
機械学習(ML)とは?
ディープラーニング vs. 機械学習
ここ数年で、機械学習(ML)は熟練したデータサイエンティストやエンジニアだけが扱う対象から、ビジネスや分析の専門家にとってもごく一般的な存在へと変化しました。自動機械学習(AutoML)や(Dataikuのような)コラボレーティブAIおよび機械学習プラットフォームの進化により、さまざまな職種の人々の間で予測モデリングを含むデータの活用が拡大を見せています。定義上では、機械学習とは、特定のタスクの実行方法を指示するためのルールを、明示的にプログラミングすることなく、経験によって学習するよう機械に教えることを意味します。
ディープラーニングは機械学習のサブセットです。端的に言えば、ディープラーニングとは、多階層のニューラルネットワークを利用する強力な技術であり、画像、テキスト、音声、時系列データなどの非構造化データを扱うユースケースにおいて非常に高い性能を発揮します。
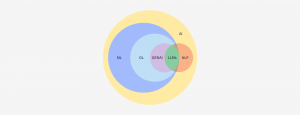
機械学習モデル、機械学習アルゴリズム…その違いとは?
機械学習に関する文章を読む際に、“機械学習モデル”と“機械学習アルゴリズム”という表現がほぼ同じ意味で使われているのを目にしたことがあるかもしれません。そして、時にはこれが混乱を招く原因になります。
簡単に言えば、アルゴリズムとモデルの関係は次のようになります:
- アルゴリズムとは、コンピュータが予測を行ったりパターンを見つけたりするためにデータを処理する具体的な手法のことです。
- モデルとは、アルゴリズムがデータを使ってトレーニングされた後に生成される出力結果のことです。モデルは、学習によって得られたパターンを具現化したものであり、未知のデータに対して再現可能な形で予測や分析を行うために使用されます。
機械学習モデルの場合は、入力としてデータを受け取り、使用アルゴリズムのルールを適用して出力モデルを生成します。
例えば、代表的なアルゴリズムとしては、線形回帰、決定木、k-平均クラスタリング、およびニューラルネットワークなどがあります。これらの各アルゴリズムには、予測を行ったりパターンを見つけたりするためにデータを処理する特有の方法があります。
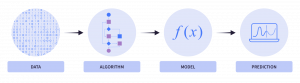
機械学習アルゴリズムとは?
私たちは、アルゴリズムに関して多くのことを耳にし、話題として取り上げますが、その定義が漠然としていることも少なくありません。アルゴリズムは、実際に問題を解決するために使用される一連のルールにすぎません。もしこれまでに簡単なBuzzFeedのクイズで、「サウンドオブミュージックの登場人物であなたの性格に一番合っているのは誰ですか?」といった質問を受けた経験がある方なら、それが実際には一連の質問を投げかけ、いくつかの設定されたロジックを使って答えを生成しているだけだと気付いているかもしれません。それでは、教師あり機械学習アルゴリズムの主要なカテゴリーについて見ていきましょう。
最も一般的な教師あり機械学習アルゴリズムの多くは、次の3つの主要なカテゴリーに分類されます:
- 線形モデルでは、単純な数式を使用して一連のデータポイントを通過する最適な線を見出します。
- ツリーベースモデルでは、一連の“if-then”ルールを使用して、BuzzFeedクイズの例と同様に、ひとつ以上の決定木から予測を生成します。
- 人工ニューラルネットワークは、人間の脳内でニューロンが情報を解釈し問題を解決する仕組みをモデル化したものです。このモデルの一連のアーキテクチャーがディープラーニングの基礎となります。
結局、機械学習は過去のデータを使って予測を行うか、データセット内の一般的なグループ分けを理解するだけなのです。線形モデルは最もシンプルな種類のアルゴリズムであり、最適な適合線を生成することで機能します。線形モデルは、最新のアルゴリズムと比べて常に高い精度を持つわけではありませんが、学習が速く、結果の解釈も比較的容易であるため、現在でも広く利用されています。
教師あり機械学習 vs. 教師なし機械学習
機械学習は、次の2つの主要なサブカテゴリーに大別することができます:
- 教師あり機械学習では、アルゴリズムにラベル付きデータを与えてトレーニングを行い、入力データと期待する出力結果との間にある根本的なパターンや関係性を学習させます。
- 教師なし機械学習では、ラベル付けされていないデータセットからパターンを推論します。ここでは、既知の結果を予測しようとしているわけではなく、データの中にあるパターンやグループ分けを理解しようとしているのです。
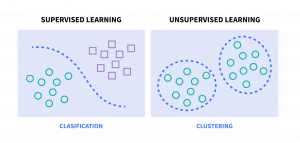
教師あり機械学習とは?
