確信を持った導入拡大に向け:責任あるAIを理解する
責任あるAIとは?
生成AI分野の急速な進歩により、”責任あるAI”という概念に対して、これまで以上に大きな注目が集まっています。わずか数年でAIは急速に進歩し、以前は1つのモデルを作るのに1年を要していた状況が、現在では平均的な企業でも同じ期間に何千ものモデルを構築できるようになっています。さらに大規模な運用化により、ひとつのモデルが組織や業界全体で何百万件もの意思決定や人々に影響を与えるようになっています。
このようなAIの利用拡大は、同時に次のような新たなリスクをもたらす可能性を秘めています:
- AIシステムは、本番環境では当初の設計や意図に反して予想外かつ不十分な挙動を示すことがある
- モデルがデータに含まれるバイアス(偏り)を再現または拡大する可能性がある
- GPT、Claude、Geminiといった大規模言語モデル(LLM)から得られた回答など、AIによって生成された回答では、安全でない行為の助長や誤情報、不適切なコンテンツ(とくに社会的に過少評価や疎外を受けているグループなどに向けた)の発信によって、周囲にさまざまな害をおよぼす恐れがある
- 自動化が進むことで、ミスや不公平な結果を検知して修正する機会が減ってしまう可能性がある
本番環境で運用されるモデルの数が激増しているにも関わらず、これらのモデルを責任持って展開するために時間と労力を注いでいる企業はほとんどありません。しかし同時に、これは決して驚くに値しないことがわかります。責任あるAIが正確に何を指すのか、また企業がそれをどのように実行すべきかについては、まだ共通の明確な定義が確立されていないからです。コンサルティング会社やGoogle(英語)のような大手テクノロジー企業、そしてPartnership on AI(英語)といった団体がガイドラインの開発を開始していますが、またそれが広く普及して実践される状況には至っていません。
責任あるAIとは、人々や企業に力を与え、顧客や社会に公平な影響を与える方法でAIを設計、構築、展開する実践対応を指します。これにより、企業は自信を持ってAIを信頼し、規模を拡大することができます。つまり、これはAIのアウトプットが組織の価値観と一致することを保証するための概念なのです。責任あるAIはプロアクティブな形で、AIシステムが信頼性、責任性、公平性、透明性、説明可能性を備えていることを保証します。
このような言葉は誤解されやすいため、責任あるAIの原則に関する”よくある俗説”を取り上げ、それが企業や組織にとって何を意味し、また何を意味しないのかを明確にしていきたいと思います。
俗説1:倫理的AI vs 責任あるAI — 責任あるAIへの移行はAI倫理の定義で完結する
責任あるAIに関する最大の誤解のひとつは、それが単にAI倫理の定義を決めることにすぎないと思われている点です。しかし責任あるAIは、それよりもはるかに広範かつ繊細な概念であり、主に次の2つの側面を含んでいます:

AIの倫理を定義することは、責任あるAI基盤を構成する要素ですが、その対応は決して簡単ではありません。
業務の意図と成果物を完全に一致させ、アウトプットが目的に合致していることを保証し、AIの取り組みを支えるためにあらゆる側面でのレジリエンス(回復力)を確保することがゴールなのです。
倫理を定義する際には、バイアスが混在しないようにすることが重要です。倫理とは一連の原則であり、バイアスはそれらの原則を適用すべきひとつの側面にすぎません。例えば、ある機械学習(ML)モデルがまったくバイアスを含んでいなかったとしても、非倫理的である可能性があります(例:健康データに基づく保険料の算出モデル)。逆に、倫理的ではあってもバイアスを含むケースもあります(例:小売の洋服のレコメンデーションエンジンでは性別によるバイアスが問題にならなくても、金融機関では深刻な問題となる可能性があります)。
俗説2:責任あるAIの課題はツールだけで解決できる
良いニュースと悪いニュースがあります。良いニュースは、責任あるAI戦略の実行に向け、組織を支援するツールが存在するということです。説明責任という観点では、優れたMLOpsとガバナンスの実践が適切な出発点となります(MLOpsとは、機械学習のライフサイクル管理における標準化と効率化です)。しかし、これは「何もしなくても得られるもの」ではありません。MLOpsもガバナンスも実践にあたっては、努力、規律、時間が必要になります。
