーを含むソリューションを展開する前に、モデルに組み込まれた体系的なバイアスが、予測においてこれらの特定のサブグループを異なる扱いをしていないかを評価することが重要になります。Dataikuのモデル公平性レポート(英語)は、このようなタスクの達成を支援するために設計されました。
個々のユースケースに応じてさまざまな観点から公平性を評価するために、異なる視点を適用する必要があります。これらのモデルビューは、業界で認められた複数の公平性指標を計算し、それぞれの定義を明確に説明することを目的としています。ユーザーはこれらの中から、目の前に展開された状況の公平性をもっともよく評価する指標を選択することができます。
モデルの導入と監視
説明可能性はモデルのモニタリングにおいてとくに有効であり、これによりモデルが依然として健全であるか、現状を正確に反映しているか、そして設計どおりの役割を果たしているかを容易に診断することができます。これらの質問のいずれかに対して「いいえ」と答えるような状況だった場合、説明可能なワークフローはその問題解決と回答を見つけるために極めて重要となります。
本番環境における機械学習モデルの監視は、データライフサイクルに関わる全ての関係者にとって重要なものとなりますが、一方では往々にして煩雑な作業となります。従来のモデル再トレーニング戦略は、通常、モデル指標のモニタリングに基づいていますが、多くのユースケースにおいて、AUC(曲線下面積)のような単一の指標だけでは十分対応できないことがあります。
これに該当するのは、モデルの予測精度のフィードバックを受けるまでに長期間が経過するようなケースです。Dataikuのモデルドリフトモニタリング機能(英語)は、フィードバックループを短縮し、スコアリング待ちの新しいデータがトレーニングデータからどれだけ逸脱しているかをユーザーが確認できるようにします。
さらにDataikuのデータ品質ルールは、トレーニングデータからのモデルのデータドリフトを検出するだけでなく(機械学習コンポーネントの有無に関わらず)、パイプライン内のデータがあらかじめ設定された許容範囲を超えて変化していないかをチェックするという用途でも利用することができます。
DataikuのWhat-if分析機能(英語)によりデータサイエンティストやアナリストは、さまざまな入力シナリオを検証することができ、インタラクティブなスコアリングとともにビジネスユーザー向けに分析結果を公開することが可能です。ビジネスユーザーも利用できるWhat-if分析によって、一般的なシナリオによる生成結果を確認したり、新しいシナリオを試したりすることで、予測モデルへの信頼を構築することができます。
DataikuのAI Explain機能(英語)により、組織はパイプラインやコードの内容を即座にわかりやすく説明することで、重要なプロジェクトでの知識の維持とさまざまな関係者の理解を深めることが可能となります。カスタマイズ可能なテンプレートを備えたモデルドキュメント生成機能は、Dataiku Flowsまたは個々のFlow Zoneについての説明を自動的に生成します。この強力な自動ドキュメント生成機能によって、担当チームは膨大な時間を費やしてプロジェクトドキュメントを管理する必要がなくなり、組織は規制遵守や責任あるAIガイドラインへの整合性を確保しながら、一貫したプロジェクト記録を維持することができます。
この結果、ドキュメントを最新の状態に保つために、小さな変更が発生するたびに手作業でドキュメントを更新する必要がなくなります。また同機能により、データサイエンスチーム以外の関係者も、データの準備方法、特徴量、デプロイの詳細など全体像を明確に把握することができ、同時に確実な監査証跡を作成することが可能となります。
ローカルな説明可能性
モデルの出力を業務判断に活用するAIの利用者にとって、特定のケースでモデルがなぜその予測を行ったのかを知ることは、多くの場合有益となります。行レベルの個別説明(英語)は、特定の予測に対してもっとも影響を与えた特徴量や、極端な確率を示すレコードについて理解するうえで非常に有効となります。スコアリング時には、予測の説明をレスポンスの一部として返すことができるため、規制対象業界で求められる理由コードの要件を満たし、さらに分析のための追加情報も提供することができます。行レベルの解釈可能性は、データチームがモデルの特定の予測の背後にある意思決定ロジックを理解する際に役立ちます。