教師あり学習は、学習プロセスを指導してくれる個人教師が付き添ってくれるような機械学習の形態です。教師あり学習では、アルゴリズムにラベル付きの訓練データが与えられ、このデータが教師の役割を果たし、アルゴリズムに「正しい出力とは何か」という具体的な例を提示します。
通常、教師あり学習は、新しい未知のデータに対して正確な予測を行うことを目的とするケースで使用されます。
教師あり機械学習の種類
教師あり学習はさらに、回帰(数値を予測する)と分類(カテゴリー値を予測する)に分けられます。一部のアルゴリズムは回帰にしか使えず、また分類にしか使えないアルゴリズムもありますが、多くのアルゴリズムは両方に対応しています。
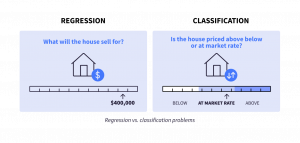
分類:分類は、教師あり機械学習の一種で、新しいデータがあらかじめ定められたカテゴリーやクラスのどれに属するかを予測することを目的としています。
回帰:回帰では、モデルがひとつまたは複数の入力変数に基づいて連続した出力変数を提供します。このモデルは、価格や温度などの数値を予測するために学習を行います。
教師あり機械学習のユースケース
予測分析は、教師あり機械学習の最も一般的な利用例のひとつです。これは、過去のデータを使って株価、売上動向、顧客の行動などの将来の出来事を予測するといった対応になります。
時系列予測(英語)では、過去の値に基づいて時系列データの将来の値を予測します。例えば、株価の将来の値や売上予測、天気のパターンを推定する際に活用されます。
教師なし機械学習とは?
教師なし学習は宝探しのようなもので、地図に該当するデータは渡されるものの、宝とも言える意味あるパターンがどこにあるかは自分で見つけ出す必要があります。通常、教師なし学習はデータの中にあるパターンや関係性を見つけ出すことを目的として使用されます。この手法は、データへのラベル付けに時間がかかる場合や非現実的なほど大規模なデータセットを扱う場合、さらにデータの発見や理解を主な目的にするような場合に使用されます。
教師なし機械学習の種類
教師なし学習にはいくつかの手法がありますが、その中でも圧倒的に多く使われる技術がクラスタリングです。クラスタリングとは、類似した特徴を持つデータポイントを自動的にグループ化し、それらを“クラスター(群)”に分類するプロセスを指します。
教師なし機械学習のユースケース
教師なし学習(具体的にはクラスタリング)のユースケースには、次のようなものがあります:
- 顧客のセグメンテーション、またはマーケティングやその他の事業戦略を構築する際の特徴を明確にした異なる顧客グループの特定。
- 非構造化テキスト文書またはコレクションに含まれるテーマやトピックを検出するためのトピックモデリング。
- 遺伝学では、例えばDNAパターンをクラスタリングして進化生物学を解析する際に用いられます。
- レコメンダーシステムでは、類似した視聴パターンを持つユーザーをグループ化し、似たコンテンツを推薦するために使用されます。
- 異常検知では、不正検出や欠陥ある機械部品の検出(予知保全)などに利用されます。
より詳細な内容へ
Machine Learning in Plain English Blog: AI Algorithms Are Your Friend
機械学習はどのように機能するのか?