ガバナンスやMLOpsの取り組みに対して責任を持つ人々は、さまざまなユーザープロファイル間の根本的な緊張関係を管理しなければなりません。つまり、効率的に業務を遂行することに加え、起こりうるあらゆる脅威からの保護との間でバランスを取る必要があるのです。このバランスを取るためには、各プロジェクト特有のリスクを評価し、そのリスクレベルに応じてガバナンスプロセスを適合させるという対応が有効になります。リスクを評価する際には、次のようないくつかの側面について考慮する必要があります:
- モデルのオーディエンス
- モデルとその成果物のライフサイクル
- 潜在するネガティブな結果がおよぼす影響
このような評価にあたっては、適用するガバナンス対策を決定するだけでなく、MLOpsの開発やデプロイメントツールのチェーン全体を推進および統括する必要があります。
ツールの活用もまた、AIにおける説明責任の確保に向けた対応のひとつです。例えば、次のようなものがあります:
- 従来の統計学的アプローチやサブ母集団分析は、データ中のバイアスを明らかにするうえでチームに貢献します。これは機械学習モデルが特定の成果指標に向け最適化されており、すべての評価指標について全母集団で一貫した性能を示すことは稀であるためです。
- 特徴量の重要度、公平性指標、または個々の予測に対する説明(特定の予測や結果に対して、どの要因がどのように影響したかを個人単位で可視化する能力)などに向けた各ツールも有効となります。
全体的な観点から見ると、データサイエンス、機械学習(ML)、AI、(Dataikuのような)責任あるAIプラットフォームは、これら多くの機能を提供するだけでなく、モデルの解釈性や透明性を確保する上でも大きく役立ちます。しかし ― ここが非常に重要なのですが ― 責任あるAIにおいて、ツールはすべてを解決する万能の手段ではありません。ツールは、あくまで企業内の人々によって定義されたプロセスや原則を効率的に実行するためのサポート手段にすぎません。
言い換えれば、モデルがなぜその判断を下したのかを尋ね、異なるデータでモデルがどう変化するかを監査し、組織の基準に適合しているかを確認するために適切な質問を行うのは、あくまで人間なのです。なぜなら最終的に公正性という概念は、文字どおり何十種類もの数学的定義に置き換えることが可能であり、それらは異なるだけでなく、ときに互いに両立しない場合さえあるからです。
一旦、公正性の定義を選択した後は、(このセクションで前述したように)バイアスを測定および軽減する責任あるAIツールを使用することが可能ですが、それでも最終的にどの定義が自社の価値観にもっとも適し、特定のユースケースに妥当かを判断するのは、組織自身の責任なのです。
俗説3:問題は悪意や無能によってのみ引き起こされる
近年、Google(英語)やAmazon(英語)をはじめとするほぼすべての大手テクノロジー企業で、責任あるAIに関連する問題が発生しています—しかも公開されている失敗例だけで、この状況となっているのです。これらの出来事は、次の2つの重要な教訓を示しています:
- Google、Apple、Meta、Amazonのように、技術的な専門知識や莫大な人員、さらに、ほぼ無限とも言えるようなリソースを持つ企業でも、このような事態が起こり得るのであれば、他のどのような組織も同様と考えられるでしょう。このような危機に耐える得る能力は、ほとんどの企業が備えていないため、責任あるAIへの投資が不可欠となるのです。
- こうした多くの注目を集めた(結果として組織が大きな評判の損失を被った)失敗は、悪意のあるスタッフや無能なスタッフによって引き起こされたわけではなく、むしろ機械学習プロジェクトのライフサイクルのさまざまな段階における、意図的な取り組みや説明責任の欠如によって生じたものです。
確かに、会社を危険にさらす根本的な問題を抱えたAIシステムを、意図せずに開発してしまったことによるリスクは複雑であり、偶発的に発生することもあります。しかしこれこそが、堅牢で責任あるAIシステムやプロセスの構築を非常に困難なものにしている理由のひとつなのです。
俗説4:責任あるAIは、AIの専門家だけの問題である
