
生成AIによる企業変革の推進
生成AIとは?
急速に進化する人工知能(AI)の分野において、現在、世界中の企業の間で大きな注目を集めているキーワード、それが生成AI(Generative AI)です。この最先端技術は、企業経営の方法、イノベーション、さらに企業競争における優位性の確立に革命をもたらす非常に大きな可能性を秘めています。
しかし、適切なガバナンスを備えた生成AIの導入拡大は決して容易ではありません。ここでは、エンタープライズ向け生成AIの世界を深掘りし、その重要性、もたらされる変革のインパクト、さらにその力を効果的に活用するために不可欠となるツールについて探っていきたいと思います。
生成AIは、テクノロジーに対する私たちの関わり方を根本から激変させ、人間の創造性と機械の知能との境界線をより曖昧なものにしつつあります。特定のタスクを実行したり、既存のデータに基づいて予測を行うような従来のAIモデルに対し、生成AIは新たなコンテンツを生み出すという驚くべき能力を持っており、その成果はしばしば人間が作成したものと区別がつかないレベルになります。
生成AIが企業にどのような変革をもたらすのかを理解するためには、まずその仕組みや生成AIのユースケースの構築方法を理解することが重要になります。それでは、生成AIに関連する最も重要な技術や概念のいくつかを定義することからはじめましょう。
大規模言語モデル(LLM)
OpenAIのChatGPT、MicrosoftのBing、GoogleのGeminiは、大規模言語モデル(LLM)と呼ばれる一連の技術に基づいて構築された具体的な製品群です。
LLMは、膨大な量のテキストを解析して単語同士の関係性を見出すことで、同様のテキストを再生成できるモデルを構築します。重要なのは、LLMが質問に対する答えを「検索している」のではないという点です。むしろ、LLMはそれまでの単語や文脈を踏まえ、次に来るのにもっともふさわしい単語を予測しながら、単語列を一つずつ生成していくことで回答を作り出しているのです。このため本質的には、質問に対する「常識的」な回答を提供することになります。
もっとも高機能なLLMは、驚くほど広範囲わたるタスクで高い精度の回答を生成する能力を示していますが、これらの回答における実際の正確性は保証されるものではありません。
これは、LLMの回答が過去の記憶であるデータから「検索」されたものではないためです。これらの回答は(ニューラルネットワークのセクションで紹介するように)1,750億もの重み付けに基づいて、リアルタイムで生成されています。つまりLLMが生成する出力は「正しいように見える」だけで、その内容の正確性が保証されるものではないのです。
ニューラルネットワーク
ニューラルネットワークは大量の「ニューロン」で構成され、それぞれが単純で数学的な計算式であり、計算結果をシステム内のひとつ以上の他のニューロンに伝達します。これらのニューロン間の接続には、ニューロン間のシグナルの強さを規定する「重み」が与えられます。これらの重み付けは「パラメータ」とも呼ばれます。
ニューラルネットワークは、非常に小規模な構成にすることも可能です。例えば、基本的なニューラルネットワークの場合、6個のニューロンとそれらを結ぶ8本の接続だけで構成されることもあります。しかし、LLMのように、ニューラルネットワークが非常に大規模な構成になる場合もあります。このような大規模なネットワークには、数百万のニューロンと数千億もの接続が存在し、それぞれの接続に対して固有の重みが割り当てられています。
トランスフォーマーアーキテクチャー
前述のように、LLMはニューラルネットワークの一種です。より具体的に言えば、LLMはトランスフォーマー(Transformer)と呼ばれる特別なニューラルネットワークのアーキテクチャーを使用していますが、これはテキストのような連続したデータの処理や生成に向け設計されたものです。
Googleの研究者たちによって2017年に開発されたトランスフォーマーは、「アテンション(attention)」という考え方に基づいており、これは特定のニューロンがシーケンス内の他のニューロンとより強く結合する(または「より注意を払う」)ことを意味します。