機械学習の実質的な目的は、特定の意思決定プロセスを正確かつ確実に表現する数学的モデルを作成することです。
モデルを生成することで、該当タスクを一から構築し直す必要なく、新しい未知のデータに対して何度でも繰り返し実行できるようになります。これにより、時間のかかるプロセスや複雑なプロセスを自動化し、スケーリングすることが可能となります。
要するに、機械学習モデルはデータセット内の特定のパターンを認識するようっトレーニングされ、その後、新たなデータに対して同様のパターンを識別したり、分析のために予測を行ったりするために使用されます。機械学習モデルは、将来発生する分析タスクを機械学習で行うためのブループリント(設計図)として機能します。
機械学習モデルの種類
予測
予測モデリングとは、将来のデータや未知のデータについて予測を行うことを指します。ターゲット変数の性質によって、実行する予測タスクの種類が決まります。
例えば、特定の期間内に患者が再入院するかどうかを予測するという目的で予測モデルを構築したいと仮定しましょう。予測対象として“再入院”を選択し、過去のデータを使ってモデルをトレーニングすることができます。トレーニングの過程で、該当モデルは予測対象の最も強力な予測因子として機能する変数を特定します。トレーニングが終了すると、機械学習モデルはデータ分析のワークフローに組み込まれます。このモデルを使うことで、将来どの患者が再入院する可能性が高いかを予測することができます。
クラスタリング
クラスタリングとは、ターゲットが未知の教師なし学習の問題を指し、データポイント内のパターンや類似性を見つけ出すことを目的としています。クラスタリングモデルでは、“ラベルなし”のデータから隠れた構造を説明するための関数を推測しています。これらの教師なし学習のアルゴリズムは、特徴量に基づいて類似した行をグループ化しています。
先ほどと同じ病院の例を使えば、再入院する患者のタイプに明確なグループ分けがあるかどうかを調べたり、再入院の異常パターンを特定したりすることができます。これらのタイプのユースケースにはクラスタリングモデルを使用できます。
機械学習のライフサイクルとは?
正式なソフトウェア開発ライフサイクルに精通している方にとって、機械学習モデルにもライフサイクルがあることは、決して驚くべきことではないでしょう。典型的な機械学習モデルのライフサイクルは、次の4つのステップに集約することができます:
- データサイエンスのプロセスを通じてモデルが生まれます。このプロセスは、データへのアクセスと準備(特徴量エンジニアリングを含む)から始まり、モデルの設計、トレーニング、探索、そして最適なモデルの選択へと進みます。
- モデルは本番環境にデプロイされます(モデルの世界で言えば、やっと一人前になるようなものです)。
- モデルは複数回の再トレーニングによるアップデートを通じて、長期間にわたり維持されます。
- 最後に、モデルは廃棄されるか、より優れたモデルに置き換えられます。通常、これは新しくてより優れたモデルであり、おそらく以前は利用できなかった新しい技術やデータに基づくモデルとなります。
ステップ1:デザイン、トレーニング、そして探索:
前述のように、通常、機械学習モデルは予測またはクラスタリングに使用されます。予測においては、計算可能な成果を予測することが目的になります。クラスタリングでは、パターン、関係、またはデータに関するインサイトを特定しようと試みます。
機械学習で予測モデルを使用する場合には、他のデータ分析タスクと同様にローデータをクリーンアップし、準備する必要があります。機械学習の手法を選択し、その後モデルをトレーニングすることができます。機械学習モデルは、参照データセットを使って特定のパターンを識別するようにトレーニングされます。このトレーニングにより、将来のデータセットに対しても同様のパターンを識別し、予測を行うことができる機械学習モデルが完成します。
ハイパーパラメータとは、機械学習アルゴリズムの動作や性能を決定する設定や構成を指します。トレーニングプロセス中にデータから学習するパラメータとは異なり、ハイパーパラメータはトレーニング前に設定され、モデルフィッティング(適合)中は固定されたままになります。ハイパーパラメータは、トレーニングプロセスの各局面とモデルの構造をコントロールします。最適なモデル性能をもたらすハイパーパラメータの組み合わせを探し出すプロセスは、ハイパーパラメータ最適化(HPO)と呼ばれます。