「責任あるAIの標準化を一人だけの責任にすべきではない」という考え方があります。そしてこれは、おそらく正しいでしょう。機械学習モデルの提供能力が拡大していく中で、組織全体のすべてのプロセスや意思決定を一人の人間が監視することは到底不可能だからです。一般的に、データサイエンス、機械学習、あるいはAIプロジェクトに関与する関係者の誰もが、全体を見渡す包括的な視点を持っているわけではありません。
- 根本的なビジネス課題、データ収集プロセス、そしてデータの限界を真に理解しているのは、ドメインの専門家だけです。
- データエンジニア、データサイエンティスト、機械学習エンジニアといったデータの専門家だけが、データサイエンスにおける技術的な側面を理解しています。
- 規制上、ビジネス上、あるいは評判に関するリスクが高まる状況において、最終的な判断を下す権限を持っているのは意思決定者だけです。
しかし同時に、責任あるAIは抽象的な概念から脱し、より具体的な形で数値化され、個人が責任を持って管理できるもの、人間の手によってコントロールされるものへと進化する必要があります。以下の表に記載した評価基準(ルーブリック)は、データワークフローの各構成要素 ― データそのもの、技術、そして生成されたモデル ― が、ガバナンス性、持続可能性、説明責任を確保するために、どのようにクロスチェックできるかを示しています。

責任あるAIは、組織にとって非常に複雑なテーマであるため、理論面(責任あるAIとは何か?それをどう実装すべきか?)と実践面(テクノロジーによって、どのように、そしてどの程度まで支援することができるのか?)の両面に加え、潜在的な影響や結果までも考慮する必要があります。このような考慮は、該当分野でリーダーを目指す組織が直面し、実施しなければならない事柄のほんの一部にすぎません。
責任あるAIには2つの見方があります:ムチ(罰則)なのか、アメ(インセンティブ)なのかという見方です。
1.ムチ(罰則):責任あるAIに関して、企業をリスクから守るためには何を導入する必要があるのか?
2.アメ(インセンティブ):責任あるAIの実践を通じて信頼を築き、AIが持つ企業変革力を受け入れるためにはどうすればよいのか?
現実的に成功を収めるためには、両方のアプローチ(ムチとアメ)に加え、データ実務者だけでなく経営陣を含む全員の協力が必要となります。また、責任あるAIは、あくまでAIの取り組みにおける”持続可能性”というより大きな課題の一部にすぎない点を、組織が認識することも重要です。
この中には、将来を見据えたインフラへの投資、現在または将来のデータプロジェクトを支えるための信頼性の高い継続的なデータアクセス、さらに本番環境で運用中のモデルを監視できる一元化された仕組みと、その維持管理に責任を持つ人材の配置が含まれます。
前向きな形で導入部を締めくくるために、責任あるAIは決して達成不可能な挑戦ではないということを認識しておきましょう。オープン性、社内での連携、そして段階的なフレームワークの構築を適切に組み合わせることで、AIの導入を拡大しながら、この課題に対して十分に取り組むことが可能です。つまり、責任あるAIに対する正当な関心の高まりが、企業全体のプロセスにAIを広く組み込むという必要不可欠な取り組みの妨げにならないようにすることが重要なのです(もちろんDataikuは、喜んでその支援を行います!)。
ここまで、責任あるAIに関する4つの主要な原則を定義してきましたが、次はこの概念がどれほど強力で、その導入が貴社にとってどのような意味を持つのかを、詳しく見ていきましょう。
責任あるデータパイプラインの構築
責任あるAIの実践が、組織にとって重要となるのはなぜでしょうか?AIの失敗が予期せぬ潜在的な問題となる結果を生み出し、ニュースで取り上げられたとしても、それは特定のユースケースや業界に限ったことではありません。
AIを活用している方々であれば、すでにこの問題について認識しているかと思いますが、AIの活用において善意だけでは十分ではありません。実際には、ほとんどの組織がAIの失敗による悪影響を予期したり、意図したりしているわけではありません。有害な結果は、組織の意図や価値観を反映したものではありませんが、それでもAIによるこのような意図しない結果は、日々どこかで確実に発生しています。では、私たちは何ができるのでしょうか?