テキストデータは、単語が次々に読み込まれ順次出力されるという性質を持ち、文中の異なる要素が相互に参照し合うため(例えば、名詞を修飾する形容詞が動詞には影響を与えないなど)、このようなシーケンシャルな処理に向け最適化されたアーキテクチャー(シーケンス内の各ニューロン間に異なる重み付けの接続を設定することが可能な構造)が、テキストベースのデータで高い性能を発揮するのは必然的な結果と言えるでしょう。
ハルシネーション(幻覚)
ハルネーション(幻覚)とは、現実のように見えるものの、実際はAIモデルによって完全に生成され、いかなる現実世界のデータにも一致しないコンテンツまたはパターンの生成を意味します。生成AIにおけるハルシネーション(幻覚)は、創造的で想像力に富んだアウトプットを生み出すこともありますが、企業での業務利用においては問題となる可能性があります。
実際にハルシネーションは、重大なリスクや課題を引き起こす可能性があり、その影響は誤情報の拡散や評判の損失、さらにコンプライアンス違反やセキュリティー上の脆弱性にまで及ぶことがあります。生成AIにおけるハルシネーションが潜在的に抱える「AI生成コンテンツがビジネスの運用や成果に与える影響」を最小限に抑えるために、堅牢なガバナンス体制、倫理的なガイドライン、そして厳格な検証プロセスの重要性(英語)が浮き彫りになっています。
ファインチューニング(微調整)
LLMの運用において、ファインチューニング(英語)とは、特定のタスクやドメインにより適した形にするために、事前学習済みモデルのパラメータを調整および最適化するプロセスを指します。LLMのファインチューニングとは、対象のタスクやドメインに関連する、より小規模でタスク特化型のデータセットや専門的なコーパスに基づいて、モデルのパラメータを更新するプロセスを指します。
このプロセスにより、モデルは特定のタスクやドメインの微妙なニュアンスや要件に適応し、理解力やテキスト生成の精度をより高めることが可能になります。LLMをファインチューニングすることで、研究者や実務担当者はその能力をテキスト要約、センチメント分析、言語翻訳など、さまざまな自然言語処理(NLP)タスクに合わせて発揮できるようになるため、ターゲットのアプリケーションにおいて高い性能とより正確な予測結果を得ることが可能となります。こちらのブログで、生成AIを用いた要約や生成AIによる自然言語処理(NLP)といったタスクや、その他の生成AIの技術的手法についてご確認ください(英語)。
検索拡張生成(RAG)
検索拡張生成(RAG)(英語)は、言語モデルがより良い応答内容を生成するための優れた手法です。RAGは、まず質問や文脈に基づいて大規模なデータベースから関連情報を検索します。
次に、検索した情報と自らのナレッジを組み合わせて、より正確に質問に答えます。これにより、RAGは自らのナレッジだけに頼るよりも、さらに理にかなった有用な回答を提示することができます。
企業向け生成AIのユースケースの特定
生成AIを企業のワークフローに統合することで、製品設計、コンテンツ制作、意思決定プロセスなど、さまざまな分野で新たな可能性が開けます。AIの力を活用し、画像、新たなアイデア、デザイン、ソリューションを生み出すことで、企業は業務を効率化し、イノベーションを促進し、これまでにない付加価値を顧客に提供することが可能となります。
実際に、北米の大手企業のAI関連意思決定者220人を対象としたForresterの調査(英語)では、すでに83%が生成AIを検討または試行中であることが明らかになっています。
では、どんなアプリケーションやユースケース(英語)なら、生成AIからメリットを得ることができるのでしょうか?また、検討すべき代表的な生成AIソリューションは何なのでしょうか?ここに留意すべきいくつかの重要なポイントがあります。
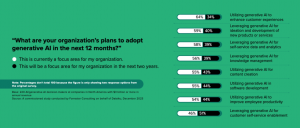
LLMと他のモデルの間でのトレードオフ
LLMの使用(英語)は、より多くの計算リソースを消費する可能性があります。例えば、1750億(英語)の重み付けを持つモデルの場合、出力される”トークン”(単語や単語の一部)ごとに毎回1750億回の計算を実行する必要があります。なぜこのような大規模なモデルを作る必要があるのでしょうか?特に設計された小規模な言語モデルが特定タスクで優れた性能を発揮する場合、大規模モデルは必要なのでしょうか?