HPOにはさまざまなアプローチがありますが、最も網羅的な手法と言えるのが“グリッド検索”です。これは、可能性のあるすべてのハイパーパラメータの組み合わせを総当たりで再帰的に比較し、希望する最適化指標(メトリック)をどのように最大化すべきかを確認する手法です。言い換えれば、すべてを試してみることで、どれが最も効果的だったかを決定するというものです。このアプローチは、最適な設定を見つけるために手を尽くすことを保証しますが、コンピューターリソースと時間を要するという代償が伴います。多くの場合、ランダムサーチ、ベイズ最適化、遺伝的アルゴリズムなどの特殊なハイパーパラメータ最適化(HPO)技術を使用することで、はるかに効率的に機械学習モデルをトレーニングすることができます。
データサイエンティストは、入力特徴量や処理手法、機械学習アルゴリズム、ハイパーパラメータなどを調整しながら、多数のモデルを繰り返しトレーニングして比較することで、パフォーマンスおよび信頼性における目標を満たすことができるモデルを特定します。慎重で体系的なモデルの実験と比較によるモデル開発のステップは、高品質で信頼性の高いモデルを生み出すために不可欠となります。
ステップ2:展開
このステップでは、選択したモデルが本番環境へデプロイされます。本プロセスには、通常、最初にモデルをストレステストし、公平性や潜在的なバイアスを分析し、適切な承認を得るための準備ステップが含まれます。このフェーズでは、該当モデルがQA(品質保証)環境または本番環境に対してデプロイされ、(プロトタイピングや開発向けに使用されるアドホックなデータウェアハウスやストレージではなく)本番稼動用のデータソースに接続されます。機機械学習エンジニアは、モデルのドリフトや本番環境での性能低下を検知するために、長期的にモデルを監視するフィードバックループもセットアップします。
ステップ3:再トレーニング
実際の稼動環境でのデータや状況がトレーニングの際の内容と異なる場合、予測モデルを再トレーニングする必要が生じます。このようなデータドリフトは時間の経過とともに発生し、予測の精度に影響を及ぼすため、最新のデータでモデルを再トレーニングする必要があります。優れたモデルによるワークフローは、モデルを最初から作り直すことなく再トレーニングに対応することができます。これによって担当チームは、データの収集、準備、特徴量エンジニアリングといった時間のかかる事前作業をやり直す必要がなくなり、大幅な対応時間の節約が可能となります。
機械学習デプロイメントにおける変更管理での考慮事項Top 3
残念ながら、データサイエンスプロジェクトのかなりの割合は、実際にはラボの段階から先に進んで機械学習パイプラインのゴールに至ることがありません。データサイエンスプロジェクトが実運用に至らない主な理由として、以下の2点をあげることができます:
1.当初からビジネス目標を設定してスタートしていない
多くの場合、組織は(現状、その技術を業務で使っていない部門などで)AIや機械学習の利用を開始しますが、それがどのような影響や価値をもたらすかについては、正確に把握できていません。例えば、あるチームが解約(チャーン)予測モデルの構築が有益だと聞いていても、目標、モデルにより解決が可能なビジネス上の問題、そして実稼動におけるモデルの使用方法を定義していない場合があります。データサイエンティストや機械学習モデルに直接関わる担当者は、モデルの構築とその実際の活用との間にズレが生じないよう常に注意する必要があります。
2.IT設計および本番稼動対応におけるギャップ
多くの場合、ITチームはプロジェクトを引き継いで新たなプログラミング言語に適応させたり、本番稼動システム向けの機能強化や再コーディングを行ったりする必要があります。このような遅延や書き換えプロセスにより、データサイエンスプロジェクトが頓挫したり、公開までに時代遅れになったりすることも少なくありません。
機械学習の展開における変更管理
1.データサイエンティストは自分のやり方を好み、完全なコントロールを楽しむ傾向がある
データサイエンティストは、自分のノートパソコンで作業する際、必要なパッケージをインストールし、仮想環境の設定方法を把握して、すべてをコントロールしながら簡単に確認することができます。しかし多くの場合、彼らは他の担当者と協力する必要があり、そこでは共同作業が可能なデータサイエンスプラットフォームが活用されます。バージョン管理技術を活用したり、共有クラウドサーバー上で作業することで、チームは同僚と協力してサイロの発生や重複作業を回避することができます。
2.人々はモデルやその基盤となる技術を常に信用するわけではない