責任あるAIフレームワークによってAIの失敗を軽減
AIの失敗に関連する問題に前もって対処するために、組織は責任あるAIのためのフレームワークを適用する必要があります。このようなフレームワークは、AIに関する責任を持った実践に必要となるプロセス構築の指針となります。
責任あるAIのフレームワークに不可欠となる主要な概念としては、主に次の3つがあります:
- 公平性
- 説明責任
- 透明性/説明可能性
これらの概念は、AIパイプラインの品質を評価するための出発点となり、組織の価値観や原則に対応する重要な質問が、それぞれの主要な概念と結び付けられます。これらの質問について検討することで、組織はAIを責任ある視点から捉え、内部的な観点とビジネスユーザーの観点の両面から統合を開始することができます。
- 公平性:「AIシステムは、私たちの考える公平性の概念に沿った形で成果を配分しているか?」
- 説明責任:「構築および展開のプロセスにおける各決定に対して責任を持つのは誰なのか?」
- 透明性:「事業とその関係者にとって、透明性はどの程度必要か?またどのように提供されるのか?
AIパイプラインには、アルゴリズムだけでなく、問題の定義から、ソリューションの設計、構築、そしてソリューションの監視まで、さまざまなステップが含まれています。責任あるAIフレームワークを真に理解するためには、機械学習ライフサイクルの中でも、とくに構築の部分に注目する必要があります。この工程では、実務担当者がデータやモデルを探索して実験し、本番環境のパイプラインに組み込む準備を進めます。こちらのウェビナーをご覧いただき(英語)、生成AIにおける責任あるAIの詳細について学んでください!
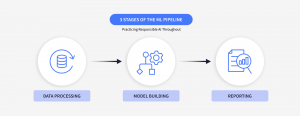
構築工程について理解する
構築工程では、責任あるAIフレームワークを適用することが可能な、機械学習パイプラインの3つのフェーズがあります:
- データ処理
- モデル構築
- レポート作成
データ処理における責任あるAI
データは世界を映し出すものであるため、さまざまな形でバイアスが含まれているのは当然です。そして、データ内のバイアス(英語)について説明できることが重要となります。バイアスが含まれたデータは、不適切な収集手法によってデータに偏りが生じた場合もあれば、人間の入力が社会的バイアスを助長する形でデータに反映されている場合もあります。これは、一見明らかではないものの、どちらの場合も対処が必要なセンシティブな相関関係が存在していることを意味します。さらに、多くのデータセットには、代理変数(プロキシ変数)が存在する危険性もあります。
実務担当者は、バイアスを適切に特定して対処することで、その影響を軽減することができます。上記のような方法で広がったバイアスを検出するために、実務担当者は伝統的な統計手法を用いてバイアスや相関関係を測定したり、データの収集方法や出所について徹底的に評価することができます。リスクの高いデータセットについて、ドメイン専門家に詳細な検証を依頼することもまた重要なステップのひとつです。
モデル構築の工程
データのバイアスを考慮した上で、次に進むべきはモデル構築の工程であり、ここではモデルの公平性を測定(英語)することが重要となります。公平性をモデル化する場合には、数学的要素と社会的志向的要素の両面があります。数学的に公平性が高いモデルとは、その公平な予測がセンシティブな属性(性別や人種など)に依存しない場合に実現されます。社会的な観点からの公平性に目を向けると、公平なモデルとは、異なるグループ間で一貫したパフォーマンスを示し、その結果が意図された目的と一致しているようなモデルのことを指します。なぜこれが重要なのでしょうか?