最大規模のモデルは、あたかもスマートフォンのようなものです。ひとつの製品内に多くの機能が搭載されているため利便性が高くなります。これは、さまざまなタスクに対して同じモデルが使用できることを意味します。翻訳ができ、要約することもでき、いくつかの入力に基づいてテキストを生成することもできるのです。スマートフォンのように幅広いタスクに対応できるソリューションのひとつですが、その柔軟性の確保にはコストという代償が伴います。
例えば、必要なものがストップウォッチ機能だけなら、スマートフォンよりはるかに安価な製品を探し出すことができます。同様に、特定のタスクに対するソリューションが必要な場合には、小規模で対象タスクに特化したモデルを選択する方が効果的な場合もあります。
LLMや生成AIが有効となる活用場面とは?
組織内でLLMの有効性を試してみたいと考えている場合には(例えばHeraeus社がリード管理プロセスにLLMを活用したように)、以下のバランスが取れたアプリケーションを選ぶことを推奨します:
- リスク許容度: 初めて生成AI技術を導入する場合には、ある程度のリスク許容が可能な業務領域を選択することが賢明です。対象アプリケーションは、組織の中核的な業務に直結するものではなく、むしろチームにとっての利便性向上や業務効率の改善を目的としたものであるべきなのです。
- ヒューマンレビュー:ある法律事務所では、「この技術を使って契約書の草案を作成することに抵抗はない。同様の作業を新人のアソシエイトに任せるのと同じ感覚だからだ」と述べています。なぜなら、このような文書はその後何度もレビューされるため、生成AIアシスタントを活用することで、誤りが見落とされるリスクを最小限に抑えることが可能だからです。例えば、Whataburger社では、LLMを活用して顧客の声を分析し、人間のスタッフは顧客体験を向上させるために分析結果のレビューに焦点を当てています。
- テキスト(またはコード)中心の作業:これらのモデルの強みを活かし、テキスト中心の作業やコード中心の作業、特に文や段落の生成といった「制約の少ない(unbounded)」作業に活用することが重要です。これはセンチメント分析など「制約のある(bounded)」タスクとは対照的なものです。それらのタスクに対しては、多くの場合、既存の目的特化型ツールの方が低コストかつ低い複雑度で優れた結果を提供できます。
- 事業価値: 常に言えることですが、特に新しい技術に対する期待が高まっている時こそ、基本に立ち返ることが重要です。つまり、対象アプリケーションが実際にビジネスにとって価値があるのか、そして生成AIのバリューチェーンが、その中でどのように位置付けられるのかを見極める必要があります。LLMは実に多くのことができますが、それらが本当に価値を持つかどうかはまた別の問題です。
企業におけるLLMの使用方法
企業がPoC(概念実証)から本番環境でのLLM活用へと工程を進める際(英語)、ChatGPTのような単純なWebインターフェースを超えて本格導入のための移行を行うには、主に次の2つの方法があります:
- OpenAIが提供する(GPT-3.5-turboやGPT-4-0314などの)GPT-3モデルのように、サービスとして提供されているモデルに対してAPIコールを行う方法です。一般的にこれらのサービスは、OpenAIなどの専門特化した企業、またはAmazon Web Services(AWS)、Google Cloud Platform(GCP)、Microsoft Azureなどの大規模クラウドコンピューティング企業によって提供されます。
- 管理対象となるシステム環境にオープンソースのモデルをダウンロードして実行する方法です。Hugging Faceのようなプラットフォームでは、このようなモデルを幅広く集約しています。
それぞれのアプローチにはメリットとデメリットがありますが、これについては次のセクションで解説します。そして忘れてはならないのは、どちらの選択肢についても小規模モデルから大規模モデルまで選択可能であり、また、適用可能な領域の広さ、生成される言語の精巧さ、モデルの利用にかかるコストや運用の複雑さといった点でトレードオフが発生するということです。