実際には、モデル開発は反復的なプロセスであり、ビジネス側が効果の観点から共有や監視を行い、そのフィードバックをデータサイエンスチームに伝えて、特徴量の変更や異なるトレーニングデータの使用などを行うフィードバックループが必要になります。ビジネス側のステークホルダーが、本番稼動におけるモデルの有用性の評価に関与していない場合、将来的に問題が生じる可能性があります。一般的に技術は、人間の仕事を置き換えるためではなく、補完するために使われるべきであり、現状確認および正確さや公平性に関する判断のために、常に人が関与していることが重要となります。
3.IT部門による各種モデルの従来言語(Javaなど)/プラットフォームへの変換
Dataikuのようなツールを使用することで、パイプラインやモデルを本番環境へシームレスにデプロイすることができます。ITチームはパッケージ化されたコーディング環境、バージョニング、さらに効率化されたデプロイのためのデータソースの再マッピングにより、Pythonなどのデータサイエンス言語からJavaなどのIT言語へのワークフローやモデル全体を、何ヶ月もかけて再コーディングやリファクタリングする必要がなくなります。
機械学習の展開におけるツールの問題
例えば、データサイエンティストが機械学習データのラベリングツールを含む、雑多で一貫性のないデータサイエンスツールを組み合わせて使用している場合、機械学習の導入を含むデータワークフローは決してシームレスなものにはなりません。データに関わるすべての作業を1つのツール(Dataikuなど)で行うことで、担当チームはデータのクレンジングやモデリングの過程をより透過的に把握することができるようになり、バージョン管理やロールバック機能、さらにコラボレーションも強化されます。
Building a Predictive Machine Learning Model With AutoML
AutoMLは、機械学習の適用プロセスを自動化するツールであり、これにより迅速なベースラインモデリングを容易に行うことができるようになります。多くの場合、AutoMLは初心者に適した視覚的なポイントアンドクリックのインターフェースの形で提供されますが、経験豊富なデータサイエンティストも、AutoMLを使用して自らの作業を迅速化することができます。
例えばDataikuでは、ツールが自動的に多くの最適化された選択を行う「AutoMLモード」または、コードによってカスタム見積りやディープラーニングのアーキテクチャーを作成できる「エキスパートモード」を選択することができます。AutoMLモードを使用している場合でも、すべてのモデル設定やハイパーパラメータの変更が可能であり、その対象には、試行するアルゴリズムの種類、迅速なプロトタイプ、解釈しやすいモデル、解釈は難しいが高性能なモデルなどが含まれます。
データアクセス、探索、そして準備
データの取得
さまざまなデータソースから、データのミキシング、マージ、収集を行うことで、データプロジェクトを次のレベルに引き上げることができます。使用可能なデータの取得方法としては、次のようなものがあります:
- データベースに接続する: データチームまたはITチームに、利用可能なデータへのアクセスを依頼します。
- APIを使用する:アプリケーションプログラミングインターフェース(API)は、2つのアプリケーション同士が通信するための仕組みであり、Salesforceのようなツールや、Web上のさまざまなアプリケーション、あるいは、皆様の組織が使用している他の多くのアプリケーションからデータを取得するために利用することができます。コーディングの専門家でなくても、Dataikuのプラグインを使用することで、外部データを取り込むための多くの方法を利用できるようになります。
- オープンしているデータを探す:Web上には、既存のデータを補完するための追加情報が豊富に含まれたデータセットが数多く存在します。例えば、国勢調査データはユーザーが住む地区の平均収入の追加に役立ち、OpenStreetMapは特定の通りにあるコーヒーショップの数を提供することができます。多くの国には、アメリカのdata.govのようなオープンデータプラットフォームが存在します。
データの準備
機械学習用データの準備が、データプロジェクト全体の作業時間の最大80%を占めることがあります。言い換えれば、データの一貫性を保ち、クリーンで全体として利用可能な状態に維持することは、決して簡単な作業ではないのです。しかし、機械学習モデルを構築する際には、クリーンなデータを用意することが極めて重要になります。ことわざにもあるように、「ゴミを入れれば、ゴミが出てくる」からです。
データの分析、探索、そしてクリーニング