いくつかの研究では、バイアスのあるデータが偏りのあるモデルを生み出してしまった例として、有色人種の人々が白人よりも症状が重いにもかかわらず、医師から追加のケアを必要とする対象と判断されにくくなっている実態が明らかになっています。医療システムで使用されるモデルは、標準的な機械学習の指標において良好な性能を示していても、既存の差別を強化してしまうことがよくあります — 医療業界におけるバイアスの例については、こちらでご確認ください。(英語)
責任あるAIの視点でモデルを検討する
実践における責任あるAIでは、モデルの公平性の種類に関する幅広い知識が求められます。
- 例えば、グループの公平性というものがあります。これは、モデルが主要な指標において各グループ間で同等に機能することを意味します。
- また個人の公平性というものもあります。これは類似する個人が同等の扱いを受ける確率が高いことを指します。
- センシティブな属性を変更しても予測は変わらないという、事実に反する公平性についても忘れてはなりません。
責任あるAIフレームワークでは、これら公平性の3つのタイプすべてを測定する必要があります。
共有方法は、モデル構築の方法と同様に重要となる
モデルに関するレポートには、いくつかの共通した課題があります。ビジネスユーザーや消費者は、アルゴリズムや内部の仕組みを監査および追跡することが難しいブラックボックス型のAIシステム(英語)に対して、とくに大きな警戒心を抱いています。ドキュメント不足もまた大きな問題です。モデルの入力に関する適切なガイドや理解がなければ、公平なAIであっても誤った形で使用される可能性があります!
これらの課題を乗り越え始めるために、透明性のあるレポートがモデルの背景や個々の予測内容について説明します。また、エンドユーザーが異なるモデルの実行結果を検証し、具体的な対処策を見出せるような機会を提供します。データおよびモデル構築パイプラインの各段階を文書化することで、問題が発生した際、容易に確認して修正することが可能となります。
視野を広げて検討する:AIガバナンス
ここまで責任あるAIの実践がモデル構築をどのように改善できるかについて見てきましたが、これらの実践はAIパイプラインの他の工程から切り離されているわけではありません。責任あるAIのフレームワークは、より広範なAIガバナンスの基盤に根ざしている必要があります。
すでに言及したように、AIパイプラインは単なるアルゴリズム以上のものです。問題定義からモデルの監視まで、分析機能およびAIを安全に拡大するためには、AIモデルのコントロールと俊敏性の間でバランスを取る必要があります。では、AIガバナンス、MLOps、そして責任あるAIの関係とは、具体的にどのようなものなのでしょうか?