API経由でModel-as-a-Service(MaaS)を使用することのメリット
一部の企業(OpenAI、AWS、GCPなど)は、プログラムで呼び出すことができるパブリックAPIを提供しています。これは、APIに接続して適切な形式のリクエストを送信するための、小規模なソフトウェアプログラムやスクリプトをセットアップする必要があることを意味します。
このようなAPIでは、モデルに対してリクエストを送信し、モデルからの応答がAPI経由でリクエスト元に返送されます。
このアプローチには、次のようないくつかのメリットがあります:
- 参入障壁の低さ: APIの呼び出しは、ジュニアレベルの開発者でも数分で実現できる非常に単純なタスクです。
- より洗練されたモデル:APIの背後で動作するモデルは、多くの場合、利用可能な最大でもっとも洗練されたバージョンとなります。これは、大規模モデルは小規模で単純なモデルと比べて、より広範なトピックについて、洗練された正確な回答を提供できるからです。
- 素早い応答: 一般的にこれらのモデルは、リアルタイムでの使用を可能にする比較的迅速な応答(秒単位のオーダー)を返すことができます。
API経由でModel-as-a-Service(MaaS)を使用する際の制限
API経由でのパブリックモデルの利用は、便利で強力ではあるものの、特定のエンタープライズ用途には適さない次のような制約も存在します:
- データの所在とプライバシー: パブリックAPIを利用する場合には、その性質上、クエリ(問い合わせ)の内容をAPIサービスのサーバーへ送信する必要があります。このため場合によっては、クエリの内容が保持され、さらなるモデル開発に向け使用されることがあります。企業は、このアーキテクチャーが、自社のデータレジデンシー(データの所在)およびプライバシーに関する要件を満たしているかどうかをユースケースに応じて慎重にチェックする必要があります。
- コストが割高になる可能性: ほとんどのパブリックAPIは有料サービスであり、ユーザーはクエリの回数や送信したテキスト量に応じて課金させます。これらのサービスを提供する企業は、通常、ユーザーが利用コストを見積もるためのツールを提供しています。また、より小規模で安価なモデルも提供していることが多く、これらは限定的なタスクに適している場合があります。
- 依存関係の強さ: APIのプロバイダーはいつでもサービスを停止することができますが、人気があり収益を上げているサービスの場合、そのような決定が下されるケースは通常稀です。こうしたサービスを提供する小規模な企業は、経営破綻のリスクを抱えている場合があります。企業は、このようなサービスに依存することによるリスクを十分に検討し、それを受け入れられるかどうかを慎重に判断する必要があります。
オープンソースモデルを自社で管理することによるメリット
API経由でパブリックモデルを利用する際のデメリットも踏まえ、企業が自らオープンソースモデルを構築して運用するという選択肢を検討することも適切な判断と言えます。このようなモデルは、企業が所有するオンプレミスサーバー上で実行することも、また企業が管理するクラウド環境で実行することもできます。
このアプローチをとることによるメリットには、以下のようなものがあります:
- 幅広い選択肢: 利用可能なオープンソースモデルは数多くあり、それぞれに独自の強みと弱みがあります。企業は、自社のニーズにもっとも合致したモデルを選択することができます。しかし、これを行うためには、対象となる技術に関する一定の知識と、トレードオフを理解する能力が必要となります。
- コストを抑えられる可能性: 場合によっては、適用範囲が限定された小規模なモデルを使用することで、非常に大規模なサービス提供モデルを使うよりも、はるかに低コストで特定のユースケースに求められる性能を実現できる場合があります。
- 独立性: オープンソースモデルを自社で運用および管理することで、組織はサードパーティのAPIサービスに依存する必要がなくなります。