モデルを構築する前に手元のデータセットについて注意深く理解することは、よい習慣と言えます。この段階で時間をかけてデータを適切に分析、探索、クレンジングすることは、より良い結果を得るだけでなく、深刻な問題(例えば、偏りのあるデータや問題のあるデータを使用して、偏ったモデルやその他問題のあるモデルを構築してしまうことなど)を回避するために役立ちます。
どのようなデータを取り扱っているのかを把握するために調査を開始し、ビジネス担当者、ITチーム、その他の関係者に質問して、すべての変数が何を意味しているのかを理解します。適切なデータ管理(タグ付け、説明、堅牢なテーブルメタデータ)、データのカタログ化、そして整理を行うことで、このような調査の拡大や迅速化が可能となります。例えばこの段階で、「国」を表す項目があっても、スペルが違っていたり、データが欠落していることに気づく場合があるかもしれません。その際には、すべての列を確認し、データが均一でクリーンであることを確認する必要があります。
データの欠損値や不一致などの品質問題に注意を払う必要があります。欠損や無効な値が多すぎる場合、それらの変数はモデルの予測能力を発揮できなくなります。さらに、多くの機械学習アルゴリズムでは、欠損データを含む行を扱うことができません。ユースケースによっては、ゼロなどの定数、その列の中央値や平均値で欠損値を補完(代入)することもあります。さらに場合によっては、欠損値を含む行全体を削除することもあります。
モデルの設計
機能の選択
データセットの探索とクレンジングが終わったら、次のステップではモデルの学習に使う特徴量(フィーチャー)を選択します。特徴量は、独立変数や予測変数とも呼ばれ、予測モデルによって記録および利用される観測可能なデータを指します。構造化データセットでは特徴量は列として表示されます。
特徴量選択を行う主な理由は次のとおりです:
- 複雑さを軽減する。最も関連性の高い特徴量だけを含めることで、モデルの複雑さが軽減され、説明性が向上するだけでなく、トレーニングの速度も速くなります。また複雑さが軽減されることで、関連性の低い特徴量によるノイズの発生を防ぎ、精度を向上することができます。
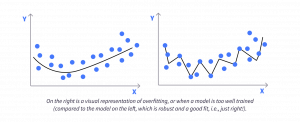
- オーバーフィッティング(過学習)を排除する。オーバーフィッティングとは、モデルがトレーニングデータの詳細やノイズを過剰に学習してしまい、未知のデータには必ずしも存在しないパターンにまで対応してしまう現象です。この場合、モデルはトレーニングデータに対しては良い性能を示しますが、未見のデータに対しては十分機能しなくなります。これは多くの場合、一般化がうまくできていないモデルと呼ばれます。
一部の特徴量はモデルのパフォーマンスに悪影響を与えることがあるため、それらを特定の上除外する必要があります。一般的な特徴量選択の方法には次のようなものがあります:
1.統計的検定は、出力変数と最も強い関係を持つ特徴量を選択するために使用することができます。例えば、単変量解析は、データセットの各変数をひとつずつ調べる際に役立ちます。この種の解析では、データセット内の2つ以上の変数間の関係は考慮されません。むしろ、こちらの目的は、単一の変数を使ってデータセットを記述および要約することです。一方で、二変量解析や多変量解析は、2つ以上の変数を分析してそれらの関係性を明らかにする際に役立ちます。
2.相関行列は、数値変数間の相関係数(関係の強さ)を示す際に役立ちます。相関は、特徴量同士が相互にどのように関連付けられているか、またはターゲット変数がどのように関連付けられているかを示します。相関は正の相関(ある特徴量の値が増えるとターゲット変数の値も増える)や負の相関(特徴量の値が増えるとターゲット変数の値が減る)として表れます。相関行列を使用することで、データセット内の複数の変数のペアごとの相関を視覚的な表として確認できます。多くの場合、これはヒートマップとして可視化され、どの特徴量がターゲット変数と最も関連しているかを簡単に特定することができます。2つ以上の入力特徴量が互いに強く相関している場合(これを共線性や多重共線性と呼びます)、冗長な情報を含む特徴量の除去を検討することが効果的です。これによりモデルを簡素化することができ、解釈性が向上して過学習のリスクも低減できます。
特徴量の取り扱いとエンジニアリング
特徴量の取り扱いとは、特徴量に対して特定の変換を行い、それらをより効果的に活用してモデルの性能を向上させる対応を指します。クリーンなデータが用意できていると仮定すると、特徴量の取り扱いやエンジニアリングは、機械学習モデルを作る際に最大のインパクトを与えることが可能な箇所であり、非常に重要なものとなります!