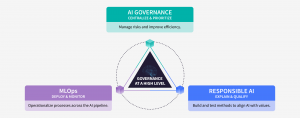
組織はAIの失敗による意図しない有害な結果を回避し、ビジネスプロセス全体にわたってAIを効果的に拡張するために、慎重に設計されたフレームワークを通じて、開発から導入まで一貫して責任ある価値観と原則を取り入れる必要があります。
ここまで私たちは、責任あるAIを定義し、それがAIガバナンスとどのように関連しているかについて見てきました。次に、Dataikuのような企業との提携が、堅牢なモデルの構築だけでなく、責任あるAIの原則を考慮した手法によるモデル設計にどのように貢献するかを見ていきましょう。
生成AIにおける責任あるAI
生成AIは大きなメリットをもたらしますが、同時にAIによるハルシネーションのような課題も引き起こすため、責任ある展開手法が求められるのです。
AIハルシネーションからの防御策
生成AIモデルにおける主なリスクのひとつは、ハルシネーション(一見もっともらしく思えるものの、実際には事実と異なっていたり、誤解を招いたり、完全に作り上げられた内容である出力)を引き起こす可能性があることです。この問題は、リアルタイムのデータや検証された事実に基づくことなく、学習したパターンに基づいて応答を生成する、これらのモデルの確率的な性質に起因します。例えばモデルは、もっともらしい架空の引用を”作り出したり”、誤った人物に引用を帰属させたり、現実の出来事に関する虚偽の情報を生成したりすることがあります。何気ない会話においてはとくに害にならないかもしれませんが、医療や法律、ジャーナリズムなど、事実の正確さが重要となるハイリスクな分野では、その影響がより深刻なものとなります。
責任あるAIの実現に向けた人間の関与(Human-in-the-Loop)アプローチの採用
エラーの可能性を考えると、責任を持って生成AIを活用するためには、人間が介在するアプローチを採用することが極めて重要となります。人が監督することによって、AIからの出力は実際に使用される前に評価され、必要に応じて修正されることでその品質が保証されます。例えば、生成AIを活用した医療診断システムでは、ハルシネーションが誤診や不適切な治療につながらないよう、人間の専門家がAIによる提案を必ず検証する必要があります。
責任あるAIシステムの構築
開発者や組織は、ハルシネーションにともなうリスクを軽減し、生成モデルを安全に活用するために、責任あるAIの実践を最優先にすべきなのです。これには次の内容が含まれます:
- 透明度:AIシステムが使用されていることや、人間による監督が行われていることを明確に示すこと。
- トレーニングおよび検証:高品質で多様なトレーニングデータを使用し、バイアスや誤りを最小限に抑えつつ、システムの精度を継続的にテストすること。
- 後処理による安全対策:公開前に人間のレビューアーがAIによる生成コンテンツの正確性や適切性を評価できる検証工程を導入すること。
より詳細な内容へ
Dataiku Generative AI Bootcamp: Introducing Dataiku's RAFT Framework
Dataikuによる責任あるAI
責任あるAIとは、AIの出力内容が組織の価値観と一致することを保証するためのフレームワークであることを忘れないようにしましょう。Dataikuのようなプラットフォームと連携することで、信頼性が高く、説明責任を果たし、公平で透明性があり、説明可能な(英語)AIシステムを構築することができます。そして、これらはすべて責任あるAIの主要な原則となります。
以下で、Dataikuの責任あるAIソリューションが提供する主な機能の一部を紹介します。
バイアスを事前に軽減する
バイアスのある機械学習モデルによるリスクを軽減するために、適切なデータ準備手法が全工程で適用されていることを保証できます。これにより、機械学習モデルの構築において堅固な基盤が実現されます。Dataikuが提供するツールは、高度な統計分析、強化されたデータ検出機能、データ品質のルール、GDPRやCCPAのような主要な規制に従ってデータプライバシーを保護するためのガードレールといった、責任あるAIの原則を推進します。
モデルの精度を向上させる