オープンソースモデルを自社管理する際のトレードオフ
オープンソースモデルを使用することには多くのメリットがありますが、以下のような理由から、すべての組織やすべてのユースケースに適切な選択とならない可能性もあります:
- 複雑さ: LLMの立ち上げや維持管理には、従来の機械学習(ML)モデルよりもはるかに高度なデータサイエンスおよびエンジニアリングの専門知識が要求されます。組織は、自社内に十分な専門知識があるかどうか、さらに専門家が長期的にモデルのセットアップや運用に必要な時間を割けるかどうかを慎重に評価すべきです。
- パフォーマンスの低下: パブリックAPI経由で提供される非常に大規模なモデルは、カバーすることが可能なトピックの幅広さにおいて驚異的な能力を発揮します。オープンソースコミュニティーが提供するモデルは一般的に規模が小さく、用途がより限定的ですが、今後オープンソースコミュニティーによってさらに大規模なモデルが開発されるにつれて、この状況が変わる可能性もあります。
生成AIの責任ある活用
責任を持ってLLMを活用するためには、次に示すような、機械学習やAI技術と同様のステップやリスク管理への考慮が不可欠です:
- モデルの構築方法を理解することが必要です。LLMに限らず、すべての機械学習やニューラルネットワークは、トレーニングに用いられたデータの影響を受けます。これにより、修正が必要となるバイアス(偏り)が生じることがあります。
- モデルがエンドユーザーにどのような影響を与えるかを理解することが重要です。特にLLMの場合は、エンドユーザーが実際には人間とやり取りしていないにも関わらず、人間と対話していると誤認するリスクがあります。Dataikuは、組織に対してこれらの技術がどこでどのように使用されているのかを、エンドユーザーに開示することを推奨しています。また組織は、モデルから生成された情報とどのように関わるべきかという指針をエンドユーザーに提示し、情報の全体的な品質や事実の正確性に関する注意事項も明示すべきです。
- 技術別に、どのアプリケーションが適切な使用例となるかを審査するプロセスの確立が重要となります。特定のアプリケーションに対して特定のモデルを使用するかどうかの判断は、各データサイエンティストだけで下すべきではありません。むしろ企業側が、「どの技術をどの用途で使用すべきか、またはすべきでないか」を明確に定義した原則を策定し、実施結果に対して責任を負うリーダーたちによる一貫したレビュープロセスを確立する必要があります。
- どの技術がどのアプリケーションで使用されているかを継続的に追跡します。AIガバナンスの原則は、問題の発生を未然に防ぐとともに、万が一問題が発生した場合に、どの技術が使用されたかを追跡して確認できる、監査可能な履歴を確保することを目的としています。Dataikuのような優れたガバナンス機能を備えた企業向け生成AIツールやAIプラットフォームは、組織全体の統制を担う「中央のコントロールタワー」としての役割を担います。
Go Further
Discover Generative AI Use Cases in Supply Chain
A Practical Guide for Predictive Maintenance With Generative AI
企業向け生成AIツール
企業が生成AIの活用に向けて歩みを進める中、包括的なソリューションとして際立つプラットフォームがあります:それがDataikuです。高度な機能、拡張性、使いやすさで定評があるDataikuは、組織がさまざまなユースケースや業界において、AIの可能性を最大限に引き出せるよう支援します。
また、データの準備、モデリング、デプロイ、および管理を一つの統合された生成AIプラットフォーム(英語)内で組み合わせた、エンタープライズAIへの包括的なアプローチを提供します。直感的なインターフェースと事前構築済みの豊富なアルゴリズムライブラリを備えたDataikuは、スムーズなユーザーエクスペリエンスを実現し、生成AIモデルの迅速なプロトタイピングとデプロイを支援することで、企業全体でのイノベーションと業務効率の向上を促進します。