プロジェクトの説明責任
プロジェクト全体の透明性と可視性を確保するために視点を広げると、DataikuのFlowがプロジェクト全体のロジックを明確に視覚化していることがわかります。モデルおよびFlowに関するWikiや自動生成ドキュメントは、開発者、レビュー担当者、AIの利用者すべてが、パイプラインの各段階で下された意思決定を説明および理解するための有効な手段になります。
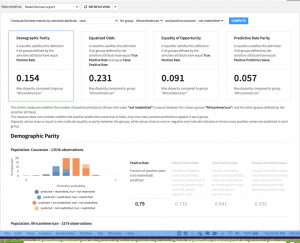
監査の一元化とディスパッチ
監査証跡(英語)や詳細なアクティビティおよびジョブログの保持は、効果的なMLOpsや技術的なトラブルシューティングにおいて非常に重要となります。またリスクやコンプライアンスの観点からも、求められることが少なくありません。Dataikuは、すべてのユーザーの活動に関する監査ログを一元管理するとともに、デプロイされたAPIサービスのクエリログも取得してフィードバックループを完結させます。
Dataikuの自動化されたモデルドキュメント生成、行レベルの予測説明、そして集中管理された監査ログにより、組織は追跡可能で透過的なエンタープライズAIを実現することができます。透明性および説明可能性の実現に向けた堅牢なシステムがなければ、組織は予測結果を大規模に出力できても、その深い影響を理解しないままAIアプリケーションを構築するというリスクを冒してしまう可能性があります。Dataikuにより、組織は単独ツールに追加投資する必要なく、迅速に持続可能で責任あるAIの運用を実現することができます。
コラボレーション:
Dataikuは、あたかもチームスポーツのようにデータおよびAIプロジェクトを推進できるようにする、包括的でコラボレイティブなプラットフォームです。適切な人材、プロセス、データ、テクノロジーを透過的に統合することで、モデルのライフサイクル全体を通じてより適切に戦略的な意思決定を行い、モデル出力に対する理解と信頼を高めることができます。Dataikuが提供する具体的な機能は次のとおりです:
- チーム全員が共通のオブジェクトとビジュアル言語を用いて、データプロジェクトのステップごとのアプローチを説明し、将来のユーザーのためにプロセス全体をドキュメント化することができるビジュアルフロー
- コーディング担当者とそれ以外が同じプロジェクトで作業できるオールインワンプラットフォーム
- プロジェクトのフレームワーク内でチームが共同作業を行い、時間を節約しつつ、会話や意思決定の履歴をプロジェクトの一部として保存できるディスカッションスレッド
- プロジェクトに関する知識を現在および将来のユーザーのために保存するためのWiki
Dataikuでは、どのモデルを選択した場合でも、透明性と説明可能なベストプラクティスによって構築を行うことが可能です。DataikuのAIガバナンスおよびMLOps機能により、チームは責任ある説明可能なAIを構築することができます。
より詳細な内容へ
Explore the Dataiku Model Data Compliance Plug-In
Watch the Model Document Generator Dataiku Demo
Watch the Governance Dataiku Demo
Watch the Explainable AI Dataiku Demo
まとめ
エンタープライズ規模のデータサイエンスプロジェクトにおいて、データサイエンティストやその他のモデル開発者は、モデルの挙動だけでなく、予測の背後にある主要な変数や要因についても説明できる必要があります。
Dataikuを利用することで、組織は透明性が高く解釈可能なモデルを容易に構築し、AIシステムの説明責任を果たしつつ、規制やリスクのコンプライアンス基準を確実に満たし、偏った機械学習モデルによる弊害や悪影響を軽減することができます。
自らの業務に機械学習やAI(生成AIを含む)テクノロジーを統合する業界が相次ぐ中、モデルのパフォーマンスと透明性のバランスの確保が極めて重要になっています。Dataikuのような企業が提供するツールや戦略を活用することで、説明可能なAIの重要性を十分に考慮した責任あるデータ運用を実現することができます。