とくに大規模な運用においては、モデルの公平性を確保することが非常に困難になる場合があります。Dataikuの提供機能を活用して、責任あるAIプロセスの精度を向上させることで、モデルアサーション(英語)やサブ母集団分析(英語)を通じて、特定の集団に対する予測が期待された基準を満たしているかどうかを確認することが可能となります。さらに、新しいモデルバージョンが期待どおりに動作しない場合には、警告が表示されます。モデルトレーニング時の整合性チェック(Sanity check)は、データセット内の不均衡や変数重要度に関する変動の特定に役立ちます。
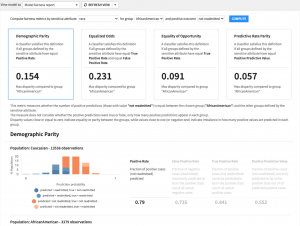
専門特化されたレポートにより問題を検出
公平性レポートを使用することで、モデル内のバイアスを測定するための指標を選択することができます。これらのレポートには、人口統計学的パリティ、平等化オッズ、機会の平等、予測率パリティなどが含まれます。部分依存プロットやサブ母集団分析は、予測内容がグローバルレベルおよび地域(特定集団)レベルでどのように変化するかを理解する際に役立ちます。
ビルドのドキュメント化と可視化
What-if分析や個別予測による説明を活用することで、モデルの現状を担当チームが把握し、なぜ特定の予測が生成されているのかを明らかにすることができます。さらに、インタラクティブな分析内容を公開することで、ビジネスユーザーがモデルの挙動をより深く理解できるようになります。担当チームは、モデルの評価と監視機能を活用して主要なモデル指標を算出し、特定のモデルエラーが発生した際に通知を受け取ることができます。モデルが何を行うか、どのように構築およびチューニングされ、どのような性能を示したかを含むドキュメントを自動的に生成することも可能です。これは、規制遵守に不可欠であるだけでなく、AIソリューションを維持および運用するチームにとって、継続的なナレッジマネジメントの観点からも非常に重要です。
責任あるAIとAIガバナンスの連携
Dataiku Governを活用することで、分析チームやAIチームのスピードを損なうことなく、適切なチェック体制とバランスの取れた管理を実現することができます。ガバナンスチームには、具体的かつ測定可能な形にする必要がある基準が存在します。Dataiku Governを活用することで、分析チームやAIチームは、その期待に沿った形で作業を行うことができます。また、担当チームは分析およびAIプロジェクトの開発と展開に向けた標準的なプロジェクト計画を作成し、レビューと承認のための明確なステップとゲートを備えたワークフローブループリントを活用することができます。
すべてのプロジェクトを一元管理する
モデルやアナリティクスプロジェクトを含むDataikuの中央レジストリを活用し、パフォーマンス指標とともにすべてバージョンを一元管理することで、プロジェクトの可視性を高めることができます。リーダーやプロジェクトマネージャー向けにプロジェクトの概要が提供されます。また、モデルの展開前に承認を得ることで、確実な形で展開に関する意思決定の監査準備を行うことができます。責任あるAIは、AIガバナンスやMLOpsと連携して、安全にAIを拡大するための支援における一要素です。機械学習の開発ライフサイクルにおけるアクティビティとチェック内容をガバナンスチームと共有することで、原則への遵守を確実に実現することができます。
Dataikuによる専門サポートを受ける
責任あるAIの技術的な側面を超えて、Dataikuの専門家が貴社のニーズに合わせた改善点や機会の特定を支援します。これにより、Dataikuのコア製品が提供する技術的な特徴に加え、責任あるAIについて、概要から実践的なレベルまで学習することができます。
責任あるAIへの一歩を踏み出す
ここまで見てきたように、責任あるAIは単にAI技術の急速な発展に不可欠な取り組みであるだけでなく、信頼構築や効果的な拡張、さらに目的意識を持って他社をリードしようと考える組織や業界にとって、強力な戦略的優位性でもあります。
明確な”責任あるAI”戦略を持たない企業は、多くのリスクに直面する可能性があります。ここには、消費者の信頼低下や従業員の自信喪失、罰金、監査や精査の増加、そして責任の不明確さなどが含まれます。そしてこれらすべてが、AIの機能不全につながる可能性があります。
公正性、説明責任、透明性をAIの設計および導入プロセスに統合することで、企業はリスクを軽減し、システムの信頼性を高め、社内外のステークホルダーに対してより公平な成果を提供することができるようになります。
責任あるAIでは、AIや機械学習における他の多くの分野と同様に、チームや専門分野を超えた協力が求められます。そしてその実現には、Dataikuのような優れたフレームワークやツールに基づく取り組みが不可欠なのです。