特徴量の変数型は、次に示すように機械学習における特徴量の取り扱い方法を決定します:
- 数値変数は、加算、減算、乗算などの演算が可能な値が使用されます。変数の値が数値のように見えても、実際にはカテゴリー(またはクラス)を表している場合があります。例えば、”製品タイプ”という特徴量があり、その値が2つある場合:”1”と”2”という値があっても、これを数値的な特徴量として扱うのではなく、カテゴリカル(カテゴリー型)の特徴量として扱うほうがより正確です。
- カテゴリカル変数は、あらかじめ決められた限定された数の値を取り、それぞれが異なるカテゴリー、グループ、またはラベルを表しています。これらは多くの場合、性別、色、国など、自然な数値的順序を持たない属性の特徴を表しています。機械学習アルゴリズムでは、特徴量を数値として扱う必要があるため、カテゴリカル特徴量の処理技術は情報を保持しつつ、これらの変数を数値形式にエンコードします。
- テキスト変数は、任意のテキストの塊(ブロック)です。テキスト変数が”白いTシャツM(white T-shirt M)”や”黒いTシャツS(black T-shirt S)”など、限られた既知の値を取る場合は、カテゴリカル変数として扱った方が便利です。
特徴量エンジニアリングは、既存のデータセットから新しい特徴量を生成したり、既存の特徴量をより意味のある表現に変換するといった対応に関与します。例えば、生の(raw)日時データについて考えてみましょう。生の日時データは機械学習モデルにとって理解しにくいため、有効な戦略としては、これらを解析したり、順序関係を保ったまま数値特徴量に変換するといった対応があります
特徴量エンジニアリングが必要になるもうひとつの例は、値の絶対的な差が大きい場合です。このようなケースでは、再スケーリング(リスケーリング)手法を適用することが考えられます。特徴量のスケーリングとは、数値特徴量の値の範囲を正規化するための手法です。これはなぜ必要なのでしょうか?異なる尺度で測定された変数は、モデルへのフィッティングが均等にならず、バイアスを生じさせる可能性があるためです。
一部のデータサイエンスや機械学習、AIプラットフォーム(Dataikuなど)では正規化が自動的に行われますが、その基本的な仕組みを理解しておくことは重要となります。例えば、最も一般的な再スケーリング手法のひとつとして、最小値-最大値再スケーリング(min-max rescaling、別名min-max scalingまたはmin-max normalization)があり、最もシンプルな方法と言えます。これは、データを固定範囲(通常は0~1)にスケーリングする方法です。このように範囲を制限することで標準偏差が小さくなり、外れ値の影響を抑えることができます。
カテゴリー変数に対する特徴量エンジニアリングでは、少し異なるアプローチが必要になります。例えば、機械学習のアルゴリズムが理解できるように、カテゴリー変数を数値にエンコードする変換手法があります。ダミーエンコーディング(ベクトル化)は、カテゴリカル変数のカテゴリー数と同じ長さの0/1フラグのベクトルを作成する方法です。
データのサブセットに関するトレーニング
機械学習モデルを開発する際には、入力を出力にどれだけ正確にマッピングし、正しい予測ができるかを評価することが重要となります。しかし、モデルがすでに(例えばトレーニング中などに)学習に使ったデータで性能を評価すると、過学習などの問題を検出することができなくなります。
機械学習では一般的に、トレーニングデータをトレーニング用セットとテスト用セットに分割するか、あるいはトレーニング、評価、テストの3つのセットに分割して取り扱います。分割する割合に厳密なルールはありませんが、一般的には訓練用に多めのデータを確保する形が合理的で、典型的なトレーニング/テストの分割比率は80%対20%となります。ほとんどの場合、データはランダムに分割され、両方のセットでデータ内に存在するパターンが適切に反映されるようにします。しかし、詐欺などの稀な事象を予測する場合や、トレーニングデータ内のすべての結果クラスが均等に出現しない場合には、トレーニングサンプルでその事象をより重み付けしたり、階層化サンプリングを用いて、すべての出力クラスが十分にトレーニングデータに含まれるようにします。そしてこの対応こそが、適切な学習を促しバイアスを防ぐためのベストプラクティスとなります。
モデルタスクの定義
DataikuのAutoMLを使用する場合でも、モデルを作成する際には(たとえ迅速なプロトタイプであっても)、次のようないくつかの決定を下す必要があります:
1.ターゲット変数を選択します。教師あり学習モデルを使用するため、ターゲット変数、または他の変数によってモデルが予測する値を持つ変数を指定する必要があります。言い換えれば、予測したい対象となる変数です。
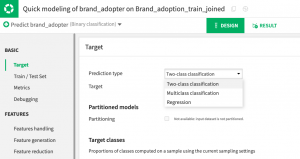
 2.予測種別を確認します。ターゲット変数を特定すると、AutoMLは自動的に予測タイプを検出します(ただし、デフォルトの選択肢は変更が可能です)。念のため記載すると、主な予測の種類は次のとおりです:
2.予測種別を確認します。ターゲット変数を特定すると、AutoMLは自動的に予測タイプを検出します(ただし、デフォルトの選択肢は変更が可能です)。念のため記載すると、主な予測の種類は次のとおりです:
- 回帰、または数値の予測。
- 分類。これは複数の選択肢の中から”クラス”や結果を予測することを指します。
アルゴリズムおよびハイパーパラメータの選択
アルゴリズムにはそれぞれ長所と短所があるため、モデルで使用するアルゴリズムは、主にビジネスの目的や優先事項によって決定されます。
また、ライブラリの概念を理解することも重要になります。ライブラリは、特定のプログラミング言語で書かれた一連のルーチンや関数の集まりで、多くのコードを書き直すことなく複雑な機械学習タスクを簡単に実行できるようにします。例えば、Dataiku AutoMLでは、次の4つの異なる機械学習エンジンをサポートしています:
- インメモリPython(Scikit-learn / XGBoost)
- MLLib(Spark)エンジン
アルゴリズムの選択に加えて、機械学習モデル構築におけるもうひとつの重要な対応はハイパーパラメータの調整です。ハイパーパラメータとは、学習プロセスを制御するために設定されるパラメータで、機械学習モデルの設定項目のようなものになります。ハイパーパラメータはモデルの全体的な挙動を制御するため非常に重要であり、それらをチューニングまたは最適化することで、モデルのパフォーマンスを向上させることができます。ベースラインモデルの場合には、AutoMLが最も有望なハイパーパラメータの最適化を素早く実行できるため、限られた時間内でより優れたモデルを構築することができます。
モデルの評価
モデルの良し悪しは、どうやって判断すればいいのでしょうか?そのためには、さまざまなアルゴリズムにわたって、モデルの性能を追跡および比較するという対応が重要になります。
メトリックの評価と最適化
機械学習モデルの評価指標は、回帰モデルか分類モデルかによって、それぞれいくつか種類があります。また、多くのアルゴリズムではモデルのトレーニング中に、最適化すべき特定の評価指標を明示的に選択する必要がある点にも留意する必要があります。ただし、モデルの実際の性能を判断するという観点では、その指標は他の評価指標ほど解釈しやすいものではありません。
回帰モデルの場合は、平均二乗誤差(Mean Squared Error)や決定係数(R-squared、R²)を確認する形態が一般的です。分類モデルの場合、最も基本的な評価指標はF1スコアです。精度(Accuracy)は一般的な言葉ですが、この場合には、非常に具体的な計算方法があります。精度は、モデルが正しく予測できた観測データの割合を指します。精度は理解しやすい指標ですが、特に予測対象となるクラスが不均衡な場合には慎重に解釈する必要があります。
オーバーフィッティング(過学習)と正規化
これまでのセクションでもオーバーフィッティングについて触れてきましたが、この段階で改めて詳しく説明する必要があります。なぜなら、オーバーフィッティングは予測モデルを構築する際の最大の課題のひとつだからです。すでにご存じのとおり、トレーニングデータを使ってモデルに学習をさせると、そのデータに含まれるパターンを学習することで予測ができるようになります。
しかし同時に、このモデルは対象データ特有の予測に役立たない癖やノイズについても学習してしまいます。そして、その癖やノイズが予測に影響を与え始めると、トレーニングデータへの過剰な適合が発生し、テストデータ(さらには新しいデータ全般)に対するモデルの性能が低下していきます。オーバーフィッティングへの対処法のひとつが正則化(regularization)ですが、これは基本的にモデルを単純化し、過度に特殊化させないようにする手法にすぎません。
特徴量エンジニアリングを通じて、AutoMLはデータ型に基づき、特徴量の選択、削減、欠損値処理、変数のエンコーディング、再スケーリングなどの取り扱い戦略を適用します。アルゴリズムに依存しないアプローチであり、常に最良のサービスとモデルを利用できるため、パフォーマンス、コスト、および複雑さといった要因に基づいてモデルのトレードオフの判断を下すことができます。
機械学習によるスケーリングに向けたプロセスの最適化
機械学習が持つ能力は、業務プロセスの改善や成長に影響を与える複雑な外部要因の理解を目指す組織にとって、大きな価値をもたらします。機械学習モデル、そして機械学習モデルのライフサイクルでは、ビジネス成果を予測するモデル作成における重要な要素を自動化することで、データ分析やリサーチに費やされる労力を大幅に削減することができます。